 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasper: Inferring Diverse Intents for Assistive Teleoperation with Vision Language Models
Jun 17, 2025



Assistive teleoperation, where control is shared between a human and a robot, enables efficient and intuitive human-robot collaboration in diverse and unstructured environments. A central challenge in real-world assistive teleoperation is for the robot to infer a wide range of human intentions from user control inputs and to assist users with correct actions. Existing methods are either confined to simple, predefined scenarios or restricted to task-specific data distributions at training, limiting their support for real-world assistance. We introduce Casper, an assistive teleoperation system that leverages commonsense knowledge embedded in pre-trained visual language models (VLMs) for real-time intent inference and flexible skill execution. Casper incorporates an open-world perception module for a generalized understanding of novel objects and scenes, a VLM-powered intent inference mechanism that leverages commonsense reasoning to interpret snippets of teleoperated user input, and a skill library that expands the scope of prior assistive teleoperation systems to support diverse, long-horizon mobile manipulation tasks. Extensive empirical evaluation, including human studies and system ablations, demonstrates that Casper improves task performance, reduces human cognitive load, and achieves higher user satisfaction than direct teleoperation and assistive teleoperation baselines.
SCIZOR: A Self-Supervised Approach to Data Curation for Large-Scale Imitation Learning
May 28, 2025Imitation learning advances robot capabilities by enabling the acquisition of diverse behaviors from human demonstrations. However, large-scale datasets used for policy training often introduce substantial variability in quality, which can negatively impact performance. As a result, automatically curating datasets by filtering low-quality samples to improve quality becomes essential. Existing robotic curation approaches rely on costly manual annotations and perform curation at a coarse granularity, such as the dataset or trajectory level, failing to account for the quality of individual state-action pairs. To address this, we introduce SCIZOR, a self-supervised data curation framework that filters out low-quality state-action pairs to improve the performance of imitation learning policies. SCIZOR targets two complementary sources of low-quality data: suboptimal data, which hinders learning with undesirable actions, and redundant data, which dilutes training with repetitive patterns. SCIZOR leverages a self-supervised task progress predictor for suboptimal data to remove samples lacking task progression, and a deduplication module operating on joint state-action representation for samples with redundant patterns. Empirically, we show that SCIZOR enables imitation learning policies to achieve higher performance with less data, yielding an average improvement of 15.4% across multiple benchmarks. More information is available at: https://ut-austin-rpl.github.io/SCIZOR/
Multi-Task Interactive Robot Fleet Learning with Visual World Models
Oct 30, 2024Recent advancements in large-scale multi-task robot learning offer the potential for deploying robot fleets in household and industrial settings, enabling them to perform diverse tasks across various environments. However, AI-enabled robots often face challenges with generalization and robustness when exposed to real-world variability and uncertainty. We introduce Sirius-Fleet, a multi-task interactive robot fleet learning framework to address these challenges. Sirius-Fleet monitors robot performance during deployment and involves humans to correct the robot's actions when necessary. We employ a visual world model to predict the outcomes of future actions and build anomaly predictors to predict whether they will likely result in anomalies. As the robot autonomy improves, the anomaly predictors automatically adapt their prediction criteria, leading to fewer requests for human intervention and gradually reducing human workload over time. Evaluations on large-scale benchmarks demonstrate Sirius-Fleet's effectiveness in improving multi-task policy performance and monitoring accuracy. We demonstrate Sirius-Fleet's performance in both RoboCasa in simulation and Mutex in the real world, two diverse, large-scale multi-task benchmarks. More information is available on the project website: https://ut-austin-rpl.github.io/sirius-fleet
PRIME: Scaffolding Manipulation Tasks with Behavior Primitives for Data-Efficient Imitation Learning
Mar 10, 2024Imitation learning has shown great potential for enabling robots to acquire complex manipulation behaviors. However, these algorithms suffer from high sample complexity in long-horizon tasks, where compounding errors accumulate over the task horizons. We present PRIME (PRimitive-based IMitation with data Efficiency), a behavior primitive-based framework designed for improving the data efficiency of imitation learning. PRIME scaffolds robot tasks by decomposing task demonstrations into primitive sequences, followed by learning a high-level control policy to sequence primitives through imitation learning. Our experiments demonstrate that PRIME achieves a significant performance improvement in multi-stage manipulation tasks, with 10-34% higher success rates in simulation over state-of-the-art baselines and 20-48% on physical hardware.
Model-Based Runtime Monitoring with Interactive Imitation Learning
Oct 26, 2023



Robot learning methods have recently made great strides, but generalization and robustness challenges still hinder their widespread deployment. Failing to detect and address potential failures renders state-of-the-art learning systems not combat-ready for high-stakes tasks. Recent advances in interactive imitation learning have presented a promising framework for human-robot teaming, enabling the robots to operate safely and continually improve their performances over long-term deployments. Nonetheless, existing methods typically require constant human supervision and preemptive feedback, limiting their practicality in realistic domains. This work aims to endow a robot with the ability to monitor and detect errors during task execution. We introduce a model-based runtime monitoring algorithm that learns from deployment data to detect system anomalies and anticipate failures. Unlike prior work that cannot foresee future failures or requires failure experiences for training, our method learns a latent-space dynamics model and a failure classifier, enabling our method to simulate future action outcomes and detect out-of-distribution and high-risk states preemptively. We train our method within an interactive imitation learning framework, where it continually updates the model from the experiences of the human-robot team collected using trustworthy deployments. Consequently, our method reduces the human workload needed over time while ensuring reliable task execution. Our method outperforms the baselines across system-level and unit-test metrics, with 23% and 40% higher success rates in simulation and on physical hardware, respectively. More information at https://ut-austin-rpl.github.io/sirius-runtime-monitor/
Interactive Robot Learning from Verbal Correction
Oct 26, 2023The ability to learn and refine behavior after deployment has become ever more important for robots as we design them to operate in unstructured environments like households. In this work, we design a new learning system based on large language model (LLM), OLAF, that allows everyday users to teach a robot using verbal corrections when the robot makes mistakes, e.g., by saying "Stop what you're doing. You should move closer to the cup." A key feature of OLAF is its ability to update the robot's visuomotor neural policy based on the verbal feedback to avoid repeating mistakes in the future. This is in contrast to existing LLM-based robotic systems, which only follow verbal commands or corrections but not learn from them. We demonstrate the efficacy of our design in experiments where a user teaches a robot to perform long-horizon manipulation tasks both in simulation and on physical hardware, achieving on average 20.0% improvement in policy success rate. Videos and more results are at https://ut-austin-rpl.github.io/olaf/
Robot Learning on the Job: Human-in-the-Loop Autonomy and Learning During Deployment
Nov 15, 2022



With the rapid growth of computing powers and recent advances in deep learning, we have witnessed impressive demonstrations of novel robot capabilities in research settings. Nonetheless, these learning systems exhibit brittle generalization and require excessive training data for practical tasks. To harness the capabilities of state-of-the-art robot learning models while embracing their imperfections, we present Sirius, a principled framework for humans and robots to collaborate through a division of work. In this framework, partially autonomous robots are tasked with handling a major portion of decision-making where they work reliably; meanwhile, human operators monitor the process and intervene in challenging situations. Such a human-robot team ensures safe deployments in complex tasks. Further, we introduce a new learning algorithm to improve the policy's performance on the data collected from the task executions. The core idea is re-weighing training samples with approximated human trust and optimizing the policies with weighted behavioral cloning. We evaluate Sirius in simulation and on real hardware, showing that Sirius consistently outperforms baselines over a collection of contact-rich manipulation tasks, achieving 8% boost in simulation and 27% on real hardware than the state-of-the-art methods, with 3 times faster convergence and 15% memory size. Videos and code are available at https://ut-austin-rpl.github.io/sirius/
Augmenting Reinforcement Learning with Behavior Primitives for Diverse Manipulation Tasks
Oct 07, 2021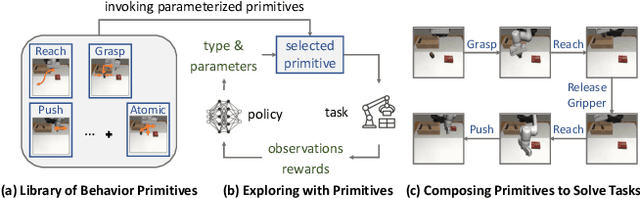
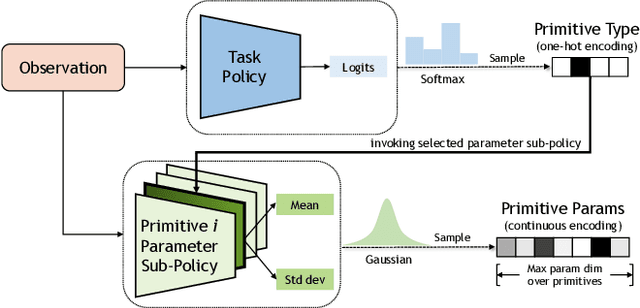

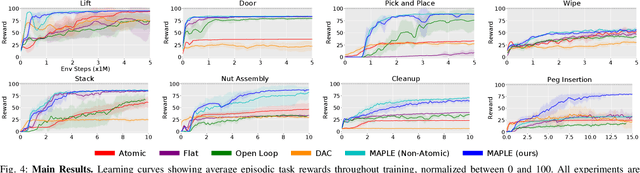
Realistic manipulation tasks require a robot to interact with an environment with a prolonged sequence of motor actions. While deep reinforcement learning methods have recently emerged as a promising paradigm for automating manipulation behaviors, they usually fall short in long-horizon tasks due to the exploration burden. This work introduces MAnipulation Primitive-augmented reinforcement LEarning (MAPLE), a learning framework that augments standard reinforcement learning algorithms with a pre-defined library of behavior primitives. These behavior primitives are robust functional modules specialized in achieving manipulation goals, such as grasping and pushing. To use these heterogeneous primitives, we develop a hierarchical policy that involves the primitives and instantiates their executions with input parameters. We demonstrate that MAPLE outperforms baseline approaches by a significant margin on a suite of simulated manipulation tasks. We also quantify the compositional structure of the learned behaviors and highlight our method's ability to transfer policies to new task variants and to physical hardware. Videos and code are available at https://ut-austin-rpl.github.io/maple
Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
Nov 19, 2020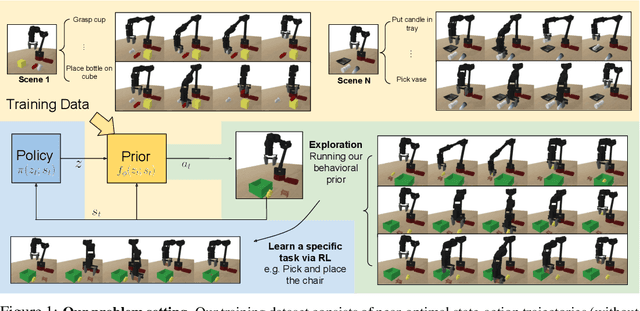
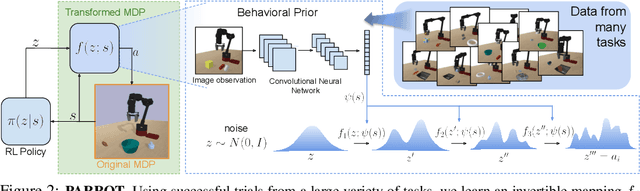
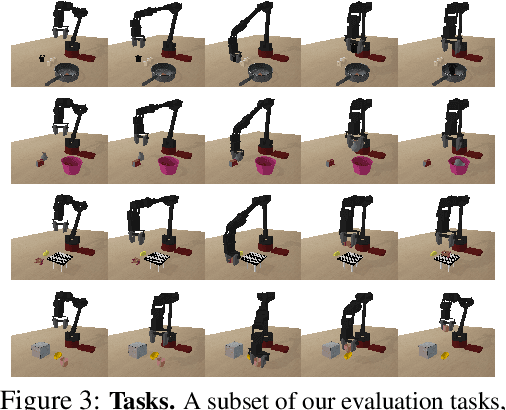

Reinforcement learning provides a general framework for flexible decision making and control, but requires extensive data collection for each new task that an agent needs to learn. In other machine learning fields, such as natural language processing or computer vision, pre-training on large, previously collected datasets to bootstrap learning for new tasks has emerged as a powerful paradigm to reduce data requirements when learning a new task. In this paper, we ask the following question: how can we enable similarly useful pre-training for RL agents? We propose a method for pre-training behavioral priors that can capture complex input-output relationships observed in successful trials from a wide range of previously seen tasks, and we show how this learned prior can be used for rapidly learning new tasks without impeding the RL agent's ability to try out novel behaviors. We demonstrate the effectiveness of our approach in challenging robotic manipulation domains involving image observations and sparse reward functions, where our method outperforms prior works by a substantial margin.
Design, Benchmarking and Explainability Analysis of a Game-Theoretic Framework towards Energy Efficiency in Smart Infrastructure
Oct 16, 2019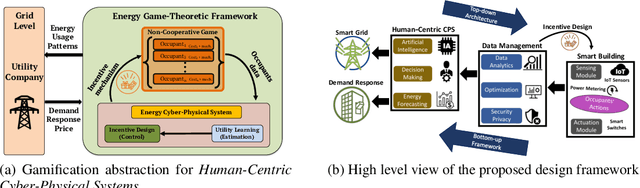
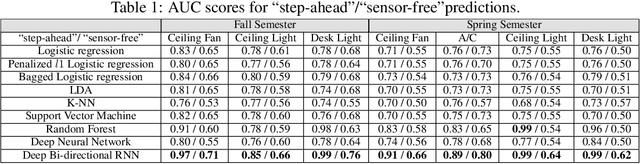
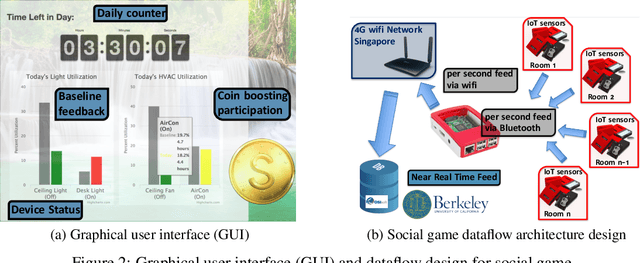
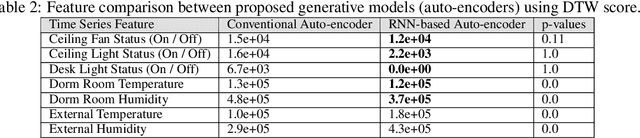
In this paper, we propose a gamification approach as a novel framework for smart building infrastructure with the goal of motivating human occupants to reconsider personal energy usage and to have positive effects on their environment. Human interaction in the context of cyber-physical systems is a core component and consideration in the implementation of any smart building technology. Research has shown that the adoption of human-centric building services and amenities leads to improvements in the operational efficiency of these cyber-physical systems directed towards controlling building energy usage. We introduce a strategy in form of a game-theoretic framework that incorporates humans-in-the-loop modeling by creating an interface to allow building managers to interact with occupants and potentially incentivize energy efficient behavior. Prior works on game theoretic analysis typically rely on the assumption that the utility function of each individual agent is known a priori. Instead, we propose novel utility learning framework for benchmarking that employs robust estimations of occupant actions towards energy efficiency. To improve forecasting performance, we extend the utility learning scheme by leveraging deep bi-directional recurrent neural networks. Using the proposed methods on data gathered from occupant actions for resources such as room lighting, we forecast patterns of energy resource usage to demonstrate the prediction performance of the methods. The results of our study show that we can achieve a highly accurate representation of the ground truth for occupant energy resource usage. We also demonstrate the explainable nature on human decision making towards energy usage inherent in the dataset using graphical lasso and granger causality algorithms. Finally, we open source the de-identified, high-dimensional data pertaining to the energy game-theoretic framework.