 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD$^2$Quant: Accurate Low-bit Post-Training Weight Quantization for LLMs
Jan 30, 2026Large language models (LLMs) deliver strong performance, but their high compute and memory costs make deployment difficult in resource-constrained scenarios. Weight-only post-training quantization (PTQ) is appealing, as it reduces memory usage and enables practical speedup without low-bit operators or specialized hardware. However, accuracy often degrades significantly in weight-only PTQ at sub-4-bit precision, and our analysis identifies two main causes: (1) down-projection matrices are a well-known quantization bottleneck, but maintaining their fidelity often requires extra bit-width; (2) weight quantization induces activation deviations, but effective correction strategies remain underexplored. To address these issues, we propose D$^2$Quant, a novel weight-only PTQ framework that improves quantization from both the weight and activation perspectives. On the weight side, we design a Dual-Scale Quantizer (DSQ) tailored to down-projection matrices, with an absorbable scaling factor that significantly improves accuracy without increasing the bit budget. On the activation side, we propose Deviation-Aware Correction (DAC), which incorporates a mean-shift correction within LayerNorm to mitigate quantization-induced activation distribution shifts. Extensive experiments across multiple LLM families and evaluation metrics show that D$^2$Quant delivers superior performance for weight-only PTQ at sub-4-bit precision. The code and models will be available at https://github.com/XIANGLONGYAN/D2Quant.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
Hybrid-Tower: Fine-grained Pseudo-query Interaction and Generation for Text-to-Video Retrieval
Sep 05, 2025The Text-to-Video Retrieval (T2VR) task aims to retrieve unlabeled videos by textual queries with the same semantic meanings. Recent CLIP-based approaches have explored two frameworks: Two-Tower versus Single-Tower framework, yet the former suffers from low effectiveness, while the latter suffers from low efficiency. In this study, we explore a new Hybrid-Tower framework that can hybridize the advantages of the Two-Tower and Single-Tower framework, achieving high effectiveness and efficiency simultaneously. We propose a novel hybrid method, Fine-grained Pseudo-query Interaction and Generation for T2VR, ie, PIG, which includes a new pseudo-query generator designed to generate a pseudo-query for each video. This enables the video feature and the textual features of pseudo-query to interact in a fine-grained manner, similar to the Single-Tower approaches to hold high effectiveness, even before the real textual query is received. Simultaneously, our method introduces no additional storage or computational overhead compared to the Two-Tower framework during the inference stage, thus maintaining high efficiency. Extensive experiments on five commonly used text-video retrieval benchmarks demonstrate that our method achieves a significant improvement over the baseline, with an increase of $1.6\% \sim 3.9\%$ in R@1. Furthermore, our method matches the efficiency of Two-Tower models while achieving near state-of-the-art performance, highlighting the advantages of the Hybrid-Tower framework.
Proximal Supervised Fine-Tuning
Aug 25, 2025



Supervised fine-tuning (SFT) of foundation models often leads to poor generalization, where prior capabilities deteriorate after tuning on new tasks or domains. Inspired by trust-region policy optimization (TRPO) and proximal policy optimization (PPO) in reinforcement learning (RL), we propose Proximal SFT (PSFT). This fine-tuning objective incorporates the benefits of trust-region, effectively constraining policy drift during SFT while maintaining competitive tuning. By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages. Experiments across mathematical and human-value domains show that PSFT matches SFT in-domain, outperforms it in out-of-domain generalization, remains stable under prolonged training without causing entropy collapse, and provides a stronger foundation for the subsequent optimization.
Flexible Realignment of Language Models
Jun 15, 2025Realignment becomes necessary when a language model (LM) fails to meet expected performance. We propose a flexible realignment framework that supports quantitative control of alignment degree during training and inference. This framework incorporates Training-time Realignment (TrRa), which efficiently realigns the reference model by leveraging the controllable fusion of logits from both the reference and already aligned models. For example, TrRa reduces token usage by 54.63% on DeepSeek-R1-Distill-Qwen-1.5B without any performance degradation, outperforming DeepScaleR-1.5B's 33.86%. To complement TrRa during inference, we introduce a layer adapter that enables smooth Inference-time Realignment (InRa). This adapter is initialized to perform an identity transformation at the bottom layer and is inserted preceding the original layers. During inference, input embeddings are simultaneously processed by the adapter and the original layer, followed by the remaining layers, and then controllably interpolated at the logit level. We upgraded DeepSeek-R1-Distill-Qwen-7B from a slow-thinking model to one that supports both fast and slow thinking, allowing flexible alignment control even during inference. By encouraging deeper reasoning, it even surpassed its original performance.
The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason
May 28, 2025Recent studies on post-training large language models (LLMs) for reasoning through reinforcement learning (RL) typically focus on tasks that can be accurately verified and rewarded, such as solving math problems. In contrast, our research investigates the impact of reward noise, a more practical consideration for real-world scenarios involving the post-training of LLMs using reward models. We found that LLMs demonstrate strong robustness to substantial reward noise. For example, manually flipping 40% of the reward function's outputs in math tasks still allows a Qwen-2.5-7B model to achieve rapid convergence, improving its performance on math tasks from 5% to 72%, compared to the 75% accuracy achieved by a model trained with noiseless rewards. Surprisingly, by only rewarding the appearance of key reasoning phrases (namely reasoning pattern reward, RPR), such as ``first, I need to''-without verifying the correctness of answers, the model achieved peak downstream performance (over 70% accuracy for Qwen-2.5-7B) comparable to models trained with strict correctness verification and accurate rewards. Recognizing the importance of the reasoning process over the final results, we combined RPR with noisy reward models. RPR helped calibrate the noisy reward models, mitigating potential false negatives and enhancing the LLM's performance on open-ended tasks. These findings suggest the importance of improving models' foundational abilities during the pre-training phase while providing insights for advancing post-training techniques. Our code and scripts are available at https://github.com/trestad/Noisy-Rewards-in-Learning-to-Reason.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
QAVA: Query-Agnostic Visual Attack to Large Vision-Language Models
Apr 15, 2025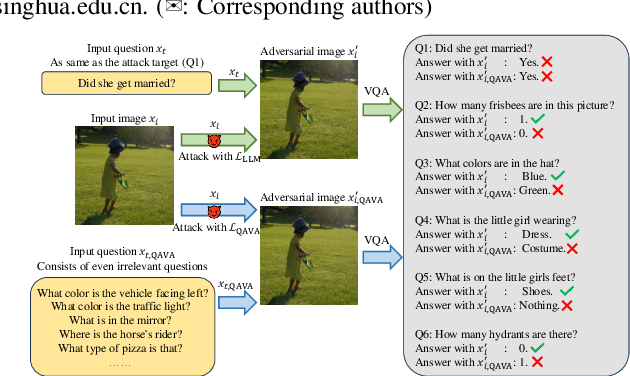
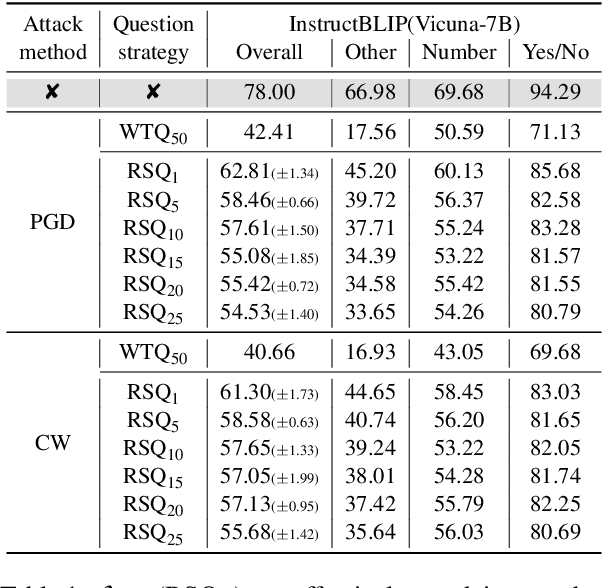
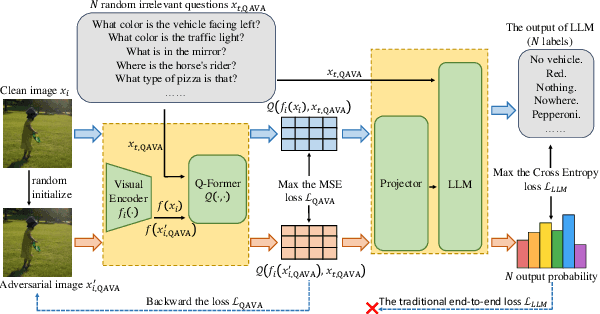
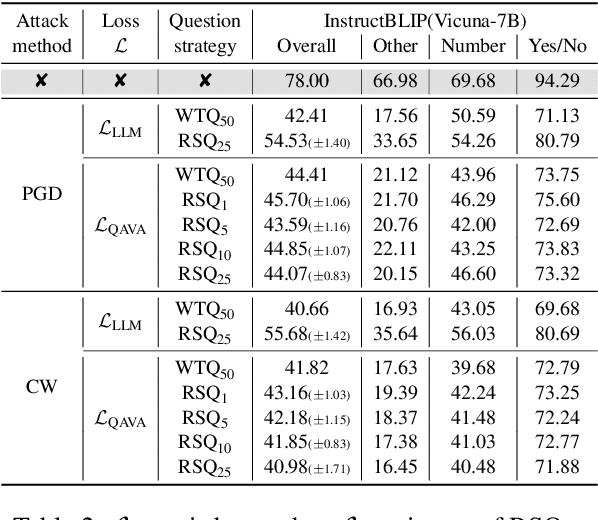
In typical multimodal tasks, such as Visual Question Answering (VQA), adversarial attacks targeting a specific image and question can lead large vision-language models (LVLMs) to provide incorrect answers. However, it is common for a single image to be associated with multiple questions, and LVLMs may still answer other questions correctly even for an adversarial image attacked by a specific question. To address this, we introduce the query-agnostic visual attack (QAVA), which aims to create robust adversarial examples that generate incorrect responses to unspecified and unknown questions. Compared to traditional adversarial attacks focused on specific images and questions, QAVA significantly enhances the effectiveness and efficiency of attacks on images when the question is unknown, achieving performance comparable to attacks on known target questions. Our research broadens the scope of visual adversarial attacks on LVLMs in practical settings, uncovering previously overlooked vulnerabilities, particularly in the context of visual adversarial threats. The code is available at https://github.com/btzyd/qava.
Large Language Model Empowered Recommendation Meets All-domain Continual Pre-Training
Apr 11, 2025Recent research efforts have investigated how to integrate Large Language Models (LLMs) into recommendation, capitalizing on their semantic comprehension and open-world knowledge for user behavior understanding. These approaches predominantly employ supervised fine-tuning on single-domain user interactions to adapt LLMs for specific recommendation tasks. However, they typically encounter dual challenges: the mismatch between general language representations and domain-specific preference patterns, as well as the limited adaptability to multi-domain recommendation scenarios. To bridge these gaps, we introduce CPRec -- an All-domain Continual Pre-Training framework for Recommendation -- designed to holistically align LLMs with universal user behaviors through the continual pre-training paradigm. Specifically, we first design a unified prompt template and organize users' multi-domain behaviors into domain-specific behavioral sequences and all-domain mixed behavioral sequences that emulate real-world user decision logic. To optimize behavioral knowledge infusion, we devise a Warmup-Stable-Annealing learning rate schedule tailored for the continual pre-training paradigm in recommendation to progressively enhance the LLM's capability in knowledge adaptation from open-world knowledge to universal recommendation tasks. To evaluate the effectiveness of our CPRec, we implement it on a large-scale dataset covering seven domains and conduct extensive experiments on five real-world datasets from two distinct platforms. Experimental results confirm that our continual pre-training paradigm significantly mitigates the semantic-behavioral discrepancy and achieves state-of-the-art performance in all recommendation scenarios. The source code will be released upon acceptance.
TransMamba: Flexibly Switching between Transformer and Mamba
Mar 31, 2025Transformers are the cornerstone of modern large language models, but their quadratic computational complexity limits efficiency in long-sequence processing. Recent advancements in Mamba, a state space model (SSM) with linear complexity, offer promising efficiency gains but suffer from unstable contextual learning and multitask generalization. This paper proposes TransMamba, a novel framework that unifies Transformer and Mamba through shared parameter matrices (e.g., QKV and CBx), and thus could dynamically switch between attention and SSM mechanisms at different token lengths and layers. We design the Memory converter to bridge Transformer and Mamba by converting attention outputs into SSM-compatible states, ensuring seamless information flow at TransPoints where the transformation happens. The TransPoint scheduling is also thoroughly explored for further improvements. We conducted extensive experiments demonstrating that TransMamba achieves superior training efficiency and performance compared to baselines, and validated the deeper consistency between Transformer and Mamba paradigms, offering a scalable solution for next-generation sequence modeling.