 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL: Benchmarking Autonomous Agents on Deterministic Simulations of Real Websites
Apr 15, 2025

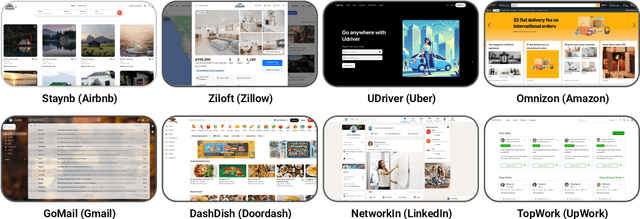

We introduce REAL, a benchmark and framework for multi-turn agent evaluations on deterministic simulations of real-world websites. REAL comprises high-fidelity, deterministic replicas of 11 widely-used websites across domains such as e-commerce, travel, communication, and professional networking. We also release a benchmark consisting of 112 practical tasks that mirror everyday complex user interactions requiring both accurate information retrieval and state-changing actions. All interactions occur within this fully controlled setting, eliminating safety risks and enabling robust, reproducible evaluation of agent capability and reliability. Our novel evaluation framework combines programmatic checks of website state for action-based tasks with rubric-guided LLM-based judgments for information retrieval. The framework supports both open-source and proprietary agent systems through a flexible evaluation harness that accommodates black-box commands within browser environments, allowing research labs to test agentic systems without modification. Our empirical results show that frontier language models achieve at most a 41% success rate on REAL, highlighting critical gaps in autonomous web navigation and task completion capabilities. Our framework supports easy integration of new tasks, reproducible evaluation, and scalable data generation for training web agents. The websites, framework, and leaderboard are available at https://realevals.xyz and https://github.com/agi-inc/REAL.
Multi-Task Interactive Robot Fleet Learning with Visual World Models
Oct 30, 2024Recent advancements in large-scale multi-task robot learning offer the potential for deploying robot fleets in household and industrial settings, enabling them to perform diverse tasks across various environments. However, AI-enabled robots often face challenges with generalization and robustness when exposed to real-world variability and uncertainty. We introduce Sirius-Fleet, a multi-task interactive robot fleet learning framework to address these challenges. Sirius-Fleet monitors robot performance during deployment and involves humans to correct the robot's actions when necessary. We employ a visual world model to predict the outcomes of future actions and build anomaly predictors to predict whether they will likely result in anomalies. As the robot autonomy improves, the anomaly predictors automatically adapt their prediction criteria, leading to fewer requests for human intervention and gradually reducing human workload over time. Evaluations on large-scale benchmarks demonstrate Sirius-Fleet's effectiveness in improving multi-task policy performance and monitoring accuracy. We demonstrate Sirius-Fleet's performance in both RoboCasa in simulation and Mutex in the real world, two diverse, large-scale multi-task benchmarks. More information is available on the project website: https://ut-austin-rpl.github.io/sirius-fleet
Training-Free Activation Sparsity in Large Language Models
Aug 26, 2024Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$\times$ and 1.8$\times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
BitDelta: Your Fine-Tune May Only Be Worth One Bit
Feb 28, 2024Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given the higher computational demand of pre-training, it's intuitive to assume that fine-tuning adds less new information to the model, and is thus more compressible. We explore this assumption by decomposing the weights of fine-tuned models into their pre-trained components and an additional delta. We introduce a simple method, BitDelta, which successfully quantizes this delta down to 1 bit without compromising performance. This interesting finding not only highlights the potential redundancy of information added during fine-tuning, but also has significant implications for the multi-tenant serving and multi-tenant storage of fine-tuned models. By enabling the use of a single high-precision base model accompanied by multiple 1-bit deltas, BitDelta dramatically reduces GPU memory requirements by more than 10x, which can also be translated to enhanced generation latency in multi-tenant settings. We validate BitDelta through experiments across Llama-2 and Mistral model families, and on models up to 70B parameters, showcasing minimal performance degradation over all tested settings.