 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Robustness of Monocular Depth Estimation with Procedural Scene Perturbations
Jul 01, 2025Recent years have witnessed substantial progress on monocular depth estimation, particularly as measured by the success of large models on standard benchmarks. However, performance on standard benchmarks does not offer a complete assessment, because most evaluate accuracy but not robustness. In this work, we introduce PDE (Procedural Depth Evaluation), a new benchmark which enables systematic robustness evaluation. PDE uses procedural generation to create 3D scenes that test robustness to various controlled perturbations, including object, camera, material and lighting changes. Our analysis yields interesting findings on what perturbations are challenging for state-of-the-art depth models, which we hope will inform further research. Code and data are available at https://github.com/princeton-vl/proc-depth-eval.
Infinigen-Sim: Procedural Generation of Articulated Simulation Assets
May 19, 2025



We introduce Infinigen-Sim, a toolkit which enables users to create diverse and realistic articulated object procedural generators. These tools are composed of high-level utilities for use creating articulated assets in Blender, as well as an export pipeline to integrate the resulting assets into common robotics simulators. We demonstrate our system by creating procedural generators for 5 common articulated object categories. Experiments show that assets sampled from these generators are useful for movable object segmentation, training generalizable reinforcement learning policies, and sim-to-real transfer of imitation learning policies.
Zero-shot Sim2Real Transfer for Magnet-Based Tactile Sensor on Insertion Tasks
May 05, 2025



Tactile sensing is an important sensing modality for robot manipulation. Among different types of tactile sensors, magnet-based sensors, like u-skin, balance well between high durability and tactile density. However, the large sim-to-real gap of tactile sensors prevents robots from acquiring useful tactile-based manipulation skills from simulation data, a recipe that has been successful for achieving complex and sophisticated control policies. Prior work has implemented binarization techniques to bridge the sim-to-real gap for dexterous in-hand manipulation. However, binarization inherently loses much information that is useful in many other tasks, e.g., insertion. In our work, we propose GCS, a novel sim-to-real technique to learn contact-rich skills with dense, distributed, 3-axis tactile readings. We evaluate our approach on blind insertion tasks and show zero-shot sim-to-real transfer of RL policies with raw tactile reading as input.
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Jun 04, 2024Recent advancements in Artificial Intelligence (AI) have largely been propelled by scaling. In Robotics, scaling is hindered by the lack of access to massive robot datasets. We advocate using realistic physical simulation as a means to scale environments, tasks, and datasets for robot learning methods. We present RoboCasa, a large-scale simulation framework for training generalist robots in everyday environments. RoboCasa features realistic and diverse scenes focusing on kitchen environments. We provide thousands of 3D assets across over 150 object categories and dozens of interactable furniture and appliances. We enrich the realism and diversity of our simulation with generative AI tools, such as object assets from text-to-3D models and environment textures from text-to-image models. We design a set of 100 tasks for systematic evaluation, including composite tasks generated by the guidance of large language models. To facilitate learning, we provide high-quality human demonstrations and integrate automated trajectory generation methods to substantially enlarge our datasets with minimal human burden. Our experiments show a clear scaling trend in using synthetically generated robot data for large-scale imitation learning and show great promise in harnessing simulation data in real-world tasks. Videos and open-source code are available at https://robocasa.ai/
Enhancing Classification with Hierarchical Scalable Query on Fusion Transformer
Feb 28, 2023Real-world vision based applications require fine-grained classification for various area of interest like e-commerce, mobile applications, warehouse management, etc. where reducing the severity of mistakes and improving the classification accuracy is of utmost importance. This paper proposes a method to boost fine-grained classification through a hierarchical approach via learnable independent query embeddings. This is achieved through a classification network that uses coarse class predictions to improve the fine class accuracy in a stage-wise sequential manner. We exploit the idea of hierarchy to learn query embeddings that are scalable across all levels, thus making this a relevant approach even for extreme classification where we have a large number of classes. The query is initialized with a weighted Eigen image calculated from training samples to best represent and capture the variance of the object. We introduce transformer blocks to fuse intermediate layers at which query attention happens to enhance the spatial representation of feature maps at different scales. This multi-scale fusion helps improve the accuracy of small-size objects. We propose a two-fold approach for the unique representation of learnable queries. First, at each hierarchical level, we leverage cluster based loss that ensures maximum separation between inter-class query embeddings and helps learn a better (query) representation in higher dimensional spaces. Second, we fuse coarse level queries with finer level queries weighted by a learned scale factor. We additionally introduce a novel block called Cross Attention on Multi-level queries with Prior (CAMP) Block that helps reduce error propagation from coarse level to finer level, which is a common problem in all hierarchical classifiers. Our method is able to outperform the existing methods with an improvement of ~11% at the fine-grained classification.
* 6 pages, 7 figures Published in IEEE ICCE 2023
Robust Perception through Equivariance
Dec 12, 2022Deep networks for computer vision are not reliable when they encounter adversarial examples. In this paper, we introduce a framework that uses the dense intrinsic constraints in natural images to robustify inference. By introducing constraints at inference time, we can shift the burden of robustness from training to the inference algorithm, thereby allowing the model to adjust dynamically to each individual image's unique and potentially novel characteristics at inference time. Among different constraints, we find that equivariance-based constraints are most effective, because they allow dense constraints in the feature space without overly constraining the representation at a fine-grained level. Our theoretical results validate the importance of having such dense constraints at inference time. Our empirical experiments show that restoring feature equivariance at inference time defends against worst-case adversarial perturbations. The method obtains improved adversarial robustness on four datasets (ImageNet, Cityscapes, PASCAL VOC, and MS-COCO) on image recognition, semantic segmentation, and instance segmentation tasks. Project page is available at equi4robust.cs.columbia.edu.
VIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors
Oct 20, 2022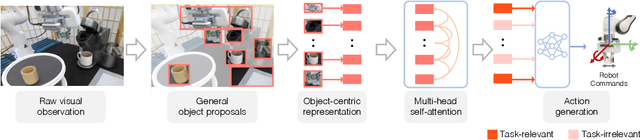
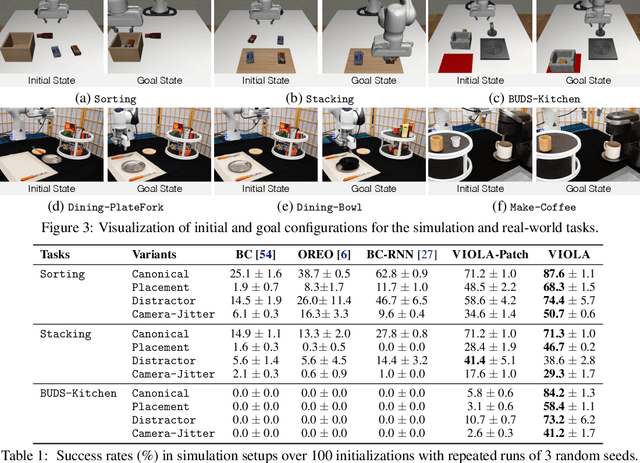

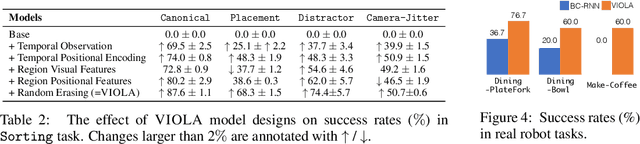
We introduce VIOLA, an object-centric imitation learning approach to learning closed-loop visuomotor policies for robot manipulation. Our approach constructs object-centric representations based on general object proposals from a pre-trained vision model. VIOLA uses a transformer-based policy to reason over these representations and attend to the task-relevant visual factors for action prediction. Such object-based structural priors improve deep imitation learning algorithm's robustness against object variations and environmental perturbations. We quantitatively evaluate VIOLA in simulation and on real robots. VIOLA outperforms the state-of-the-art imitation learning methods by $45.8\%$ in success rate. It has also been deployed successfully on a physical robot to solve challenging long-horizon tasks, such as dining table arrangement and coffee making. More videos and model details can be found in supplementary material and the project website: https://ut-austin-rpl.github.io/VIOLA .
Semantic Driven Energy based Out-of-Distribution Detection
Aug 23, 2022



Detecting Out-of-Distribution (OOD) samples in real world visual applications like classification or object detection has become a necessary precondition in today's deployment of Deep Learning systems. Many techniques have been proposed, of which Energy based OOD methods have proved to be promising and achieved impressive performance. We propose semantic driven energy based method, which is an end-to-end trainable system and easy to optimize. We distinguish in-distribution samples from out-distribution samples with an energy score coupled with a representation score. We achieve it by minimizing the energy for in-distribution samples and simultaneously learn respective class representations that are closer and maximizing energy for out-distribution samples and pushing their representation further out from known class representation. Moreover, we propose a novel loss function which we call Cluster Focal Loss(CFL) that proved to be simple yet very effective in learning better class wise cluster center representations. We find that, our novel approach enhances outlier detection and achieve state-of-the-art as an energy-based model on common benchmarks. On CIFAR-10 and CIFAR-100 trained WideResNet, our model significantly reduces the relative average False Positive Rate(at True Positive Rate of 95%) by 67.2% and 57.4% respectively, compared to the existing energy based approaches. Further, we extend our framework for object detection and achieve improved performance.
SHAD3S: A model to Sketch, Shade and Shadow
Nov 19, 2020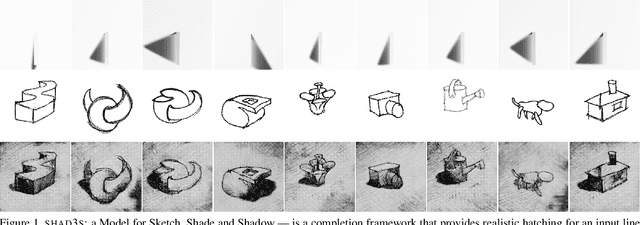



Hatching is a common method used by artists to accentuate the third dimension of a sketch, and to illuminate the scene. Our system SHAD3S attempts to compete with a human at hatching generic three-dimensional (3D) shapes, and also tries to assist her in a form exploration exercise. The novelty of our approach lies in the fact that we make no assumptions about the input other than that it represents a 3D shape, and yet, given a contextual information of illumination and texture, we synthesise an accurate hatch pattern over the sketch, without access to 3D or pseudo 3D. In the process, we contribute towards a) a cheap yet effective method to synthesise a sufficiently large high fidelity dataset, pertinent to task; b) creating a pipeline with conditional generative adversarial network (CGAN); and c) creating an interactive utility with GIMP, that is a tool for artists to engage with automated hatching or a form-exploration exercise. User evaluation of the tool suggests that the model performance does generalise satisfactorily over diverse input, both in terms of style as well as shape. A simple comparison of inception scores suggest that the generated distribution is as diverse as the ground truth.
Unsupervised Synthesis of Anomalies in Videos: Transforming the Normal
Apr 14, 2019



Abnormal activity recognition requires detection of occurrence of anomalous events that suffer from a severe imbalance in data. In a video, normal is used to describe activities that conform to usual events while the irregular events which do not conform to the normal are referred to as abnormal. It is far more common to observe normal data than to obtain abnormal data in visual surveillance. In this paper, we propose an approach where we can obtain abnormal data by transforming normal data. This is a challenging task that is solved through a multi-stage pipeline approach. We utilize a number of techniques from unsupervised segmentation in order to synthesize new samples of data that are transformed from an existing set of normal examples. Further, this synthesis approach has useful applications as a data augmentation technique. An incrementally trained Bayesian convolutional neural network (CNN) is used to carefully select the set of abnormal samples that can be added. Finally through this synthesis approach we obtain a comparable set of abnormal samples that can be used for training the CNN for the classification of normal vs abnormal samples. We show that this method generalizes to multiple settings by evaluating it on two real world datasets and achieves improved performance over other probabilistic techniques that have been used in the past for this task.