 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetraJet-v2: Accurate NVFP4 Training for Large Language Models with Oscillation Suppression and Outlier Control
Oct 31, 2025Large Language Models (LLMs) training is prohibitively expensive, driving interest in low-precision fully-quantized training (FQT). While novel 4-bit formats like NVFP4 offer substantial efficiency gains, achieving near-lossless training at such low precision remains challenging. We introduce TetraJet-v2, an end-to-end 4-bit FQT method that leverages NVFP4 for activations, weights, and gradients in all linear layers. We identify two critical issues hindering low-precision LLM training: weight oscillation and outliers. To address these, we propose: 1) an unbiased double-block quantization method for NVFP4 linear layers, 2) OsciReset, an algorithm to suppress weight oscillation, and 3) OutControl, an algorithm to retain outlier accuracy. TetraJet-v2 consistently outperforms prior FP4 training methods on pre-training LLMs across varying model sizes up to 370M and data sizes up to 200B tokens, reducing the performance gap to full-precision training by an average of 51.3%.
SageAttention2++: A More Efficient Implementation of SageAttention2
May 28, 2025



The efficiency of attention is critical because its time complexity grows quadratically with sequence length. SageAttention2 addresses this by utilizing quantization to accelerate matrix multiplications (Matmul) in attention. To further accelerate SageAttention2, we propose to utilize the faster instruction of FP8 Matmul accumulated in FP16. The instruction is 2x faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2. This means SageAttention2++ effectively accelerates various models, including those for language, image, and video generation, with negligible end-to-end metrics loss. The code will be available at https://github.com/thu-ml/SageAttention.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
May 16, 2025The efficiency of attention is important due to its quadratic time complexity. We enhance the efficiency of attention through two key contributions: First, we leverage the new FP4 Tensor Cores in Blackwell GPUs to accelerate attention computation. Our implementation achieves 1038 TOPS on RTX5090, which is a 5x speedup over the fastest FlashAttention on RTX5090. Experiments show that our FP4 attention can accelerate inference of various models in a plug-and-play way. Second, we pioneer low-bit attention to training tasks. Existing low-bit attention works like FlashAttention3 and SageAttention focus only on inference. However, the efficiency of training large models is also important. To explore whether low-bit attention can be effectively applied to training tasks, we design an accurate and efficient 8-bit attention for both forward and backward propagation. Experiments indicate that 8-bit attention achieves lossless performance in fine-tuning tasks but exhibits slower convergence in pretraining tasks. The code will be available at https://github.com/thu-ml/SageAttention.
Accurate INT8 Training Through Dynamic Block-Level Fallback
Mar 11, 2025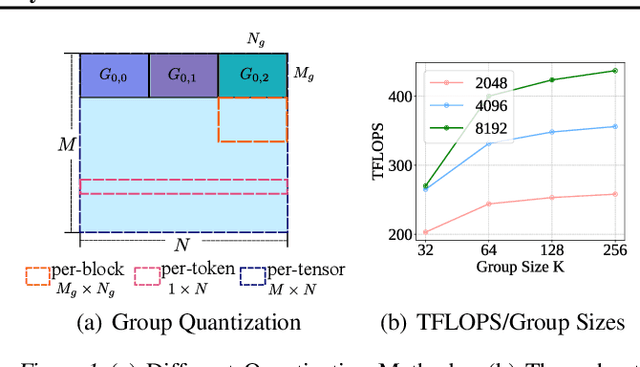
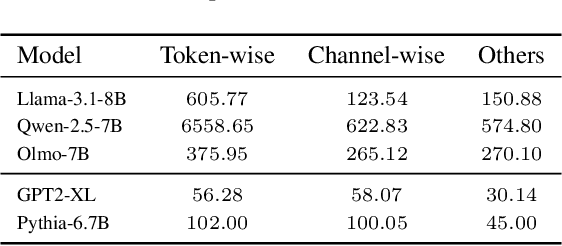
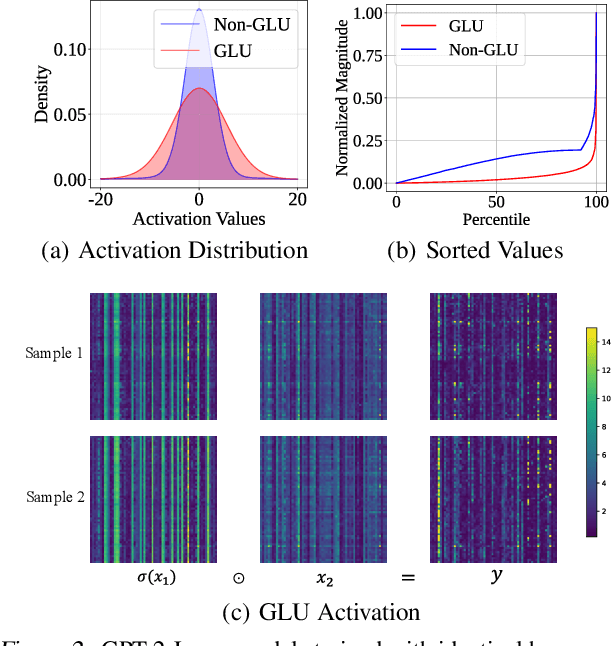
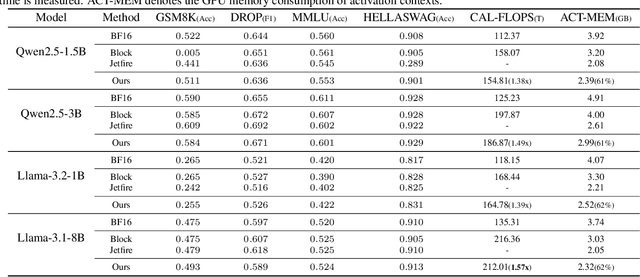
Transformer models have achieved remarkable success across various AI applications but face significant training costs. Low-bit training, such as INT8 training, can leverage computational units with higher throughput, and has already demonstrated its effectiveness on GPT2 models with block-level quantization. However, it struggles with modern Transformer variants incorporating GLU units. This is because those variants demonstrate complex distributions of activation outliers. To address the challenge, we propose Fallback Quantization, implementing mixed-precision GEMM that dynamically falls back 8-bit to 16-bit for activation blocks containing outliers. Experiments show that our approach is robustly competent in both fine-tuning and pretraining settings. Moreover, our method achieves a 1.57x end-to-end training speedup on RTX4090 GPUs.
SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug-and-play Inference Acceleration
Nov 17, 2024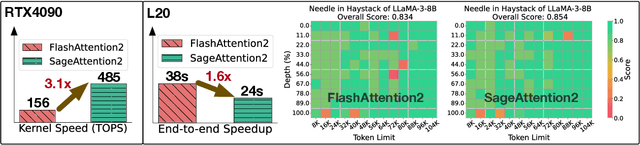



Although quantization for linear layers has been widely used, its application to accelerate the attention process remains limited. SageAttention utilizes 8-bit matrix multiplication, 16-bit matrix multiplication with 16-bit accumulator, and precision-enhancing methods, implementing an accurate and 2x speedup kernel compared to FlashAttention2. To further enhance the efficiency of attention computation while maintaining precision, we propose SageAttention2, which utilizes significantly faster 4-bit matrix multiplication (Matmul) alongside additional precision-enhancing techniques. First, we propose to quantize matrixes $(Q, K)$ to INT4 in a warp-level granularity and quantize matrixes $(\widetilde P, V)$ to FP8. Second, we propose a method to smooth $Q$ and $V$, enhancing the accuracy of attention with INT4 $QK$ and FP8 $PV$. Third, we analyze the quantization accuracy across timesteps and layers, then propose an adaptive quantization method to ensure the end-to-end metrics over various models. The operations per second (OPS) of SageAttention2 surpass FlashAttention2 and xformers by about 3x and 5x on RTX4090, respectively. Comprehensive experiments confirm that our approach incurs negligible end-to-end metrics loss across diverse models, including those for large language processing, image generation, and video generation. The codes are available at https://github.com/thu-ml/SageAttention.
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
Oct 03, 2024



The transformer architecture predominates across various models. As the heart of the transformer, attention has a computational complexity of O(N^2), compared to O(N) for linear transformations. When handling large sequence lengths, attention becomes the primary time-consuming component. Although quantization has proven to be an effective method for accelerating model inference, existing quantization methods primarily focus on optimizing the linear layer. In response, we first analyze the feasibility of quantization in attention detailedly. Following that, we propose SageAttention, a highly efficient and accurate quantization method for attention. The OPS (operations per second) of our approach outperforms FlashAttention2 and xformers by about 2.1 times and 2.7 times, respectively. SageAttention also achieves superior accuracy performance over FlashAttention3. Comprehensive experiments confirm that our approach incurs almost no end-to-end metrics loss across diverse models, including those for large language processing, image generation, and video generation.
InfLLM: Unveiling the Intrinsic Capacity of LLMs for Understanding Extremely Long Sequences with Training-Free Memory
Feb 07, 2024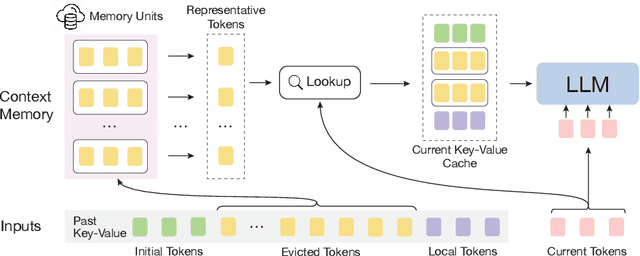
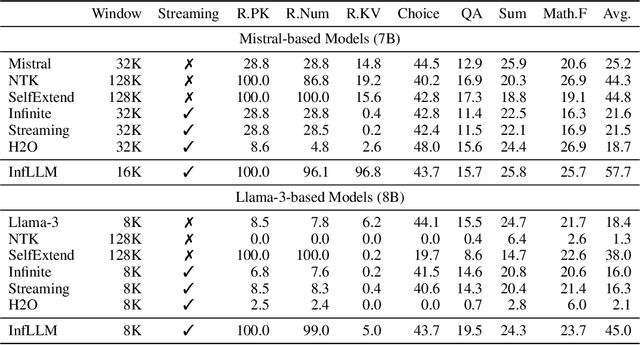

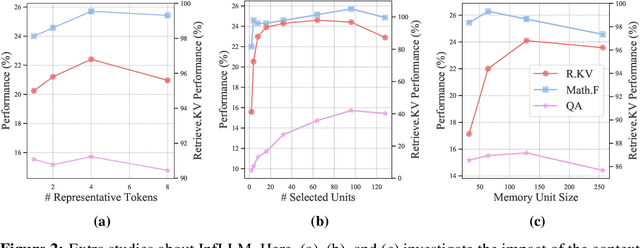
Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs, such as LLM-driven agents. However, existing LLMs, pre-trained on sequences with restricted maximum length, cannot generalize to longer sequences due to the out-of-domain and distraction issues. To alleviate these issues, existing efforts employ sliding attention windows and discard distant tokens to achieve the processing of extremely long sequences. Unfortunately, these approaches inevitably fail to capture long-distance dependencies within sequences to deeply understand semantics. This paper introduces a training-free memory-based method, InfLLM, to unveil the intrinsic ability of LLMs to process streaming long sequences. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to $1,024$K, InfLLM still effectively captures long-distance dependencies.
Variator: Accelerating Pre-trained Models with Plug-and-Play Compression Modules
Oct 24, 2023Pre-trained language models (PLMs) have achieved remarkable results on NLP tasks but at the expense of huge parameter sizes and the consequent computational costs. In this paper, we propose Variator, a parameter-efficient acceleration method that enhances computational efficiency through plug-and-play compression plugins. Compression plugins are designed to reduce the sequence length via compressing multiple hidden vectors into one and trained with original PLMs frozen. Different from traditional model acceleration methods, which compress PLMs to smaller sizes, Variator offers two distinct advantages: (1) In real-world applications, the plug-and-play nature of our compression plugins enables dynamic selection of different compression plugins with varying acceleration ratios based on the current workload. (2) The compression plugin comprises a few compact neural network layers with minimal parameters, significantly saving storage and memory overhead, particularly in scenarios with a growing number of tasks. We validate the effectiveness of Variator on seven datasets. Experimental results show that Variator can save 53% computational costs using only 0.9% additional parameters with a performance drop of less than 2%. Moreover, when the model scales to billions of parameters, Variator matches the strong performance of uncompressed PLMs.