 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
Dec 12, 2025The growing demand for long-context inference capabilities in Large Language Models (LLMs) has intensified the computational and memory bottlenecks inherent to the standard attention mechanism. To address this challenge, we introduce BLASST, a drop-in sparse attention method that dynamically prunes the attention matrix without any pre-computation or proxy scores. Our method uses a fixed threshold and existing information from online softmax to identify negligible attention scores, skipping softmax computation, Value block loading, and the subsequent matrix multiplication. This fits seamlessly into existing FlashAttention kernel designs with negligible latency overhead. The approach is applicable to both prefill and decode stages across all attention variants (MHA, GQA, MQA, and MLA), providing a unified solution for accelerating long-context inference. We develop an automated calibration procedure that reveals a simple inverse relationship between optimal threshold and context length, enabling robust deployment across diverse scenarios. Maintaining high accuracy, we demonstrate a 1.62x speedup for prefill at 74.7% sparsity and a 1.48x speedup for decode at 73.2% sparsity on modern GPUs. Furthermore, we explore sparsity-aware training as a natural extension, showing that models can be trained to be inherently more robust to sparse attention patterns, pushing the accuracy-sparsity frontier even further.
Optimizing Mixture of Block Attention
Nov 14, 2025Mixture of Block Attention (MoBA) (Lu et al., 2025) is a promising building block for efficiently processing long contexts in LLMs by enabling queries to sparsely attend to a small subset of key-value blocks, drastically reducing computational cost. However, the design principles governing MoBA's performance are poorly understood, and it lacks an efficient GPU implementation, hindering its practical adoption. In this paper, we first develop a statistical model to analyze MoBA's underlying mechanics. Our model reveals that performance critically depends on the router's ability to accurately distinguish relevant from irrelevant blocks based on query-key affinities. We derive a signal-to-noise ratio that formally connects architectural parameters to this retrieval accuracy. Guided by our analysis, we identify two key pathways for improvement: using smaller block sizes and applying a short convolution on keys to cluster relevant signals, which enhances routing accuracy. While theoretically better, small block sizes are inefficient on GPUs. To bridge this gap, we introduce FlashMoBA, a hardware-aware CUDA kernel that enables efficient MoBA execution even with the small block sizes our theory recommends. We validate our insights by training LLMs from scratch, showing that our improved MoBA models match the performance of dense attention baselines. FlashMoBA achieves up to 14.7x speedup over FlashAttention-2 for small blocks, making our theoretically-grounded improvements practical. Code is available at: https://github.com/mit-han-lab/flash-moba.
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Oct 10, 2025Vision-language models (VLMs) could power real-time assistants and autonomous agents, but they face a critical challenge: understanding near-infinite video streams without escalating latency and memory usage. Processing entire videos with full attention leads to quadratic computational costs and poor performance on long videos. Meanwhile, simple sliding window methods are also flawed, as they either break coherence or suffer from high latency due to redundant recomputation. In this paper, we introduce StreamingVLM, a model designed for real-time, stable understanding of infinite visual input. Our approach is a unified framework that aligns training with streaming inference. During inference, we maintain a compact KV cache by reusing states of attention sinks, a short window of recent vision tokens, and a long window of recent text tokens. This streaming ability is instilled via a simple supervised fine-tuning (SFT) strategy that applies full attention on short, overlapped video chunks, which effectively mimics the inference-time attention pattern without training on prohibitively long contexts. For evaluation, we build Inf-Streams-Eval, a new benchmark with videos averaging over two hours that requires dense, per-second alignment between frames and text. On Inf-Streams-Eval, StreamingVLM achieves a 66.18% win rate against GPT-4O mini and maintains stable, real-time performance at up to 8 FPS on a single NVIDIA H100. Notably, our SFT strategy also enhances general VQA abilities without any VQA-specific fine-tuning, improving performance on LongVideoBench by +4.30 and OVOBench Realtime by +5.96. Code is available at https://github.com/mit-han-lab/streaming-vlm.
XAttention: Block Sparse Attention with Antidiagonal Scoring
Mar 20, 2025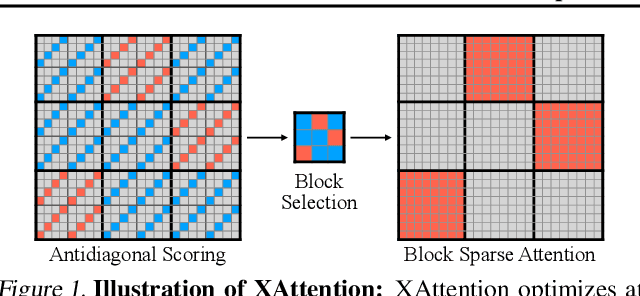
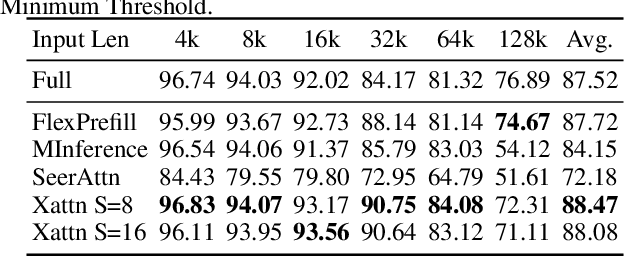
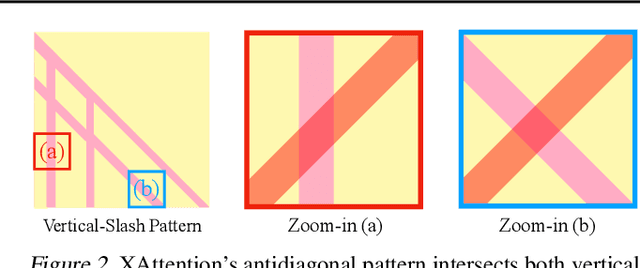
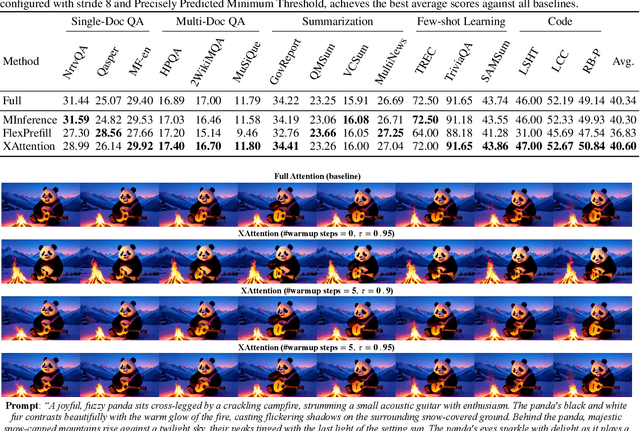
Long-Context Transformer Models (LCTMs) are vital for real-world applications but suffer high computational costs due to attention's quadratic complexity. Block-sparse attention mitigates this by focusing computation on critical regions, yet existing methods struggle with balancing accuracy and efficiency due to costly block importance measurements. In this paper, we introduce XAttention, a plug-and-play framework that dramatically accelerates long-context inference in Transformers models using sparse attention. XAttention's key innovation is the insight that the sum of antidiagonal values (i.e., from the lower-left to upper-right) in the attention matrix provides a powerful proxy for block importance. This allows for precise identification and pruning of non-essential blocks, resulting in high sparsity and dramatically accelerated inference. Across comprehensive evaluations on demanding long-context benchmarks-including RULER and LongBench for language, VideoMME for video understanding, and VBench for video generation. XAttention achieves accuracy comparable to full attention while delivering substantial computational gains. We demonstrate up to 13.5x acceleration in attention computation. These results underscore XAttention's ability to unlock the practical potential of block sparse attention, paving the way for scalable and efficient deployment of LCTMs in real-world applications. Code is available at https://github.com/mit-han-lab/x-attention.
LServe: Efficient Long-sequence LLM Serving with Unified Sparse Attention
Feb 20, 2025Large language models (LLMs) have shown remarkable potential in processing long sequences, yet efficiently serving these long-context models remains challenging due to the quadratic computational complexity of attention in the prefilling stage and the large memory footprint of the KV cache in the decoding stage. To address these issues, we introduce LServe, an efficient system that accelerates long-sequence LLM serving via hybrid sparse attention. This method unifies different hardware-friendly, structured sparsity patterns for both prefilling and decoding attention into a single framework, where computations on less important tokens are skipped block-wise. LServe demonstrates the compatibility of static and dynamic sparsity in long-context LLM attention. This design enables multiplicative speedups by combining these optimizations. Specifically, we convert half of the attention heads to nearly free streaming heads in both the prefilling and decoding stages. Additionally, we find that only a constant number of KV pages is required to preserve long-context capabilities, irrespective of context length. We then design a hierarchical KV page selection policy that dynamically prunes KV pages based on query-centric similarity. On average, LServe accelerates LLM prefilling by up to 2.9x and decoding by 1.3-2.1x over vLLM, maintaining long-context accuracy. Code is released at https://github.com/mit-han-lab/omniserve.
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Oct 14, 2024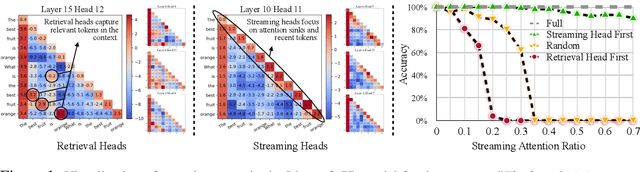
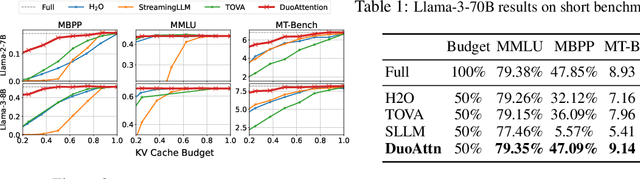
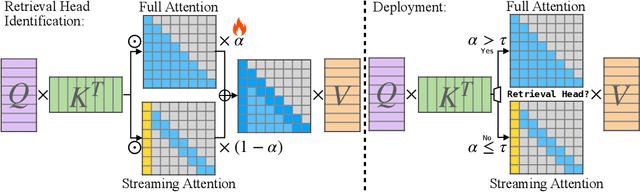

Deploying long-context large language models (LLMs) is essential but poses significant computational and memory challenges. Caching all Key and Value (KV) states across all attention heads consumes substantial memory. Existing KV cache pruning methods either damage the long-context capabilities of LLMs or offer only limited efficiency improvements. In this paper, we identify that only a fraction of attention heads, a.k.a, Retrieval Heads, are critical for processing long contexts and require full attention across all tokens. In contrast, all other heads, which primarily focus on recent tokens and attention sinks--referred to as Streaming Heads--do not require full attention. Based on this insight, we introduce DuoAttention, a framework that only applies a full KV cache to retrieval heads while using a light-weight, constant-length KV cache for streaming heads, which reduces both LLM's decoding and pre-filling memory and latency without compromising its long-context abilities. DuoAttention uses a lightweight, optimization-based algorithm with synthetic data to identify retrieval heads accurately. Our method significantly reduces long-context inference memory by up to 2.55x for MHA and 1.67x for GQA models while speeding up decoding by up to 2.18x and 1.50x and accelerating pre-filling by up to 1.73x and 1.63x for MHA and GQA models, respectively, with minimal accuracy loss compared to full attention. Notably, combined with quantization, DuoAttention enables Llama-3-8B decoding with 3.3 million context length on a single A100 GPU. Code is provided in https://github.com/mit-han-lab/duo-attention.
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jun 16, 2024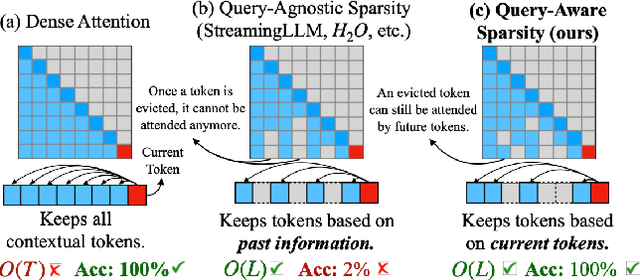
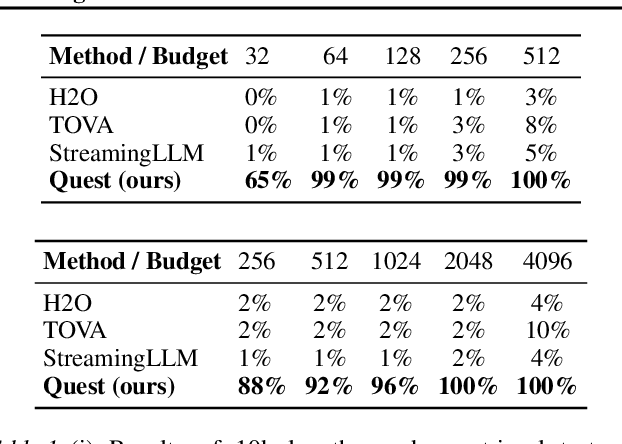
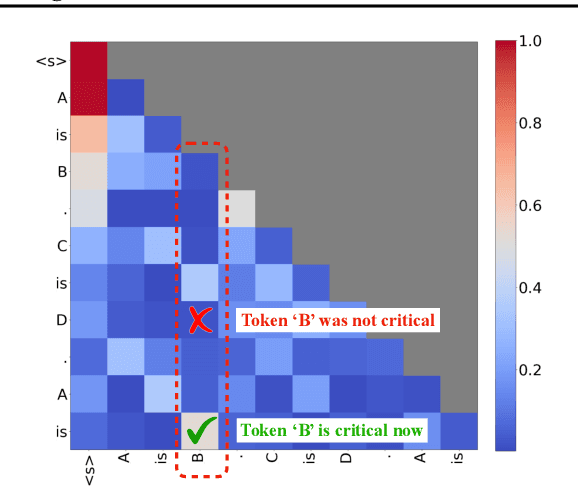
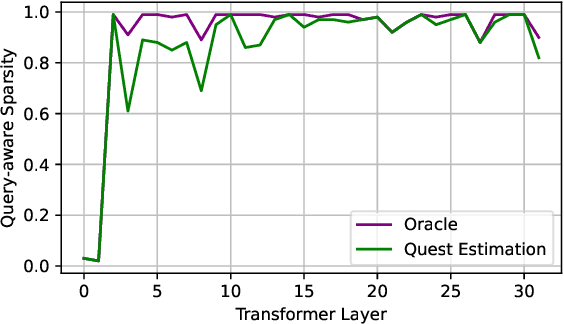
As the demand for long-context large language models (LLMs) increases, models with context windows of up to 128K or 1M tokens are becoming increasingly prevalent. However, long-context LLM inference is challenging since the inference speed decreases significantly as the sequence length grows. This slowdown is primarily caused by loading a large KV cache during self-attention. Previous works have shown that a small portion of critical tokens will dominate the attention outcomes. However, we observe the criticality of a token highly depends on the query. To this end, we propose Quest, a query-aware KV cache selection algorithm. Quest keeps track of the minimal and maximal Key values in KV cache pages and estimates the criticality of a given page using Query vectors. By only loading the Top-K critical KV cache pages for attention, Quest significantly speeds up self-attention without sacrificing accuracy. We show that Quest can achieve up to 2.23x self-attention speedup, which reduces inference latency by 7.03x while performing well on tasks with long dependencies with negligible accuracy loss. Code is available at http://github.com/mit-han-lab/Quest .
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
May 07, 2024
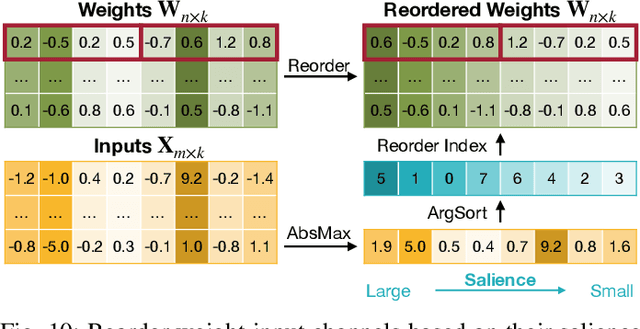
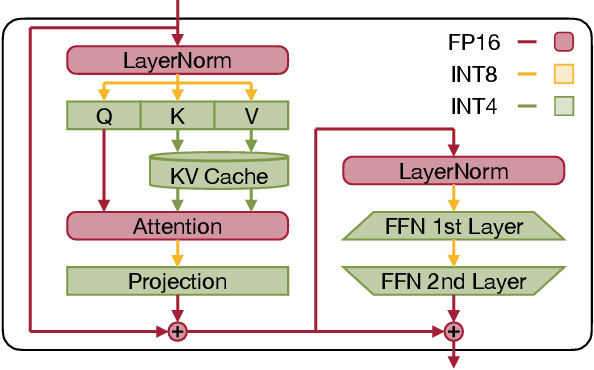
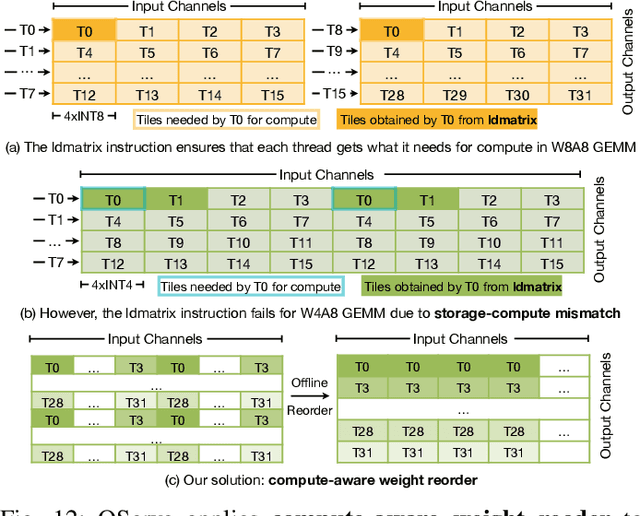
Quantization can accelerate large language model (LLM) inference. Going beyond INT8 quantization, the research community is actively exploring even lower precision, such as INT4. Nonetheless, state-of-the-art INT4 quantization techniques only accelerate low-batch, edge LLM inference, failing to deliver performance gains in large-batch, cloud-based LLM serving. We uncover a critical issue: existing INT4 quantization methods suffer from significant runtime overhead (20-90%) when dequantizing either weights or partial sums on GPUs. To address this challenge, we introduce QoQ, a W4A8KV4 quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache. QoQ stands for quattuor-octo-quattuor, which represents 4-8-4 in Latin. QoQ is implemented by the QServe inference library that achieves measured speedup. The key insight driving QServe is that the efficiency of LLM serving on GPUs is critically influenced by operations on low-throughput CUDA cores. Building upon this insight, in QoQ algorithm, we introduce progressive quantization that can allow low dequantization overhead in W4A8 GEMM. Additionally, we develop SmoothAttention to effectively mitigate the accuracy degradation incurred by 4-bit KV quantization. In the QServe system, we perform compute-aware weight reordering and take advantage of register-level parallelism to reduce dequantization latency. We also make fused attention memory-bound, harnessing the performance gain brought by KV4 quantization. As a result, QServe improves the maximum achievable serving throughput of Llama-3-8B by 1.2x on A100, 1.4x on L40S; and Qwen1.5-72B by 2.4x on A100, 3.5x on L40S, compared to TensorRT-LLM. Remarkably, QServe on L40S GPU can achieve even higher throughput than TensorRT-LLM on A100. Thus, QServe effectively reduces the dollar cost of LLM serving by 3x. Code is available at https://github.com/mit-han-lab/qserve.
Retrieval Head Mechanistically Explains Long-Context Factuality
Apr 24, 2024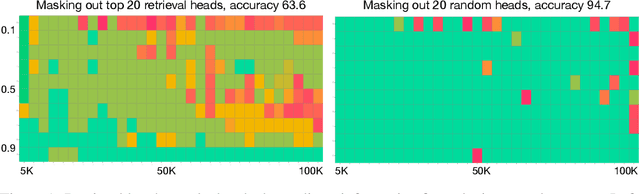
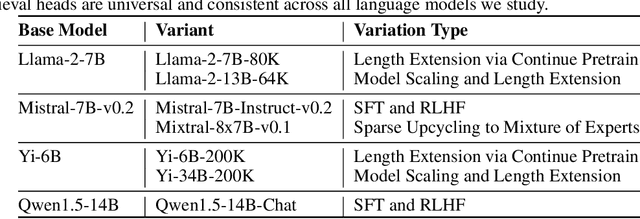

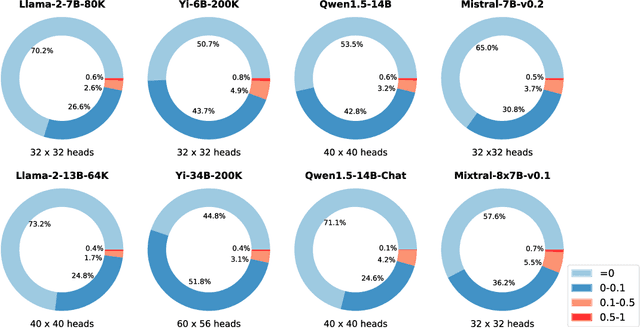
Despite the recent progress in long-context language models, it remains elusive how transformer-based models exhibit the capability to retrieve relevant information from arbitrary locations within the long context. This paper aims to address this question. Our systematic investigation across a wide spectrum of models reveals that a special type of attention heads are largely responsible for retrieving information, which we dub retrieval heads. We identify intriguing properties of retrieval heads:(1) universal: all the explored models with long-context capability have a set of retrieval heads; (2) sparse: only a small portion (less than 5\%) of the attention heads are retrieval. (3) intrinsic: retrieval heads already exist in models pretrained with short context. When extending the context length by continual pretraining, it is still the same set of heads that perform information retrieval. (4) dynamically activated: take Llama-2 7B for example, 12 retrieval heads always attend to the required information no matter how the context is changed. The rest of the retrieval heads are activated in different contexts. (5) causal: completely pruning retrieval heads leads to failure in retrieving relevant information and results in hallucination, while pruning random non-retrieval heads does not affect the model's retrieval ability. We further show that retrieval heads strongly influence chain-of-thought (CoT) reasoning, where the model needs to frequently refer back the question and previously-generated context. Conversely, tasks where the model directly generates the answer using its intrinsic knowledge are less impacted by masking out retrieval heads. These observations collectively explain which internal part of the model seeks information from the input tokens. We believe our insights will foster future research on reducing hallucination, improving reasoning, and compressing the KV cache.
BitDelta: Your Fine-Tune May Only Be Worth One Bit
Feb 28, 2024Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given the higher computational demand of pre-training, it's intuitive to assume that fine-tuning adds less new information to the model, and is thus more compressible. We explore this assumption by decomposing the weights of fine-tuned models into their pre-trained components and an additional delta. We introduce a simple method, BitDelta, which successfully quantizes this delta down to 1 bit without compromising performance. This interesting finding not only highlights the potential redundancy of information added during fine-tuning, but also has significant implications for the multi-tenant serving and multi-tenant storage of fine-tuned models. By enabling the use of a single high-precision base model accompanied by multiple 1-bit deltas, BitDelta dramatically reduces GPU memory requirements by more than 10x, which can also be translated to enhanced generation latency in multi-tenant settings. We validate BitDelta through experiments across Llama-2 and Mistral model families, and on models up to 70B parameters, showcasing minimal performance degradation over all tested settings.