 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlainQAFact: Automatic Factuality Evaluation Metric for Biomedical Plain Language Summaries Generation
Mar 11, 2025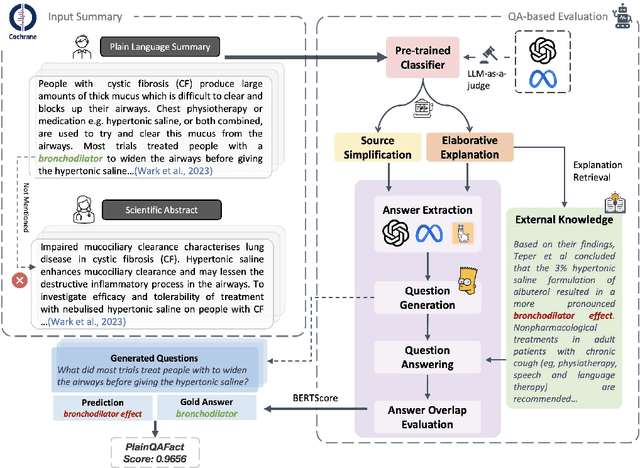
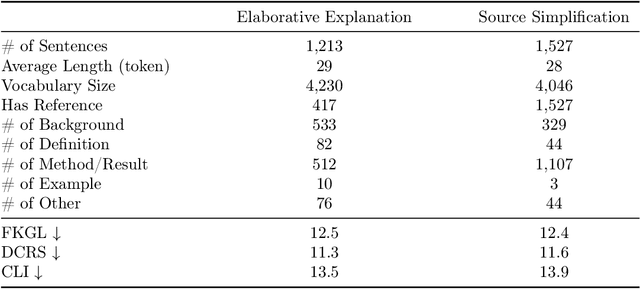
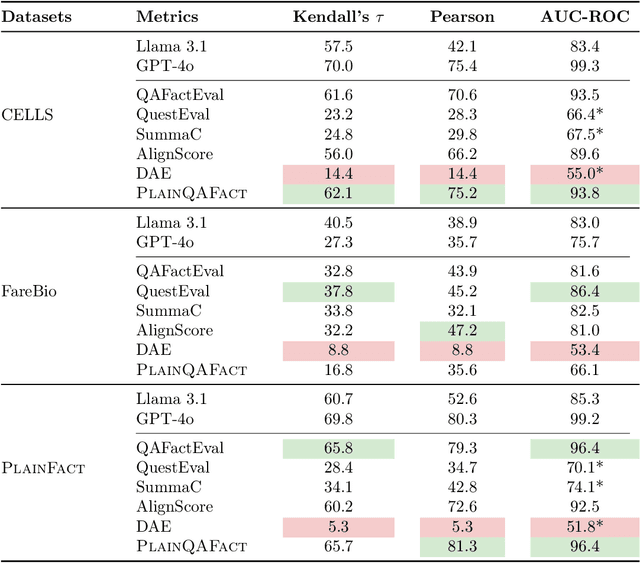
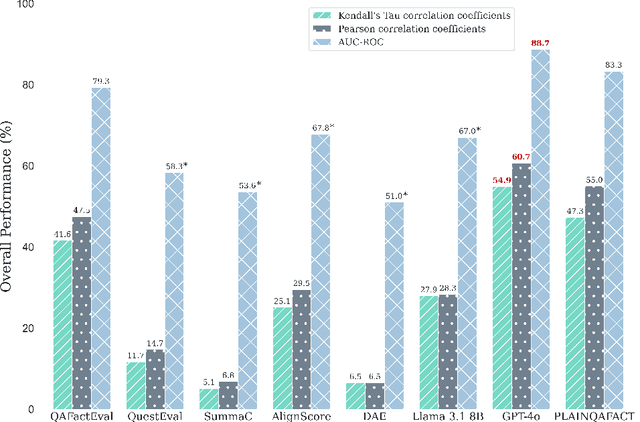
Hallucinated outputs from language models pose risks in the medical domain, especially for lay audiences making health-related decisions. Existing factuality evaluation methods, such as entailment- and question-answering-based (QA), struggle with plain language summary (PLS) generation due to elaborative explanation phenomenon, which introduces external content (e.g., definitions, background, examples) absent from the source document to enhance comprehension. To address this, we introduce PlainQAFact, a framework trained on a fine-grained, human-annotated dataset PlainFact, to evaluate the factuality of both source-simplified and elaboratively explained sentences. PlainQAFact first classifies factuality type and then assesses factuality using a retrieval-augmented QA-based scoring method. Our approach is lightweight and computationally efficient. Empirical results show that existing factuality metrics fail to effectively evaluate factuality in PLS, especially for elaborative explanations, whereas PlainQAFact achieves state-of-the-art performance. We further analyze its effectiveness across external knowledge sources, answer extraction strategies, overlap measures, and document granularity levels, refining its overall factuality assessment.
Application of machine learning algorithm in temperature field reconstruction
Feb 18, 2025This study focuses on the stratification patterns and dynamic evolution of reservoir water temperatures, aiming to estimate and reconstruct the temperature field using limited and noisy local measurement data. Due to complex measurement environments and technical limitations, obtaining complete temperature information for reservoirs is highly challenging. Therefore, accurately reconstructing the temperature field from a small number of local data points has become a critical scientific issue. To address this, the study employs Proper Orthogonal Decomposition (POD) and sparse representation methods to reconstruct the temperature field based on temperature data from a limited number of local measurement points. The results indicate that satisfactory reconstruction can be achieved when the number of POD basis functions is set to 2 and the number of measurement points is 10. Under different water intake depths, the reconstruction errors of both POD and sparse representation methods remain stable at around 0.15, fully validating the effectiveness of these methods in reconstructing the temperature field based on limited local temperature data. Additionally, the study further explores the distribution characteristics of reconstruction errors for POD and sparse representation methods under different water level intervals, analyzing the optimal measurement point layout scheme and potential limitations of the reconstruction methods in this case. This research not only effectively reduces measurement costs and computational resource consumption but also provides a new technical approach for reservoir temperature analysis, holding significant theoretical and practical importance.
Revisiting gender bias research in bibliometrics: Standardizing methodological variability using Scholarly Data Analysis (SoDA) Cards
Jan 30, 2025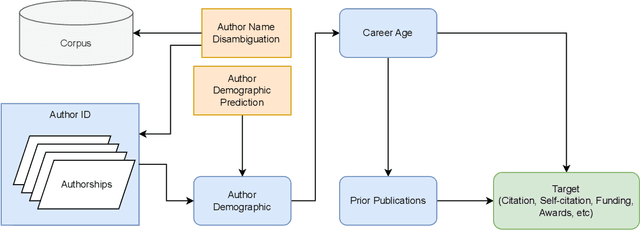



Gender biases in scholarly metrics remain a persistent concern, despite numerous bibliometric studies exploring their presence and absence across productivity, impact, acknowledgment, and self-citations. However, methodological inconsistencies, particularly in author name disambiguation and gender identification, limit the reliability and comparability of these studies, potentially perpetuating misperceptions and hindering effective interventions. A review of 70 relevant publications over the past 12 years reveals a wide range of approaches, from name-based and manual searches to more algorithmic and gold-standard methods, with no clear consensus on best practices. This variability, compounded by challenges such as accurately disambiguating Asian names and managing unassigned gender labels, underscores the urgent need for standardized and robust methodologies. To address this critical gap, we propose the development and implementation of ``Scholarly Data Analysis (SoDA) Cards." These cards will provide a structured framework for documenting and reporting key methodological choices in scholarly data analysis, including author name disambiguation and gender identification procedures. By promoting transparency and reproducibility, SoDA Cards will facilitate more accurate comparisons and aggregations of research findings, ultimately supporting evidence-informed policymaking and enabling the longitudinal tracking of analytical approaches in the study of gender and other social biases in academia.
SciPrompt: Knowledge-augmented Prompting for Fine-grained Categorization of Scientific Topics
Oct 02, 2024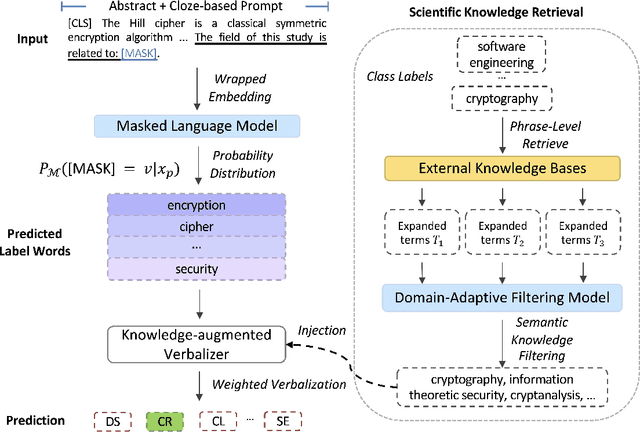
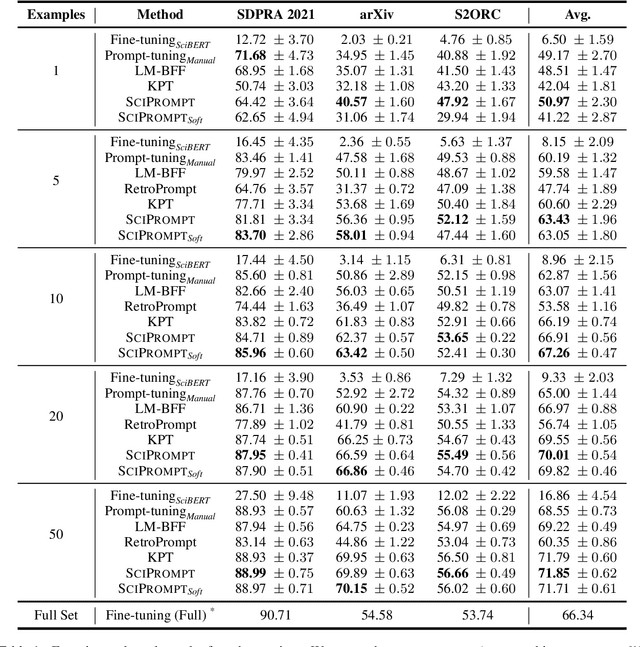
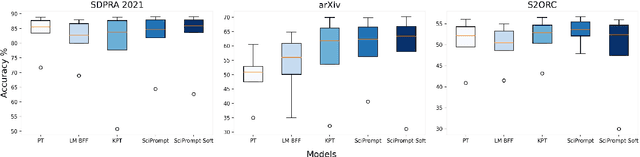
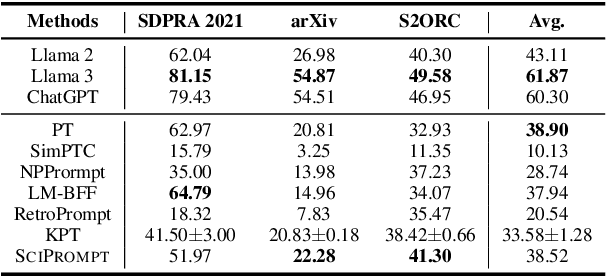
Prompt-based fine-tuning has become an essential method for eliciting information encoded in pre-trained language models for a variety of tasks, including text classification. For multi-class classification tasks, prompt-based fine-tuning under low-resource scenarios has resulted in performance levels comparable to those of fully fine-tuning methods. Previous studies have used crafted prompt templates and verbalizers, mapping from the label terms space to the class space, to solve the classification problem as a masked language modeling task. However, cross-domain and fine-grained prompt-based fine-tuning with an automatically enriched verbalizer remains unexplored, mainly due to the difficulty and costs of manually selecting domain label terms for the verbalizer, which requires humans with domain expertise. To address this challenge, we introduce SciPrompt, a framework designed to automatically retrieve scientific topic-related terms for low-resource text classification tasks. To this end, we select semantically correlated and domain-specific label terms within the context of scientific literature for verbalizer augmentation. Furthermore, we propose a new verbalization strategy that uses correlation scores as additional weights to enhance the prediction performance of the language model during model tuning. Our method outperforms state-of-the-art, prompt-based fine-tuning methods on scientific text classification tasks under few and zero-shot settings, especially in classifying fine-grained and emerging scientific topics.
Beyond Binary Gender Labels: Revealing Gender Biases in LLMs through Gender-Neutral Name Predictions
Jul 07, 2024Name-based gender prediction has traditionally categorized individuals as either female or male based on their names, using a binary classification system. That binary approach can be problematic in the cases of gender-neutral names that do not align with any one gender, among other reasons. Relying solely on binary gender categories without recognizing gender-neutral names can reduce the inclusiveness of gender prediction tasks. We introduce an additional gender category, i.e., "neutral", to study and address potential gender biases in Large Language Models (LLMs). We evaluate the performance of several foundational and large language models in predicting gender based on first names only. Additionally, we investigate the impact of adding birth years to enhance the accuracy of gender prediction, accounting for shifting associations between names and genders over time. Our findings indicate that most LLMs identify male and female names with high accuracy (over 80%) but struggle with gender-neutral names (under 40%), and the accuracy of gender prediction is higher for English-based first names than non-English names. The experimental results show that incorporating the birth year does not improve the overall accuracy of gender prediction, especially for names with evolving gender associations. We recommend using caution when applying LLMs for gender identification in downstream tasks, particularly when dealing with non-binary gender labels.