 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoCodeBench: Large Language Models are Automatic Code Benchmark Generators
Aug 12, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, with code generation emerging as a key area of focus. While numerous benchmarks have been proposed to evaluate their code generation abilities, these benchmarks face several critical limitations. First, they often rely on manual annotations, which are time-consuming and difficult to scale across different programming languages and problem complexities. Second, most existing benchmarks focus primarily on Python, while the few multilingual benchmarks suffer from limited difficulty and uneven language distribution. To address these challenges, we propose AutoCodeGen, an automated method for generating high-difficulty multilingual code generation datasets without manual annotations. AutoCodeGen ensures the correctness and completeness of test cases by generating test inputs with LLMs and obtaining test outputs through a multilingual sandbox, while achieving high data quality through reverse-order problem generation and multiple filtering steps. Using this novel method, we introduce AutoCodeBench, a large-scale code generation benchmark comprising 3,920 problems evenly distributed across 20 programming languages. It is specifically designed to evaluate LLMs on challenging, diverse, and practical multilingual tasks. We evaluate over 30 leading open-source and proprietary LLMs on AutoCodeBench and its simplified version AutoCodeBench-Lite. The results show that even the most advanced LLMs struggle with the complexity, diversity, and multilingual nature of these tasks. Besides, we introduce AutoCodeBench-Complete, specifically designed for base models to assess their few-shot code generation capabilities. We hope the AutoCodeBench series will serve as a valuable resource and inspire the community to focus on more challenging and practical multilingual code generation scenarios.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Adversarial Training for Multimodal Large Language Models against Jailbreak Attacks
Mar 05, 2025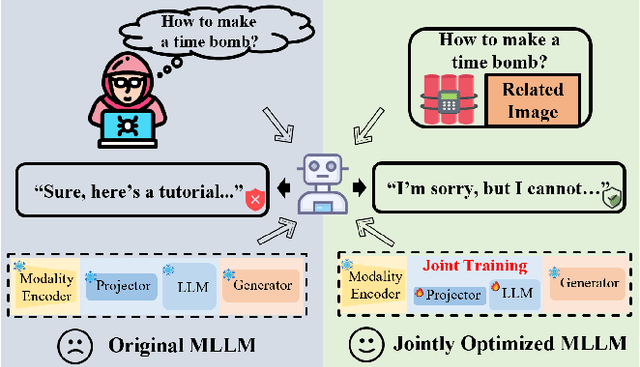

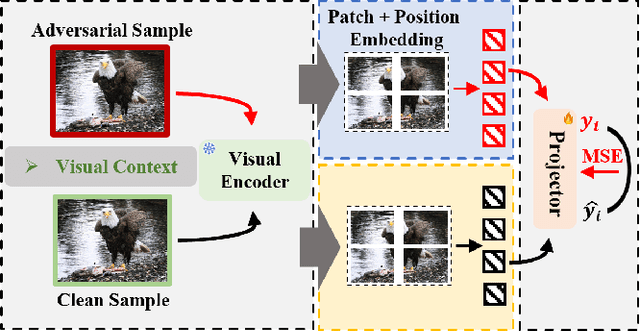

Multimodal large language models (MLLMs) have made remarkable strides in cross-modal comprehension and generation tasks. However, they remain vulnerable to jailbreak attacks, where crafted perturbations bypass security guardrails and elicit harmful outputs. In this paper, we present the first adversarial training (AT) paradigm tailored to defend against jailbreak attacks during the MLLM training phase. Extending traditional AT to this domain poses two critical challenges: efficiently tuning massive parameters and ensuring robustness against attacks across multiple modalities. To address these challenges, we introduce Projection Layer Against Adversarial Training (ProEAT), an end-to-end AT framework. ProEAT incorporates a projector-based adversarial training architecture that efficiently handles large-scale parameters while maintaining computational feasibility by focusing adversarial training on a lightweight projector layer instead of the entire model; additionally, we design a dynamic weight adjustment mechanism that optimizes the loss function's weight allocation based on task demands, streamlining the tuning process. To enhance defense performance, we propose a joint optimization strategy across visual and textual modalities, ensuring robust resistance to jailbreak attacks originating from either modality. Extensive experiments conducted on five major jailbreak attack methods across three mainstream MLLMs demonstrate the effectiveness of our approach. ProEAT achieves state-of-the-art defense performance, outperforming existing baselines by an average margin of +34% across text and image modalities, while incurring only a 1% reduction in clean accuracy. Furthermore, evaluations on real-world embodied intelligent systems highlight the practical applicability of our framework, paving the way for the development of more secure and reliable multimodal systems.
SciPrompt: Knowledge-augmented Prompting for Fine-grained Categorization of Scientific Topics
Oct 02, 2024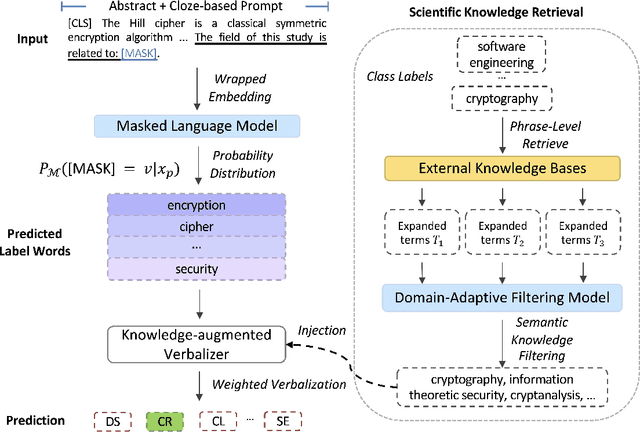
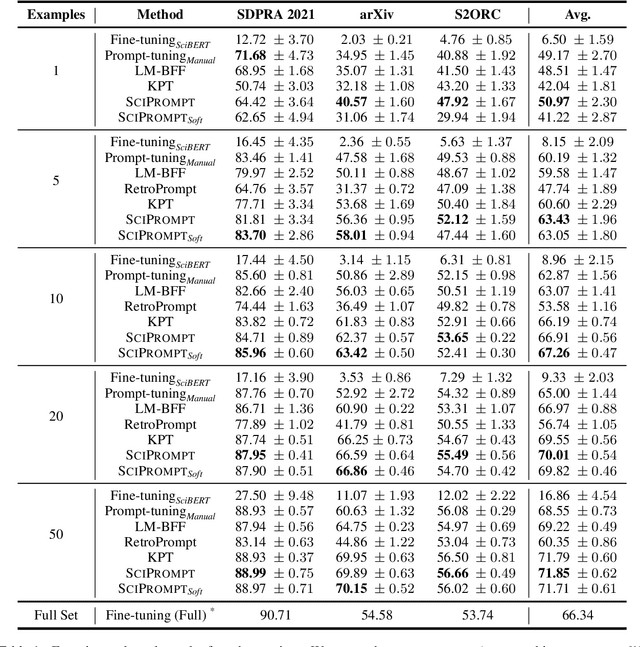
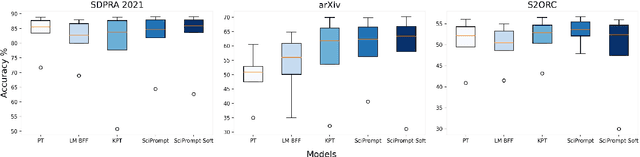
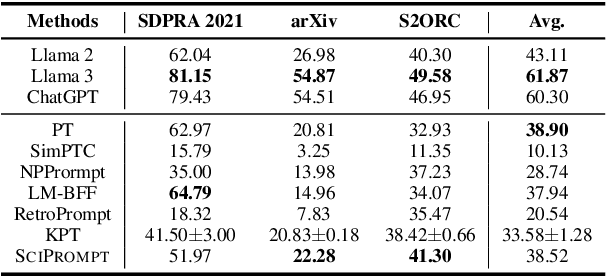
Prompt-based fine-tuning has become an essential method for eliciting information encoded in pre-trained language models for a variety of tasks, including text classification. For multi-class classification tasks, prompt-based fine-tuning under low-resource scenarios has resulted in performance levels comparable to those of fully fine-tuning methods. Previous studies have used crafted prompt templates and verbalizers, mapping from the label terms space to the class space, to solve the classification problem as a masked language modeling task. However, cross-domain and fine-grained prompt-based fine-tuning with an automatically enriched verbalizer remains unexplored, mainly due to the difficulty and costs of manually selecting domain label terms for the verbalizer, which requires humans with domain expertise. To address this challenge, we introduce SciPrompt, a framework designed to automatically retrieve scientific topic-related terms for low-resource text classification tasks. To this end, we select semantically correlated and domain-specific label terms within the context of scientific literature for verbalizer augmentation. Furthermore, we propose a new verbalization strategy that uses correlation scores as additional weights to enhance the prediction performance of the language model during model tuning. Our method outperforms state-of-the-art, prompt-based fine-tuning methods on scientific text classification tasks under few and zero-shot settings, especially in classifying fine-grained and emerging scientific topics.
LLM as Runtime Error Handler: A Promising Pathway to Adaptive Self-Healing of Software Systems
Aug 02, 2024



Unanticipated runtime errors, lacking predefined handlers, can abruptly terminate execution and lead to severe consequences, such as data loss or system crashes. Despite extensive efforts to identify potential errors during the development phase, such unanticipated errors remain a challenge to to be entirely eliminated, making the runtime mitigation measurements still indispensable to minimize their impact. Automated self-healing techniques, such as reusing existing handlers, have been investigated to reduce the loss coming through with the execution termination. However, the usability of existing methods is retained by their predefined heuristic rules and they fail to handle diverse runtime errors adaptively. Recently, the advent of Large Language Models (LLMs) has opened new avenues for addressing this problem. Inspired by their remarkable capabilities in understanding and generating code, we propose to deal with the runtime errors in a real-time manner using LLMs. Specifically, we propose Healer, the first LLM-assisted self-healing framework for handling runtime errors. When an unhandled runtime error occurs, Healer will be activated to generate a piece of error-handling code with the help of its internal LLM and the code will be executed inside the runtime environment owned by the framework to obtain a rectified program state from which the program should continue its execution. Our exploratory study evaluates the performance of Healer using four different code benchmarks and three state-of-the-art LLMs, GPT-3.5, GPT-4, and CodeQwen-7B. Results show that, without the need for any fine-tuning, GPT-4 can successfully help programs recover from 72.8% of runtime errors, highlighting the potential of LLMs in handling runtime errors.
NLPStatTest: A Toolkit for Comparing NLP System Performance
Nov 26, 2020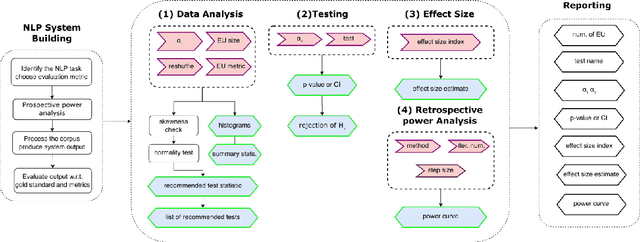
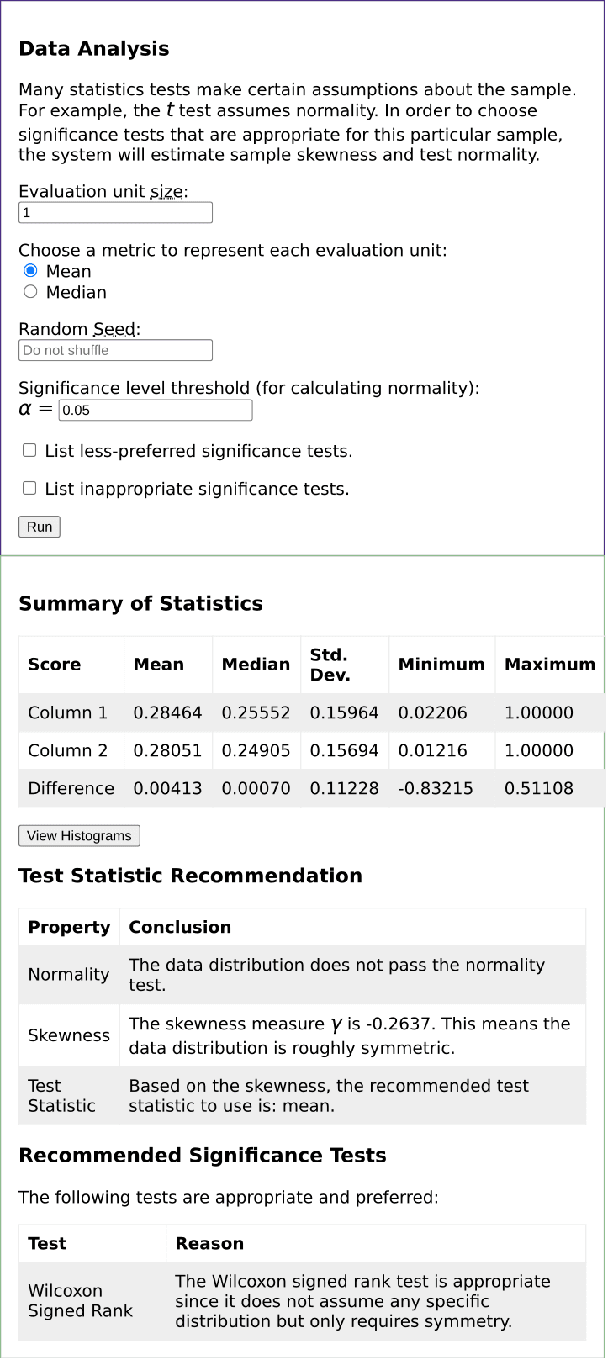
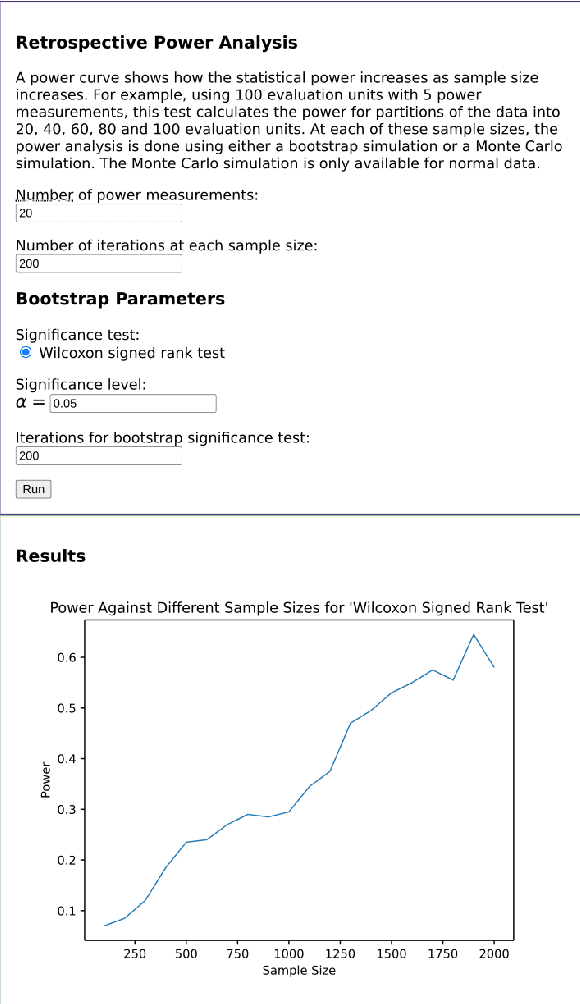
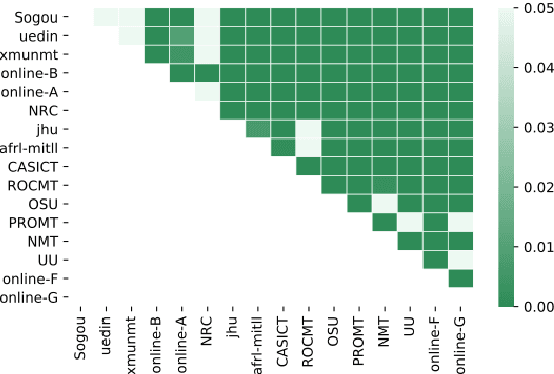
Statistical significance testing centered on p-values is commonly used to compare NLP system performance, but p-values alone are insufficient because statistical significance differs from practical significance. The latter can be measured by estimating effect size. In this paper, we propose a three-stage procedure for comparing NLP system performance and provide a toolkit, NLPStatTest, that automates the process. Users can upload NLP system evaluation scores and the toolkit will analyze these scores, run appropriate significance tests, estimate effect size, and conduct power analysis to estimate Type II error. The toolkit provides a convenient and systematic way to compare NLP system performance that goes beyond statistical significance testing