 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionAdapter: Video Motion Transfer via Content-Aware Attention Customization
Jan 05, 2026Recent advances in diffusion-based text-to-video models, particularly those built on the diffusion transformer architecture, have achieved remarkable progress in generating high-quality and temporally coherent videos. However, transferring complex motions between videos remains challenging. In this work, we present MotionAdapter, a content-aware motion transfer framework that enables robust and semantically aligned motion transfer within DiT-based T2V models. Our key insight is that effective motion transfer requires \romannumeral1) explicit disentanglement of motion from appearance and \romannumeral 2) adaptive customization of motion to target content. MotionAdapter first isolates motion by analyzing cross-frame attention within 3D full-attention modules to extract attention-derived motion fields. To bridge the semantic gap between reference and target videos, we further introduce a DINO-guided motion customization module that rearranges and refines motion fields based on content correspondences. The customized motion field is then used to guide the DiT denoising process, ensuring that the synthesized video inherits the reference motion while preserving target appearance and semantics. Extensive experiments demonstrate that MotionAdapter outperforms state-of-the-art methods in both qualitative and quantitative evaluations. Moreover, MotionAdapter naturally supports complex motion transfer and motion editing tasks such as zooming.
LLM-GROP: Visually Grounded Robot Task and Motion Planning with Large Language Models
Nov 11, 2025Task planning and motion planning are two of the most important problems in robotics, where task planning methods help robots achieve high-level goals and motion planning methods maintain low-level feasibility. Task and motion planning (TAMP) methods interleave the two processes of task planning and motion planning to ensure goal achievement and motion feasibility. Within the TAMP context, we are concerned with the mobile manipulation (MoMa) of multiple objects, where it is necessary to interleave actions for navigation and manipulation. In particular, we aim to compute where and how each object should be placed given underspecified goals, such as ``set up dinner table with a fork, knife and plate.'' We leverage the rich common sense knowledge from large language models (LLMs), e.g., about how tableware is organized, to facilitate both task-level and motion-level planning. In addition, we use computer vision methods to learn a strategy for selecting base positions to facilitate MoMa behaviors, where the base position corresponds to the robot's ``footprint'' and orientation in its operating space. Altogether, this article provides a principled TAMP framework for MoMa tasks that accounts for common sense about object rearrangement and is adaptive to novel situations that include many objects that need to be moved. We performed quantitative experiments in both real-world settings and simulated environments. We evaluated the success rate and efficiency in completing long-horizon object rearrangement tasks. While the robot completed 84.4\% real-world object rearrangement trials, subjective human evaluations indicated that the robot's performance is still lower than experienced human waiters.
SocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
Sep 10, 2025Robot navigation in dynamic, human-centered environments requires socially-compliant decisions grounded in robust scene understanding. Recent Vision-Language Models (VLMs) exhibit promising capabilities such as object recognition, common-sense reasoning, and contextual understanding-capabilities that align with the nuanced requirements of social robot navigation. However, it remains unclear whether VLMs can accurately understand complex social navigation scenes (e.g., inferring the spatial-temporal relations among agents and human intentions), which is essential for safe and socially compliant robot navigation. While some recent works have explored the use of VLMs in social robot navigation, no existing work systematically evaluates their ability to meet these necessary conditions. In this paper, we introduce the Social Navigation Scene Understanding Benchmark (SocialNav-SUB), a Visual Question Answering (VQA) dataset and benchmark designed to evaluate VLMs for scene understanding in real-world social robot navigation scenarios. SocialNav-SUB provides a unified framework for evaluating VLMs against human and rule-based baselines across VQA tasks requiring spatial, spatiotemporal, and social reasoning in social robot navigation. Through experiments with state-of-the-art VLMs, we find that while the best-performing VLM achieves an encouraging probability of agreeing with human answers, it still underperforms simpler rule-based approach and human consensus baselines, indicating critical gaps in social scene understanding of current VLMs. Our benchmark sets the stage for further research on foundation models for social robot navigation, offering a framework to explore how VLMs can be tailored to meet real-world social robot navigation needs. An overview of this paper along with the code and data can be found at https://larg.github.io/socialnav-sub .
LodeStar: Long-horizon Dexterity via Synthetic Data Augmentation from Human Demonstrations
Aug 24, 2025Developing robotic systems capable of robustly executing long-horizon manipulation tasks with human-level dexterity is challenging, as such tasks require both physical dexterity and seamless sequencing of manipulation skills while robustly handling environment variations. While imitation learning offers a promising approach, acquiring comprehensive datasets is resource-intensive. In this work, we propose a learning framework and system LodeStar that automatically decomposes task demonstrations into semantically meaningful skills using off-the-shelf foundation models, and generates diverse synthetic demonstration datasets from a few human demos through reinforcement learning. These sim-augmented datasets enable robust skill training, with a Skill Routing Transformer (SRT) policy effectively chaining the learned skills together to execute complex long-horizon manipulation tasks. Experimental evaluations on three challenging real-world long-horizon dexterous manipulation tasks demonstrate that our approach significantly improves task performance and robustness compared to previous baselines. Videos are available at lodestar-robot.github.io.
Efficient Sensorimotor Learning for Open-world Robot Manipulation
May 07, 2025



This dissertation considers Open-world Robot Manipulation, a manipulation problem where a robot must generalize or quickly adapt to new objects, scenes, or tasks for which it has not been pre-programmed or pre-trained. This dissertation tackles the problem using a methodology of efficient sensorimotor learning. The key to enabling efficient sensorimotor learning lies in leveraging regular patterns that exist in limited amounts of demonstration data. These patterns, referred to as ``regularity,'' enable the data-efficient learning of generalizable manipulation skills. This dissertation offers a new perspective on formulating manipulation problems through the lens of regularity. Building upon this notion, we introduce three major contributions. First, we introduce methods that endow robots with object-centric priors, allowing them to learn generalizable, closed-loop sensorimotor policies from a small number of teleoperation demonstrations. Second, we introduce methods that constitute robots' spatial understanding, unlocking their ability to imitate manipulation skills from in-the-wild video observations. Last but not least, we introduce methods that enable robots to identify reusable skills from their past experiences, resulting in systems that can continually imitate multiple tasks in a sequential manner. Altogether, the contributions of this dissertation help lay the groundwork for building general-purpose personal robots that can quickly adapt to new situations or tasks with low-cost data collection and interact easily with humans. By enabling robots to learn and generalize from limited data, this dissertation takes a step toward realizing the vision of intelligent robotic assistants that can be seamlessly integrated into everyday scenarios.
Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
Oct 16, 2024Humanoid robots, with their human-like embodiment, have the potential to integrate seamlessly into human environments. Critical to their coexistence and cooperation with humans is the ability to understand natural language communications and exhibit human-like behaviors. This work focuses on generating diverse whole-body motions for humanoid robots from language descriptions. We leverage human motion priors from extensive human motion datasets to initialize humanoid motions and employ the commonsense reasoning capabilities of Vision Language Models (VLMs) to edit and refine these motions. Our approach demonstrates the capability to produce natural, expressive, and text-aligned humanoid motions, validated through both simulated and real-world experiments. More videos can be found at https://ut-austin-rpl.github.io/Harmon/.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Oct 15, 2024



We study the problem of teaching humanoid robots manipulation skills by imitating from single video demonstrations. We introduce OKAMI, a method that generates a manipulation plan from a single RGB-D video and derives a policy for execution. At the heart of our approach is object-aware retargeting, which enables the humanoid robot to mimic the human motions in an RGB-D video while adjusting to different object locations during deployment. OKAMI uses open-world vision models to identify task-relevant objects and retarget the body motions and hand poses separately. Our experiments show that OKAMI achieves strong generalizations across varying visual and spatial conditions, outperforming the state-of-the-art baseline on open-world imitation from observation. Furthermore, OKAMI rollout trajectories are leveraged to train closed-loop visuomotor policies, which achieve an average success rate of 79.2% without the need for labor-intensive teleoperation. More videos can be found on our website https://ut-austin-rpl.github.io/OKAMI/.
BUMBLE: Unifying Reasoning and Acting with Vision-Language Models for Building-wide Mobile Manipulation
Oct 08, 2024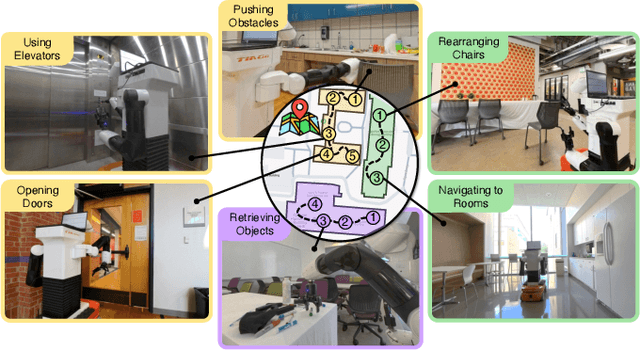



To operate at a building scale, service robots must perform very long-horizon mobile manipulation tasks by navigating to different rooms, accessing different floors, and interacting with a wide and unseen range of everyday objects. We refer to these tasks as Building-wide Mobile Manipulation. To tackle these inherently long-horizon tasks, we introduce BUMBLE, a unified Vision-Language Model (VLM)-based framework integrating open-world RGBD perception, a wide spectrum of gross-to-fine motor skills, and dual-layered memory. Our extensive evaluation (90+ hours) indicates that BUMBLE outperforms multiple baselines in long-horizon building-wide tasks that require sequencing up to 12 ground truth skills spanning 15 minutes per trial. BUMBLE achieves 47.1% success rate averaged over 70 trials in different buildings, tasks, and scene layouts from different starting rooms and floors. Our user study demonstrates 22% higher satisfaction with our method than state-of-the-art mobile manipulation methods. Finally, we demonstrate the potential of using increasingly-capable foundation models to push performance further. For more information, see https://robin-lab.cs.utexas.edu/BUMBLE/
InterPreT: Interactive Predicate Learning from Language Feedback for Generalizable Task Planning
May 30, 2024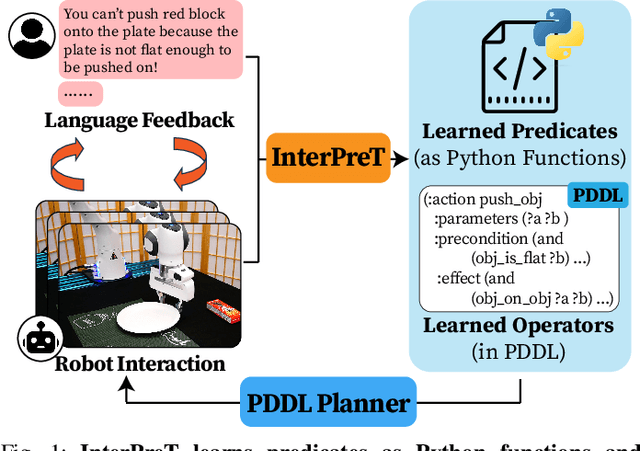
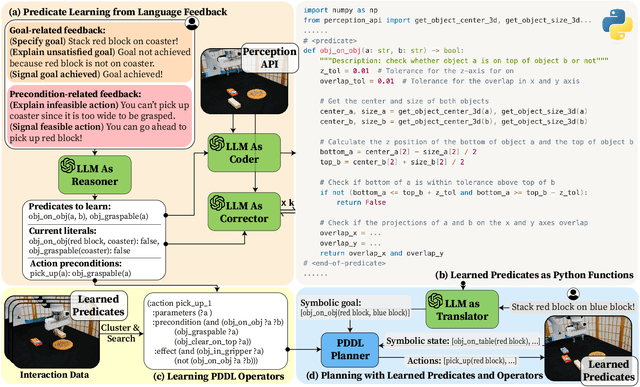
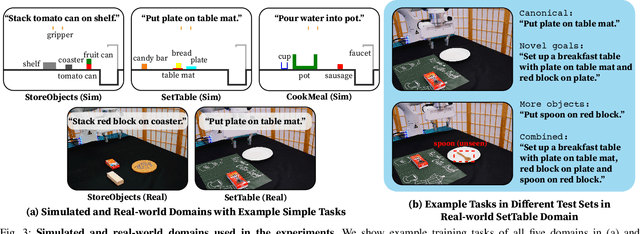

Learning abstract state representations and knowledge is crucial for long-horizon robot planning. We present InterPreT, an LLM-powered framework for robots to learn symbolic predicates from language feedback of human non-experts during embodied interaction. The learned predicates provide relational abstractions of the environment state, facilitating the learning of symbolic operators that capture action preconditions and effects. By compiling the learned predicates and operators into a PDDL domain on-the-fly, InterPreT allows effective planning toward arbitrary in-domain goals using a PDDL planner. In both simulated and real-world robot manipulation domains, we demonstrate that InterPreT reliably uncovers the key predicates and operators governing the environment dynamics. Although learned from simple training tasks, these predicates and operators exhibit strong generalization to novel tasks with significantly higher complexity. In the most challenging generalization setting, InterPreT attains success rates of 73% in simulation and 40% in the real world, substantially outperforming baseline methods.
Vision-based Manipulation from Single Human Video with Open-World Object Graphs
May 30, 2024We present an object-centric approach to empower robots to learn vision-based manipulation skills from human videos. We investigate the problem of imitating robot manipulation from a single human video in the open-world setting, where a robot must learn to manipulate novel objects from one video demonstration. We introduce ORION, an algorithm that tackles the problem by extracting an object-centric manipulation plan from a single RGB-D video and deriving a policy that conditions on the extracted plan. Our method enables the robot to learn from videos captured by daily mobile devices such as an iPad and generalize the policies to deployment environments with varying visual backgrounds, camera angles, spatial layouts, and novel object instances. We systematically evaluate our method on both short-horizon and long-horizon tasks, demonstrating the efficacy of ORION in learning from a single human video in the open world. Videos can be found in the project website https://ut-austin-rpl.github.io/ORION-release.