 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfLLM: Unveiling the Intrinsic Capacity of LLMs for Understanding Extremely Long Sequences with Training-Free Memory
Paper and Code
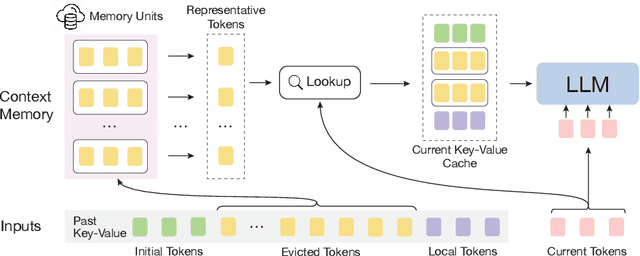
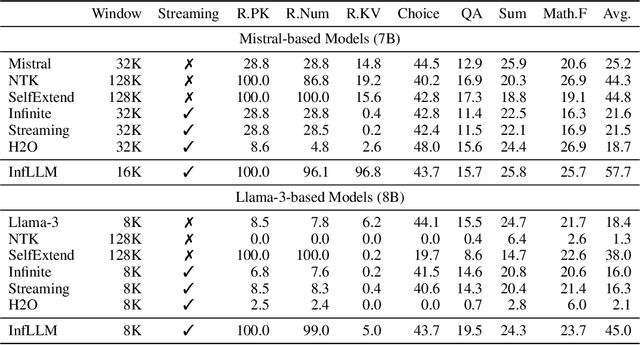

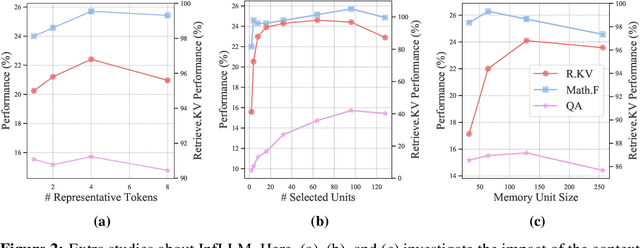
Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs, such as LLM-driven agents. However, existing LLMs, pre-trained on sequences with restricted maximum length, cannot generalize to longer sequences due to the out-of-domain and distraction issues. To alleviate these issues, existing efforts employ sliding attention windows and discard distant tokens to achieve the processing of extremely long sequences. Unfortunately, these approaches inevitably fail to capture long-distance dependencies within sequences to deeply understand semantics. This paper introduces a training-free memory-based method, InfLLM, to unveil the intrinsic ability of LLMs to process streaming long sequences. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to $1,024$K, InfLLM still effectively captures long-distance dependencies.