 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors
Paper and Code
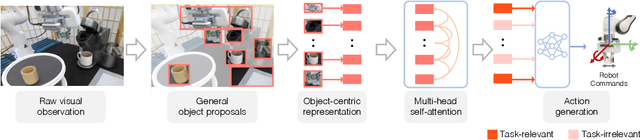
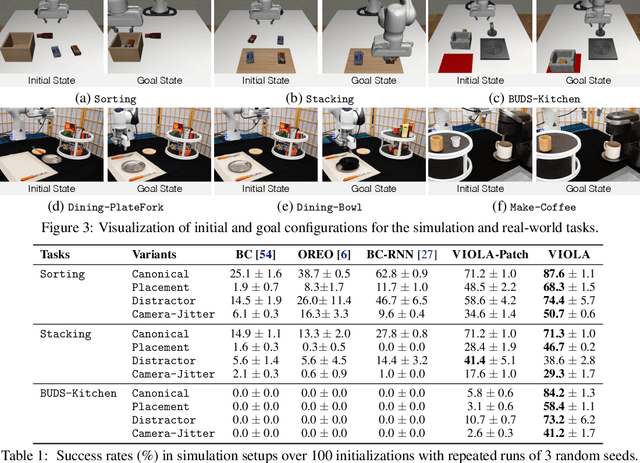

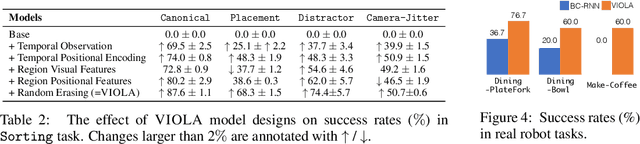
We introduce VIOLA, an object-centric imitation learning approach to learning closed-loop visuomotor policies for robot manipulation. Our approach constructs object-centric representations based on general object proposals from a pre-trained vision model. VIOLA uses a transformer-based policy to reason over these representations and attend to the task-relevant visual factors for action prediction. Such object-based structural priors improve deep imitation learning algorithm's robustness against object variations and environmental perturbations. We quantitatively evaluate VIOLA in simulation and on real robots. VIOLA outperforms the state-of-the-art imitation learning methods by $45.8\%$ in success rate. It has also been deployed successfully on a physical robot to solve challenging long-horizon tasks, such as dining table arrangement and coffee making. More videos and model details can be found in supplementary material and the project website: https://ut-austin-rpl.github.io/VIOLA .