 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhD: A Prompted Visual Hallucination Evaluation Dataset
Paper and Code
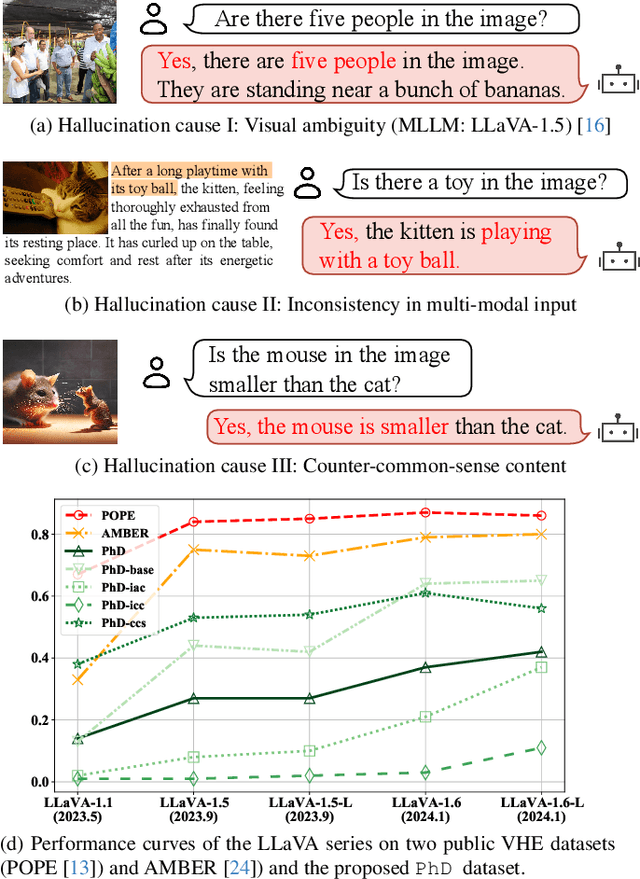

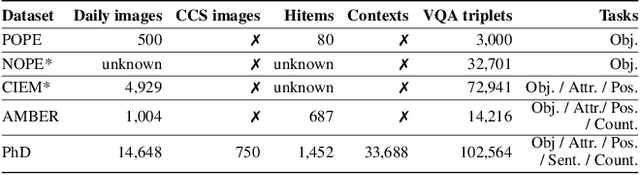

The rapid growth of Large Language Models (LLMs) has driven the development of Large Vision-Language Models (LVLMs). The challenge of hallucination, prevalent in LLMs, also emerges in LVLMs. However, most existing efforts mainly focus on object hallucination in LVLM, ignoring diverse types of LVLM hallucinations. In this study, we delve into the Intrinsic Vision-Language Hallucination (IVL-Hallu) issue, thoroughly analyzing different types of IVL-Hallu on their causes and reflections. Specifically, we propose several novel IVL-Hallu tasks and categorize them into four types: (a) object hallucination, which arises from the misidentification of objects, (b) attribute hallucination, which is caused by the misidentification of attributes, (c) multi-modal conflicting hallucination, which derives from the contradictions between textual and visual information, and (d) counter-common-sense hallucination, which owes to the contradictions between the LVLM knowledge and actual images. Based on these taxonomies, we propose a more challenging benchmark named PhD to evaluate and explore IVL-Hallu. An automated pipeline is proposed for generating different types of IVL-Hallu data. Extensive experiments on five SOTA LVLMs reveal their inability to effectively tackle our proposed IVL-Hallu tasks, with detailed analyses and insights on the origins and possible solutions of these new challenging IVL-Hallu tasks, facilitating future researches on IVL-Hallu and LVLM. The benchmark can be accessed at https://github.com/jiazhen-code/IntrinsicHallu