 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Sketch Animation by Scene Decomposition and Motion Planning
Mar 25, 2025Sketch animation, which brings static sketches to life by generating dynamic video sequences, has found widespread applications in GIF design, cartoon production, and daily entertainment. While current sketch animation methods perform well in single-object sketch animation, they struggle in multi-object scenarios. By analyzing their failures, we summarize two challenges of transitioning from single-object to multi-object sketch animation: object-aware motion modeling and complex motion optimization. For multi-object sketch animation, we propose MoSketch based on iterative optimization through Score Distillation Sampling (SDS), without any other data for training. We propose four modules: LLM-based scene decomposition, LLM-based motion planning, motion refinement network and compositional SDS, to tackle the two challenges in a divide-and-conquer strategy. Extensive qualitative and quantitative experiments demonstrate the superiority of our method over existing sketch animation approaches. MoSketch takes a pioneering step towards multi-object sketch animation, opening new avenues for future research and applications. The code will be released.
Mitigating Hallucination in Multimodal Large Language Model via Hallucination-targeted Direct Preference Optimization
Nov 15, 2024Multimodal Large Language Models (MLLMs) are known to hallucinate, which limits their practical applications. Recent works have attempted to apply Direct Preference Optimization (DPO) to enhance the performance of MLLMs, but have shown inconsistent improvements in mitigating hallucinations. To address this issue more effectively, we introduce Hallucination-targeted Direct Preference Optimization (HDPO) to reduce hallucinations in MLLMs. Unlike previous approaches, our method tackles hallucinations from their diverse forms and causes. Specifically, we develop three types of preference pair data targeting the following causes of MLLM hallucinations: (1) insufficient visual capabilities, (2) long context generation, and (3) multimodal conflicts. Experimental results demonstrate that our method achieves superior performance across multiple hallucination evaluation datasets, surpassing most state-of-the-art (SOTA) methods and highlighting the potential of our approach. Ablation studies and in-depth analyses further confirm the effectiveness of our method and suggest the potential for further improvements through scaling up.
Magnifier Prompt: Tackling Multimodal Hallucination via Extremely Simple Instructions
Oct 15, 2024



Hallucinations in multimodal large language models (MLLMs) hinder their practical applications. To address this, we propose a Magnifier Prompt (MagPrompt), a simple yet effective method to tackle hallucinations in MLLMs via extremely simple instructions. MagPrompt is based on the following two key principles, which guide the design of various effective prompts, demonstrating robustness: (1) MLLMs should focus more on the image. (2) When there are conflicts between the image and the model's inner knowledge, MLLMs should prioritize the image. MagPrompt is training-free and can be applied to open-source and closed-source models, such as GPT-4o and Gemini-pro. It performs well across many datasets and its effectiveness is comparable or even better than more complex methods like VCD. Furthermore, our prompt design principles and experimental analyses provide valuable insights into multimodal hallucination.
PhD: A Prompted Visual Hallucination Evaluation Dataset
Mar 17, 2024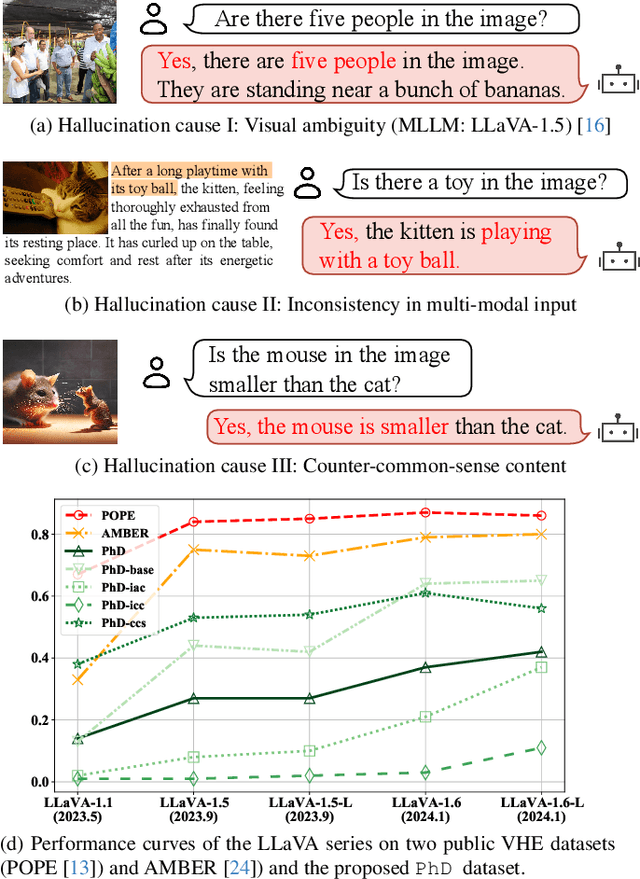

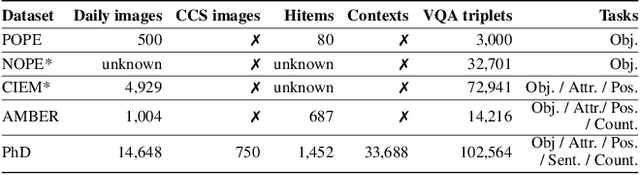

The rapid growth of Large Language Models (LLMs) has driven the development of Large Vision-Language Models (LVLMs). The challenge of hallucination, prevalent in LLMs, also emerges in LVLMs. However, most existing efforts mainly focus on object hallucination in LVLM, ignoring diverse types of LVLM hallucinations. In this study, we delve into the Intrinsic Vision-Language Hallucination (IVL-Hallu) issue, thoroughly analyzing different types of IVL-Hallu on their causes and reflections. Specifically, we propose several novel IVL-Hallu tasks and categorize them into four types: (a) object hallucination, which arises from the misidentification of objects, (b) attribute hallucination, which is caused by the misidentification of attributes, (c) multi-modal conflicting hallucination, which derives from the contradictions between textual and visual information, and (d) counter-common-sense hallucination, which owes to the contradictions between the LVLM knowledge and actual images. Based on these taxonomies, we propose a more challenging benchmark named PhD to evaluate and explore IVL-Hallu. An automated pipeline is proposed for generating different types of IVL-Hallu data. Extensive experiments on five SOTA LVLMs reveal their inability to effectively tackle our proposed IVL-Hallu tasks, with detailed analyses and insights on the origins and possible solutions of these new challenging IVL-Hallu tasks, facilitating future researches on IVL-Hallu and LVLM. The benchmark can be accessed at https://github.com/jiazhen-code/IntrinsicHallu