 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-hallucination Synthetic Captions for Large-Scale Vision-Language Model Pre-training
Apr 17, 2025In recent years, the field of vision-language model pre-training has experienced rapid advancements, driven primarily by the continuous enhancement of textual capabilities in large language models. However, existing training paradigms for multimodal large language models heavily rely on high-quality image-text pairs. As models and data scales grow exponentially, the availability of such meticulously curated data has become increasingly scarce and saturated, thereby severely limiting further advancements in this domain. This study investigates scalable caption generation techniques for vision-language model pre-training and demonstrates that large-scale low-hallucination synthetic captions can serve dual purposes: 1) acting as a viable alternative to real-world data for pre-training paradigms and 2) achieving superior performance enhancement when integrated into vision-language models through empirical validation. This paper presents three key contributions: 1) a novel pipeline for generating high-quality, low-hallucination, and knowledge-rich synthetic captions. Our continuous DPO methodology yields remarkable results in reducing hallucinations. Specifically, the non-hallucination caption rate on a held-out test set increases from 48.2% to 77.9% for a 7B-size model. 2) Comprehensive empirical validation reveals that our synthetic captions confer superior pre-training advantages over their counterparts. Across 35 vision language tasks, the model trained with our data achieves a significant performance gain of at least 6.2% compared to alt-text pairs and other previous work. Meanwhile, it also offers considerable support in the text-to-image domain. With our dataset, the FID score is reduced by 17.1 on a real-world validation benchmark and 13.3 on the MSCOCO validation benchmark. 3) We will release Hunyuan-Recap100M, a low-hallucination and knowledge-intensive synthetic caption dataset.
PhD: A Prompted Visual Hallucination Evaluation Dataset
Mar 17, 2024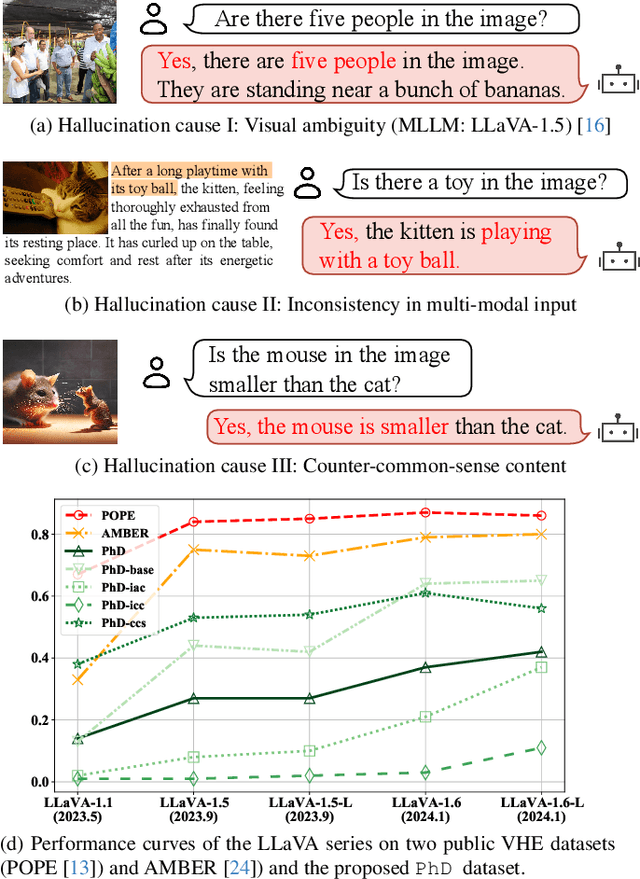

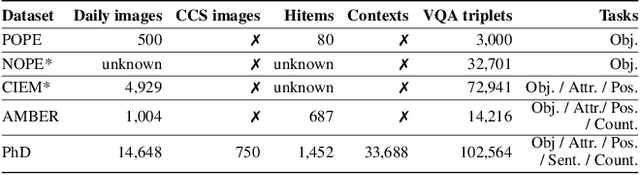

The rapid growth of Large Language Models (LLMs) has driven the development of Large Vision-Language Models (LVLMs). The challenge of hallucination, prevalent in LLMs, also emerges in LVLMs. However, most existing efforts mainly focus on object hallucination in LVLM, ignoring diverse types of LVLM hallucinations. In this study, we delve into the Intrinsic Vision-Language Hallucination (IVL-Hallu) issue, thoroughly analyzing different types of IVL-Hallu on their causes and reflections. Specifically, we propose several novel IVL-Hallu tasks and categorize them into four types: (a) object hallucination, which arises from the misidentification of objects, (b) attribute hallucination, which is caused by the misidentification of attributes, (c) multi-modal conflicting hallucination, which derives from the contradictions between textual and visual information, and (d) counter-common-sense hallucination, which owes to the contradictions between the LVLM knowledge and actual images. Based on these taxonomies, we propose a more challenging benchmark named PhD to evaluate and explore IVL-Hallu. An automated pipeline is proposed for generating different types of IVL-Hallu data. Extensive experiments on five SOTA LVLMs reveal their inability to effectively tackle our proposed IVL-Hallu tasks, with detailed analyses and insights on the origins and possible solutions of these new challenging IVL-Hallu tasks, facilitating future researches on IVL-Hallu and LVLM. The benchmark can be accessed at https://github.com/jiazhen-code/IntrinsicHallu
TeachCLIP: Multi-Grained Teaching for Efficient Text-to-Video Retrieval
Aug 02, 2023For text-to-video retrieval (T2VR), which aims to retrieve unlabeled videos by ad-hoc textual queries, CLIP-based methods are dominating. Compared to CLIP4Clip which is efficient and compact, the state-of-the-art models tend to compute video-text similarity by fine-grained cross-modal feature interaction and matching, putting their scalability for large-scale T2VR into doubt. For efficient T2VR, we propose TeachCLIP with multi-grained teaching to let a CLIP4Clip based student network learn from more advanced yet computationally heavy models such as X-CLIP, TS2-Net and X-Pool . To improve the student's learning capability, we add an Attentional frame-Feature Aggregation (AFA) block, which by design adds no extra storage/computation overhead at the retrieval stage. While attentive weights produced by AFA are commonly used for combining frame-level features, we propose a novel use of the weights to let them imitate frame-text relevance estimated by the teacher network. As such, AFA provides a fine-grained learning (teaching) channel for the student (teacher). Extensive experiments on multiple public datasets justify the viability of the proposed method.