 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Initiative Dialog for Human-Robot Collaborative Manipulation
Aug 07, 2025Effective robotic systems for long-horizon human-robot collaboration must adapt to a wide range of human partners, whose physical behavior, willingness to assist, and understanding of the robot's capabilities may change over time. This demands a tightly coupled communication loop that grants both agents the flexibility to propose, accept, or decline requests as they coordinate toward completing the task effectively. We apply a Mixed-Initiative dialog paradigm to Collaborative human-roBot teaming and propose MICoBot, a system that handles the common scenario where both agents, using natural language, take initiative in formulating, accepting, or rejecting proposals on who can best complete different steps of a task. To handle diverse, task-directed dialog, and find successful collaborative strategies that minimize human effort, MICoBot makes decisions at three levels: (1) a meta-planner considers human dialog to formulate and code a high-level collaboration strategy, (2) a planner optimally allocates the remaining steps to either agent based on the robot's capabilities (measured by a simulation-pretrained affordance model) and the human's estimated availability to help, and (3) an action executor decides the low-level actions to perform or words to say to the human. Our extensive evaluations in simulation and real-world -- on a physical robot with 18 unique human participants over 27 hours -- demonstrate the ability of our method to effectively collaborate with diverse human users, yielding significantly improved task success and user experience than a pure LLM baseline and other agent allocation models. See additional videos and materials at https://robin-lab.cs.utexas.edu/MicoBot/.
BUMBLE: Unifying Reasoning and Acting with Vision-Language Models for Building-wide Mobile Manipulation
Oct 08, 2024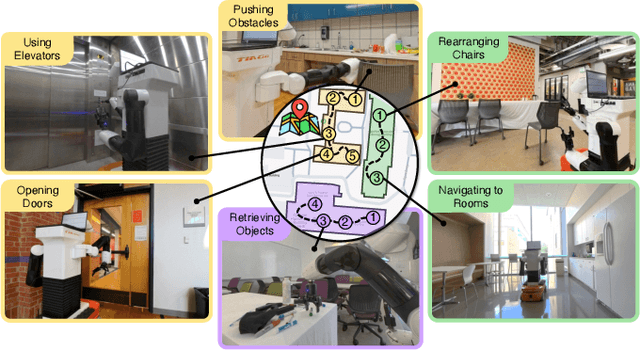



To operate at a building scale, service robots must perform very long-horizon mobile manipulation tasks by navigating to different rooms, accessing different floors, and interacting with a wide and unseen range of everyday objects. We refer to these tasks as Building-wide Mobile Manipulation. To tackle these inherently long-horizon tasks, we introduce BUMBLE, a unified Vision-Language Model (VLM)-based framework integrating open-world RGBD perception, a wide spectrum of gross-to-fine motor skills, and dual-layered memory. Our extensive evaluation (90+ hours) indicates that BUMBLE outperforms multiple baselines in long-horizon building-wide tasks that require sequencing up to 12 ground truth skills spanning 15 minutes per trial. BUMBLE achieves 47.1% success rate averaged over 70 trials in different buildings, tasks, and scene layouts from different starting rooms and floors. Our user study demonstrates 22% higher satisfaction with our method than state-of-the-art mobile manipulation methods. Finally, we demonstrate the potential of using increasingly-capable foundation models to push performance further. For more information, see https://robin-lab.cs.utexas.edu/BUMBLE/
Natural Language Can Help Bridge the Sim2Real Gap
May 16, 2024



The main challenge in learning image-conditioned robotic policies is acquiring a visual representation conducive to low-level control. Due to the high dimensionality of the image space, learning a good visual representation requires a considerable amount of visual data. However, when learning in the real world, data is expensive. Sim2Real is a promising paradigm for overcoming data scarcity in the real-world target domain by using a simulator to collect large amounts of cheap data closely related to the target task. However, it is difficult to transfer an image-conditioned policy from sim to real when the domains are very visually dissimilar. To bridge the sim2real visual gap, we propose using natural language descriptions of images as a unifying signal across domains that captures the underlying task-relevant semantics. Our key insight is that if two image observations from different domains are labeled with similar language, the policy should predict similar action distributions for both images. We demonstrate that training the image encoder to predict the language description or the distance between descriptions of a sim or real image serves as a useful, data-efficient pretraining step that helps learn a domain-invariant image representation. We can then use this image encoder as the backbone of an IL policy trained simultaneously on a large amount of simulated and a handful of real demonstrations. Our approach outperforms widely used prior sim2real methods and strong vision-language pretraining baselines like CLIP and R3M by 25 to 40%.
Using Both Demonstrations and Language Instructions to Efficiently Learn Robotic Tasks
Oct 10, 2022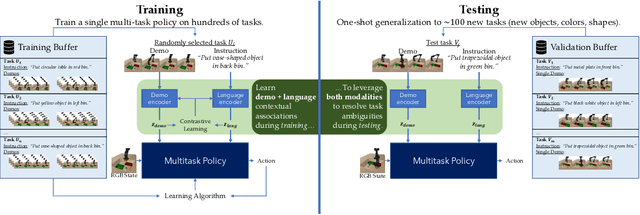
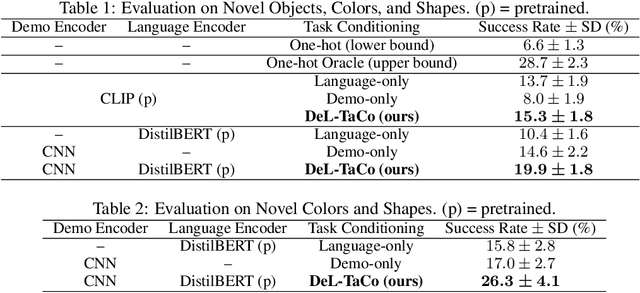
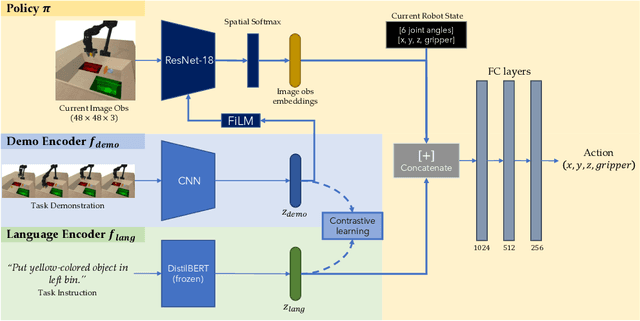
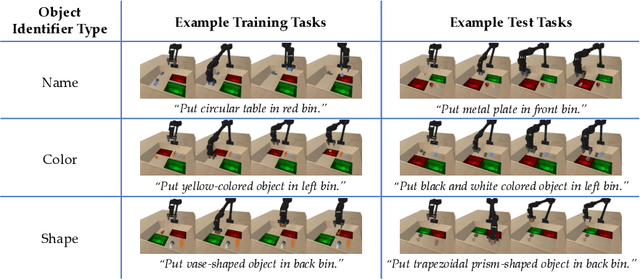
Demonstrations and natural language instructions are two common ways to specify and teach robots novel tasks. However, for many complex tasks, a demonstration or language instruction alone contains ambiguities, preventing tasks from being specified clearly. In such cases, a combination of both a demonstration and an instruction more concisely and effectively conveys the task to the robot than either modality alone. To instantiate this problem setting, we train a single multi-task policy on a few hundred challenging robotic pick-and-place tasks and propose DeL-TaCo (Joint Demo-Language Task Conditioning), a method for conditioning a robotic policy on task embeddings comprised of two components: a visual demonstration and a language instruction. By allowing these two modalities to mutually disambiguate and clarify each other during novel task specification, DeL-TaCo (1) substantially decreases the teacher effort needed to specify a new task and (2) achieves better generalization performance on novel objects and instructions over previous task-conditioning methods. To our knowledge, this is the first work to show that simultaneously conditioning a multi-task robotic manipulation policy on both demonstration and language embeddings improves sample efficiency and generalization over conditioning on either modality alone. See additional materials at https://sites.google.com/view/del-taco-learning
Don't Start From Scratch: Leveraging Prior Data to Automate Robotic Reinforcement Learning
Jul 17, 2022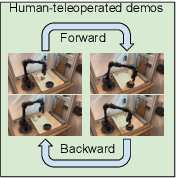


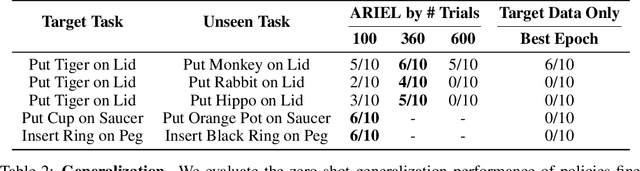
Reinforcement learning (RL) algorithms hold the promise of enabling autonomous skill acquisition for robotic systems. However, in practice, real-world robotic RL typically requires time consuming data collection and frequent human intervention to reset the environment. Moreover, robotic policies learned with RL often fail when deployed beyond the carefully controlled setting in which they were learned. In this work, we study how these challenges can all be tackled by effective utilization of diverse offline datasets collected from previously seen tasks. When faced with a new task, our system adapts previously learned skills to quickly learn to both perform the new task and return the environment to an initial state, effectively performing its own environment reset. Our empirical results demonstrate that incorporating prior data into robotic reinforcement learning enables autonomous learning, substantially improves sample-efficiency of learning, and enables better generalization. Project website: https://sites.google.com/view/ariel-berkeley/
Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
Nov 19, 2020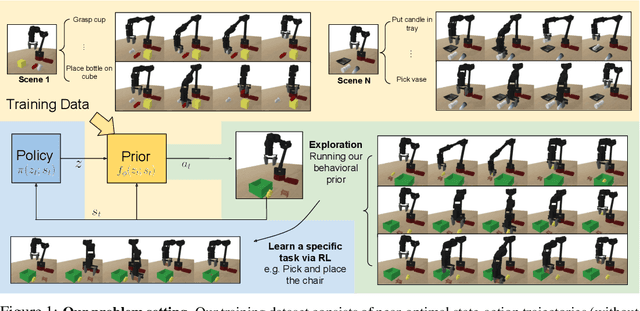
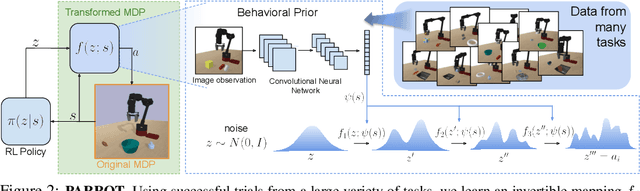

Reinforcement learning provides a general framework for flexible decision making and control, but requires extensive data collection for each new task that an agent needs to learn. In other machine learning fields, such as natural language processing or computer vision, pre-training on large, previously collected datasets to bootstrap learning for new tasks has emerged as a powerful paradigm to reduce data requirements when learning a new task. In this paper, we ask the following question: how can we enable similarly useful pre-training for RL agents? We propose a method for pre-training behavioral priors that can capture complex input-output relationships observed in successful trials from a wide range of previously seen tasks, and we show how this learned prior can be used for rapidly learning new tasks without impeding the RL agent's ability to try out novel behaviors. We demonstrate the effectiveness of our approach in challenging robotic manipulation domains involving image observations and sparse reward functions, where our method outperforms prior works by a substantial margin.
COG: Connecting New Skills to Past Experience with Offline Reinforcement Learning
Oct 27, 2020
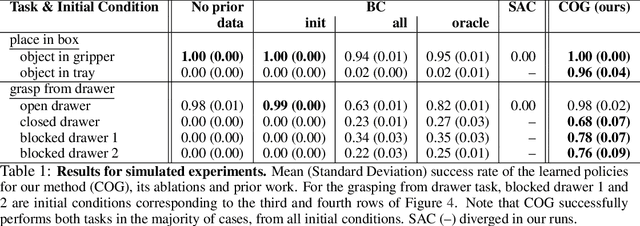
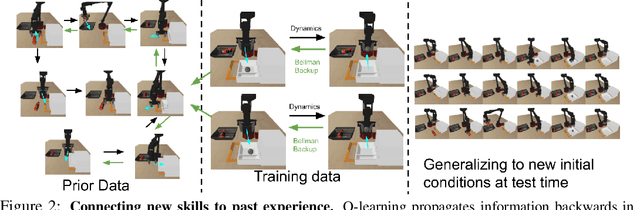

Reinforcement learning has been applied to a wide variety of robotics problems, but most of such applications involve collecting data from scratch for each new task. Since the amount of robot data we can collect for any single task is limited by time and cost considerations, the learned behavior is typically narrow: the policy can only execute the task in a handful of scenarios that it was trained on. What if there was a way to incorporate a large amount of prior data, either from previously solved tasks or from unsupervised or undirected environment interaction, to extend and generalize learned behaviors? While most prior work on extending robotic skills using pre-collected data focuses on building explicit hierarchies or skill decompositions, we show in this paper that we can reuse prior data to extend new skills simply through dynamic programming. We show that even when the prior data does not actually succeed at solving the new task, it can still be utilized for learning a better policy, by providing the agent with a broader understanding of the mechanics of its environment. We demonstrate the effectiveness of our approach by chaining together several behaviors seen in prior datasets for solving a new task, with our hardest experimental setting involving composing four robotic skills in a row: picking, placing, drawer opening, and grasping, where a +1/0 sparse reward is provided only on task completion. We train our policies in an end-to-end fashion, mapping high-dimensional image observations to low-level robot control commands, and present results in both simulated and real world domains. Additional materials and source code can be found on our project website: https://sites.google.com/view/cog-rl