 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraLogic: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
Jan 06, 2026While Large Language Models (LLMs) have demonstrated significant potential in natural language processing , complex general-purpose reasoning requiring multi-step logic, planning, and verification remains a critical bottleneck. Although Reinforcement Learning with Verifiable Rewards (RLVR) has succeeded in specific domains , the field lacks large-scale, high-quality, and difficulty-calibrated data for general reasoning. To address this, we propose UltraLogic, a framework that decouples the logical core of a problem from its natural language expression through a Code-based Solving methodology to automate high-quality data production. The framework comprises hundreds of unique task types and an automated calibration pipeline across ten difficulty levels. Furthermore, to mitigate binary reward sparsity and the Non-negative Reward Trap, we introduce the Bipolar Float Reward (BFR) mechanism, utilizing graded penalties to effectively distinguish perfect responses from those with logical flaws. Our experiments demonstrate that task diversity is the primary driver for reasoning enhancement , and that BFR, combined with a difficulty matching strategy, significantly improves training efficiency, guiding models toward global logical optima.
AutoCodeBench: Large Language Models are Automatic Code Benchmark Generators
Aug 12, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, with code generation emerging as a key area of focus. While numerous benchmarks have been proposed to evaluate their code generation abilities, these benchmarks face several critical limitations. First, they often rely on manual annotations, which are time-consuming and difficult to scale across different programming languages and problem complexities. Second, most existing benchmarks focus primarily on Python, while the few multilingual benchmarks suffer from limited difficulty and uneven language distribution. To address these challenges, we propose AutoCodeGen, an automated method for generating high-difficulty multilingual code generation datasets without manual annotations. AutoCodeGen ensures the correctness and completeness of test cases by generating test inputs with LLMs and obtaining test outputs through a multilingual sandbox, while achieving high data quality through reverse-order problem generation and multiple filtering steps. Using this novel method, we introduce AutoCodeBench, a large-scale code generation benchmark comprising 3,920 problems evenly distributed across 20 programming languages. It is specifically designed to evaluate LLMs on challenging, diverse, and practical multilingual tasks. We evaluate over 30 leading open-source and proprietary LLMs on AutoCodeBench and its simplified version AutoCodeBench-Lite. The results show that even the most advanced LLMs struggle with the complexity, diversity, and multilingual nature of these tasks. Besides, we introduce AutoCodeBench-Complete, specifically designed for base models to assess their few-shot code generation capabilities. We hope the AutoCodeBench series will serve as a valuable resource and inspire the community to focus on more challenging and practical multilingual code generation scenarios.
Adaptive Termination for Multi-round Parallel Reasoning: An Universal Semantic Entropy-Guided Framework
Jul 09, 2025Recent advances in large language models (LLMs) have accelerated progress toward artificial general intelligence, with inference-time scaling emerging as a key technique. Contemporary approaches leverage either sequential reasoning (iteratively extending chains of thought) or parallel reasoning (generating multiple solutions simultaneously) to scale inference. However, both paradigms face fundamental limitations: sequential scaling typically relies on arbitrary token budgets for termination, leading to inefficiency or premature cutoff; while parallel scaling often lacks coordination among parallel branches and requires intrusive fine-tuning to perform effectively. In light of these challenges, we aim to design a flexible test-time collaborative inference framework that exploits the complementary strengths of both sequential and parallel reasoning paradigms. Towards this goal, the core challenge lies in developing an efficient and accurate intrinsic quality metric to assess model responses during collaborative inference, enabling dynamic control and early termination of the reasoning trace. To address this challenge, we introduce semantic entropy (SE), which quantifies the semantic diversity of parallel model responses and serves as a robust indicator of reasoning quality due to its strong negative correlation with accuracy...
Adaptive Deep Reasoning: Triggering Deep Thinking When Needed
May 26, 2025Large language models (LLMs) have shown impressive capabilities in handling complex tasks through long-chain reasoning. However, the extensive reasoning steps involved can significantly increase computational costs, posing challenges for real-world deployment. Recent efforts have focused on optimizing reasoning efficiency by shortening the Chain-of-Thought (CoT) reasoning processes through various approaches, such as length-aware prompt engineering, supervised fine-tuning on CoT data with variable lengths, and reinforcement learning with length penalties. Although these methods effectively reduce reasoning length, they still necessitate an initial reasoning phase. More recent approaches have attempted to integrate long-chain and short-chain reasoning abilities into a single model, yet they still rely on manual control to toggle between short and long CoT.In this work, we propose a novel approach that autonomously switches between short and long reasoning chains based on problem complexity. Our method begins with supervised fine-tuning of the base model to equip both long-chain and short-chain reasoning abilities. We then employ reinforcement learning to further balance short and long CoT generation while maintaining accuracy through two key strategies: first, integrating reinforcement learning with a long-short adaptive group-wise reward strategy to assess prompt complexity and provide corresponding rewards; second, implementing a logit-based reasoning mode switching loss to optimize the model's initial token choice, thereby guiding the selection of the reasoning type.Evaluations on mathematical datasets demonstrate that our model can dynamically switch between long-chain and short-chain reasoning modes without substantially sacrificing performance. This advancement enhances the practicality of reasoning in large language models for real-world applications.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Diverse and Fine-Grained Instruction-Following Ability Exploration with Synthetic Data
Jul 04, 2024



Instruction-following is particularly crucial for large language models (LLMs) to support diverse user requests. While existing work has made progress in aligning LLMs with human preferences, evaluating their capabilities on instruction following remains a challenge due to complexity and diversity of real-world user instructions. While existing evaluation methods focus on general skills, they suffer from two main shortcomings, i.e., lack of fine-grained task-level evaluation and reliance on singular instruction expression. To address these problems, this paper introduces DINGO, a fine-grained and diverse instruction-following evaluation dataset that has two main advantages: (1) DINGO is based on a manual annotated, fine-grained and multi-level category tree with 130 nodes derived from real-world user requests; (2) DINGO includes diverse instructions, generated by both GPT-4 and human experts. Through extensive experiments, we demonstrate that DINGO can not only provide more challenging and comprehensive evaluation for LLMs, but also provide task-level fine-grained directions to further improve LLMs.
PhD: A Prompted Visual Hallucination Evaluation Dataset
Mar 17, 2024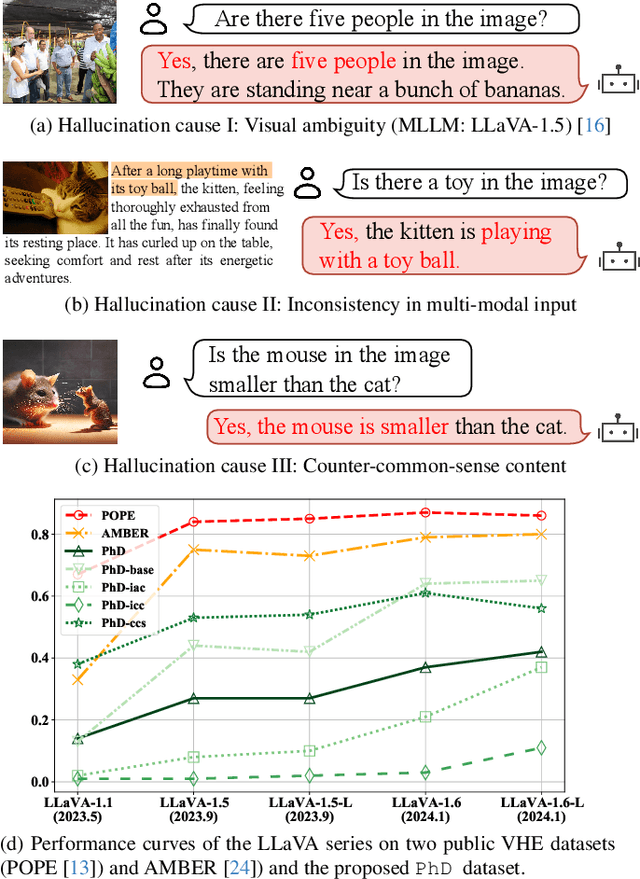

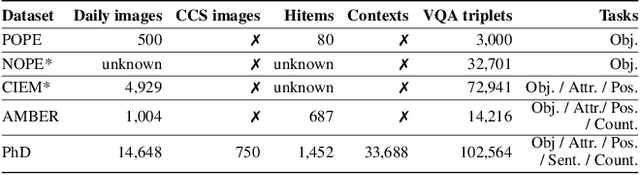

The rapid growth of Large Language Models (LLMs) has driven the development of Large Vision-Language Models (LVLMs). The challenge of hallucination, prevalent in LLMs, also emerges in LVLMs. However, most existing efforts mainly focus on object hallucination in LVLM, ignoring diverse types of LVLM hallucinations. In this study, we delve into the Intrinsic Vision-Language Hallucination (IVL-Hallu) issue, thoroughly analyzing different types of IVL-Hallu on their causes and reflections. Specifically, we propose several novel IVL-Hallu tasks and categorize them into four types: (a) object hallucination, which arises from the misidentification of objects, (b) attribute hallucination, which is caused by the misidentification of attributes, (c) multi-modal conflicting hallucination, which derives from the contradictions between textual and visual information, and (d) counter-common-sense hallucination, which owes to the contradictions between the LVLM knowledge and actual images. Based on these taxonomies, we propose a more challenging benchmark named PhD to evaluate and explore IVL-Hallu. An automated pipeline is proposed for generating different types of IVL-Hallu data. Extensive experiments on five SOTA LVLMs reveal their inability to effectively tackle our proposed IVL-Hallu tasks, with detailed analyses and insights on the origins and possible solutions of these new challenging IVL-Hallu tasks, facilitating future researches on IVL-Hallu and LVLM. The benchmark can be accessed at https://github.com/jiazhen-code/IntrinsicHallu
Truth Forest: Toward Multi-Scale Truthfulness in Large Language Models through Intervention without Tuning
Dec 29, 2023Despite the great success of large language models (LLMs) in various tasks, they suffer from generating hallucinations. We introduce Truth Forest, a method that enhances truthfulness in LLMs by uncovering hidden truth representations using multi-dimensional orthogonal probes. Specifically, it creates multiple orthogonal bases for modeling truth by incorporating orthogonal constraints into the probes. Moreover, we introduce Random Peek, a systematic technique considering an extended range of positions within the sequence, reducing the gap between discerning and generating truth features in LLMs. By employing this approach, we improved the truthfulness of Llama-2-7B from 40.8\% to 74.5\% on TruthfulQA. Likewise, significant improvements are observed in fine-tuned models. We conducted a thorough analysis of truth features using probes. Our visualization results show that orthogonal probes capture complementary truth-related features, forming well-defined clusters that reveal the inherent structure of the dataset. Code: \url{https://github.com/jongjyh/trfr}
Thoroughly Modeling Multi-domain Pre-trained Recommendation as Language
Oct 20, 2023



With the thriving of pre-trained language model (PLM) widely verified in various of NLP tasks, pioneer efforts attempt to explore the possible cooperation of the general textual information in PLM with the personalized behavioral information in user historical behavior sequences to enhance sequential recommendation (SR). However, despite the commonalities of input format and task goal, there are huge gaps between the behavioral and textual information, which obstruct thoroughly modeling SR as language modeling via PLM. To bridge the gap, we propose a novel Unified pre-trained language model enhanced sequential recommendation (UPSR), aiming to build a unified pre-trained recommendation model for multi-domain recommendation tasks. We formally design five key indicators, namely naturalness, domain consistency, informativeness, noise & ambiguity, and text length, to guide the text->item adaptation and behavior sequence->text sequence adaptation differently for pre-training and fine-tuning stages, which are essential but under-explored by previous works. In experiments, we conduct extensive evaluations on seven datasets with both tuning and zero-shot settings and achieve the overall best performance. Comprehensive model analyses also provide valuable insights for behavior modeling via PLM, shedding light on large pre-trained recommendation models. The source codes will be released in the future.