 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-guided Plan and Retrieval: A Strategic Alignment for Interpretable User Satisfaction Estimation in Dialogue
Mar 06, 2025
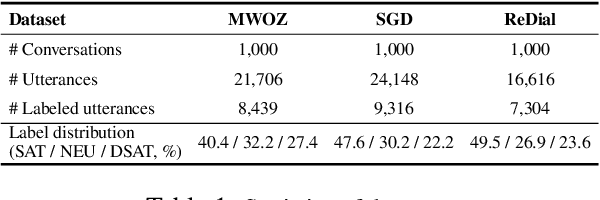

Understanding user satisfaction with conversational systems, known as User Satisfaction Estimation (USE), is essential for assessing dialogue quality and enhancing user experiences. However, existing methods for USE face challenges due to limited understanding of underlying reasons for user dissatisfaction and the high costs of annotating user intentions. To address these challenges, we propose PRAISE (Plan and Retrieval Alignment for Interpretable Satisfaction Estimation), an interpretable framework for effective user satisfaction prediction. PRAISE operates through three key modules. The Strategy Planner develops strategies, which are natural language criteria for classifying user satisfaction. The Feature Retriever then incorporates knowledge on user satisfaction from Large Language Models (LLMs) and retrieves relevance features from utterances. Finally, the Score Analyzer evaluates strategy predictions and classifies user satisfaction. Experimental results demonstrate that PRAISE achieves state-of-the-art performance on three benchmarks for the USE task. Beyond its superior performance, PRAISE offers additional benefits. It enhances interpretability by providing instance-level explanations through effective alignment of utterances with strategies. Moreover, PRAISE operates more efficiently than existing approaches by eliminating the need for LLMs during the inference phase.
Revisiting gender bias research in bibliometrics: Standardizing methodological variability using Scholarly Data Analysis (SoDA) Cards
Jan 30, 2025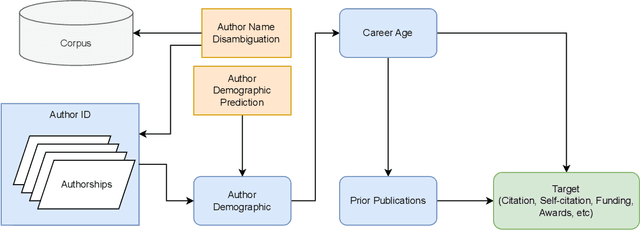



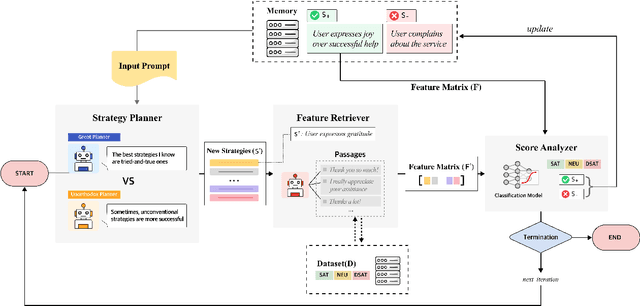
Gender biases in scholarly metrics remain a persistent concern, despite numerous bibliometric studies exploring their presence and absence across productivity, impact, acknowledgment, and self-citations. However, methodological inconsistencies, particularly in author name disambiguation and gender identification, limit the reliability and comparability of these studies, potentially perpetuating misperceptions and hindering effective interventions. A review of 70 relevant publications over the past 12 years reveals a wide range of approaches, from name-based and manual searches to more algorithmic and gold-standard methods, with no clear consensus on best practices. This variability, compounded by challenges such as accurately disambiguating Asian names and managing unassigned gender labels, underscores the urgent need for standardized and robust methodologies. To address this critical gap, we propose the development and implementation of ``Scholarly Data Analysis (SoDA) Cards." These cards will provide a structured framework for documenting and reporting key methodological choices in scholarly data analysis, including author name disambiguation and gender identification procedures. By promoting transparency and reproducibility, SoDA Cards will facilitate more accurate comparisons and aggregations of research findings, ultimately supporting evidence-informed policymaking and enabling the longitudinal tracking of analytical approaches in the study of gender and other social biases in academia.
AMXFP4: Taming Activation Outliers with Asymmetric Microscaling Floating-Point for 4-bit LLM Inference
Nov 15, 2024
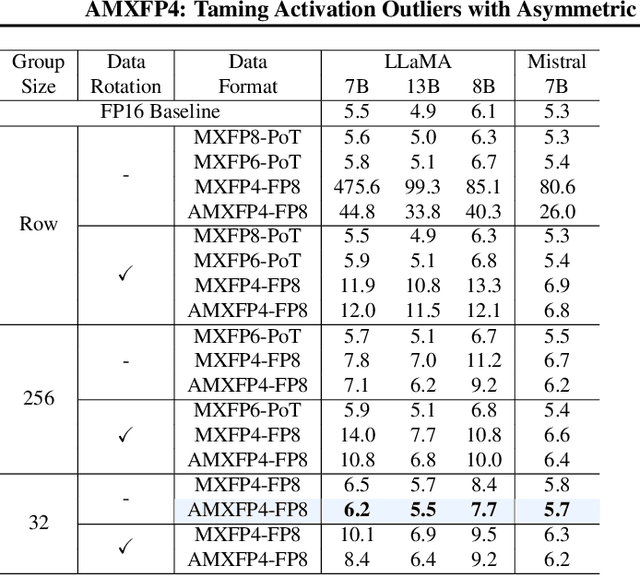
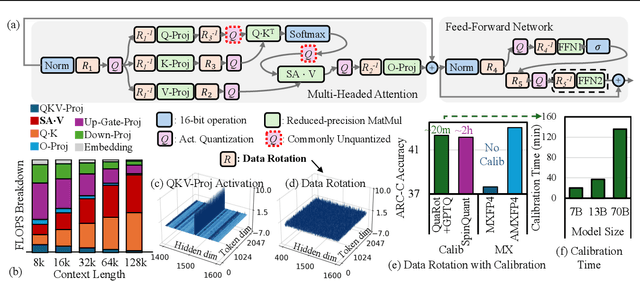
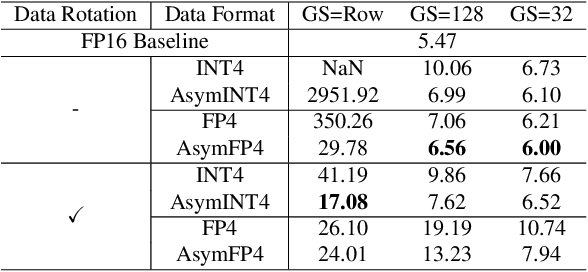
Scaling Large Language Models (LLMs) with extended context lengths has increased the need for efficient low-bit quantization to manage their substantial computational demands. However, reducing precision to 4 bits frequently degrades performance due to activation outliers. To address this, we propose Asymmetric Microscaling 4-bit Floating-Point (AMXFP4) for efficient LLM inference. This novel data format leverages asymmetric shared scales to mitigate outliers while naturally capturing the asymmetry introduced by group-wise quantization. Unlike conventional 4-bit quantization methods that rely on data rotation and costly calibration, AMXFP4 uses asymmetric shared scales for direct 4-bit casting, achieving near-ideal quantization accuracy across various LLM tasks, including multi-turn conversations, long-context reasoning, and visual question answering. Our AMXFP4 format significantly outperforms MXFP4 and other leading quantization techniques, enabling robust, calibration-free 4-bit inference.
Safe-Embed: Unveiling the Safety-Critical Knowledge of Sentence Encoders
Jul 09, 2024Despite the impressive capabilities of Large Language Models (LLMs) in various tasks, their vulnerability to unsafe prompts remains a critical issue. These prompts can lead LLMs to generate responses on illegal or sensitive topics, posing a significant threat to their safe and ethical use. Existing approaches attempt to address this issue using classification models, but they have several drawbacks. With the increasing complexity of unsafe prompts, similarity search-based techniques that identify specific features of unsafe prompts provide a more robust and effective solution to this evolving problem. This paper investigates the potential of sentence encoders to distinguish safe from unsafe prompts, and the ability to classify various unsafe prompts according to a safety taxonomy. We introduce new pairwise datasets and the Categorical Purity (CP) metric to measure this capability. Our findings reveal both the effectiveness and limitations of existing sentence encoders, proposing directions to improve sentence encoders to operate as more robust safety detectors. Our code is available at https://github.com/JwdanielJung/Safe-Embed.
Beyond Binary Gender Labels: Revealing Gender Biases in LLMs through Gender-Neutral Name Predictions
Jul 07, 2024Name-based gender prediction has traditionally categorized individuals as either female or male based on their names, using a binary classification system. That binary approach can be problematic in the cases of gender-neutral names that do not align with any one gender, among other reasons. Relying solely on binary gender categories without recognizing gender-neutral names can reduce the inclusiveness of gender prediction tasks. We introduce an additional gender category, i.e., "neutral", to study and address potential gender biases in Large Language Models (LLMs). We evaluate the performance of several foundational and large language models in predicting gender based on first names only. Additionally, we investigate the impact of adding birth years to enhance the accuracy of gender prediction, accounting for shifting associations between names and genders over time. Our findings indicate that most LLMs identify male and female names with high accuracy (over 80%) but struggle with gender-neutral names (under 40%), and the accuracy of gender prediction is higher for English-based first names than non-English names. The experimental results show that incorporating the birth year does not improve the overall accuracy of gender prediction, especially for names with evolving gender associations. We recommend using caution when applying LLMs for gender identification in downstream tasks, particularly when dealing with non-binary gender labels.
Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder
Mar 15, 2024



Super-resolution (SR) and image generation are important tasks in computer vision and are widely adopted in real-world applications. Most existing methods, however, generate images only at fixed-scale magnification and suffer from over-smoothing and artifacts. Additionally, they do not offer enough diversity of output images nor image consistency at different scales. Most relevant work applied Implicit Neural Representation (INR) to the denoising diffusion model to obtain continuous-resolution yet diverse and high-quality SR results. Since this model operates in the image space, the larger the resolution of image is produced, the more memory and inference time is required, and it also does not maintain scale-specific consistency. We propose a novel pipeline that can super-resolve an input image or generate from a random noise a novel image at arbitrary scales. The method consists of a pretrained auto-encoder, a latent diffusion model, and an implicit neural decoder, and their learning strategies. The proposed method adopts diffusion processes in a latent space, thus efficient, yet aligned with output image space decoded by MLPs at arbitrary scales. More specifically, our arbitrary-scale decoder is designed by the symmetric decoder w/o up-scaling from the pretrained auto-encoder, and Local Implicit Image Function (LIIF) in series. The latent diffusion process is learnt by the denoising and the alignment losses jointly. Errors in output images are backpropagated via the fixed decoder, improving the quality of output images. In the extensive experiments using multiple public benchmarks on the two tasks i.e. image super-resolution and novel image generation at arbitrary scales, the proposed method outperforms relevant methods in metrics of image quality, diversity and scale consistency. It is significantly better than the relevant prior-art in the inference speed and memory usage.
Generating automatically labeled data for author name disambiguation: An iterative clustering method
Feb 05, 2021

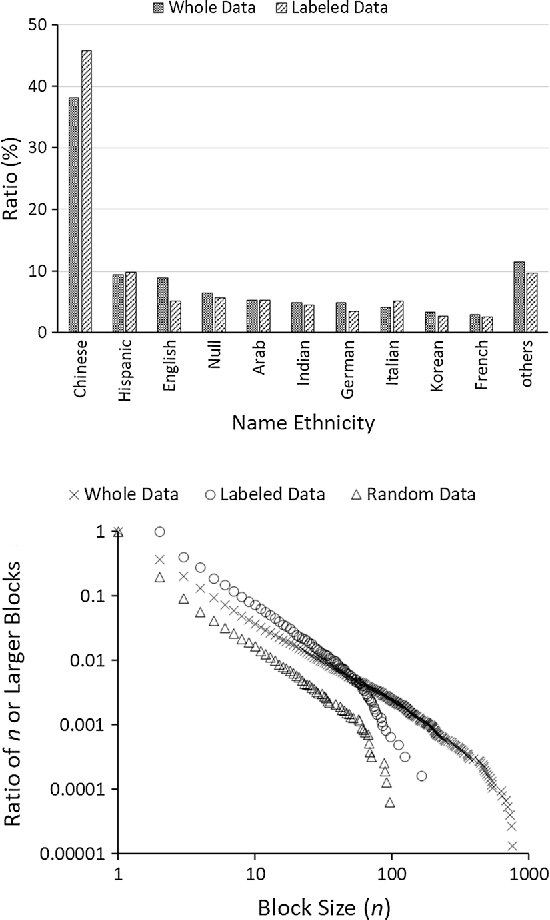

To train algorithms for supervised author name disambiguation, many studies have relied on hand-labeled truth data that are very laborious to generate. This paper shows that labeled training data can be automatically generated using information features such as email address, coauthor names, and cited references that are available from publication records. For this purpose, high-precision rules for matching name instances on each feature are decided using an external-authority database. Then, selected name instances in target ambiguous data go through the process of pairwise matching based on the rules. Next, they are merged into clusters by a generic entity resolution algorithm. The clustering procedure is repeated over other features until further merging is impossible. Tested on 26,566 instances out of the population of 228K author name instances, this iterative clustering produced accurately labeled data with pairwise F1 = 0.99. The labeled data represented the population data in terms of name ethnicity and co-disambiguating name group size distributions. In addition, trained on the labeled data, machine learning algorithms disambiguated 24K names in test data with performance of pairwise F1 = 0.90 ~ 0.92. Several challenges are discussed for applying this method to resolving author name ambiguity in large-scale scholarly data.
* 25 pages
A fast and integrative algorithm for clustering performance evaluation in author name disambiguation
Feb 05, 2021

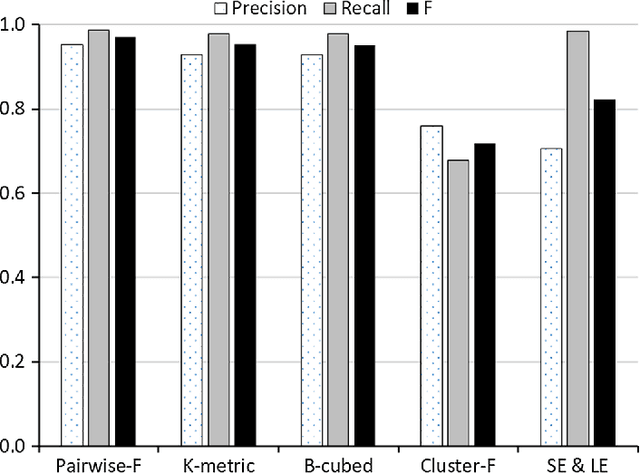

Author name disambiguation results are often evaluated by measures such as Cluster-F, K-metric, Pairwise-F, Splitting & Lumping Error, and B-cubed. Although these measures have distinctive evaluation schemes, this paper shows that they can be calculated in a single framework by a set of common steps that compare truth and predicted clusters through two hash tables recording information about name instances with their predicted cluster indices and frequencies of those indices per truth cluster. This integrative calculation reduces greatly calculation runtime, which is scalable to a clustering task involving millions of name instances within a few seconds. During the integration process, B-cubed and K-metric are shown to produce the same precision and recall scores. In this framework, especially, name instance pairs for Pairwise-F are counted using a heuristic, surpassing a state-of-the-art algorithm in speedy calculation. Details of the integrative calculation are described with examples and pseudo-code to assist scholars to implement each measure easily and validate the correctness of implementation. The integrative calculation will help scholars compare similarities and differences of multiple measures before they select ones that characterize best the clustering performances of their disambiguation methods.
* 20 pages
Effect of forename string on author name disambiguation
Feb 05, 2021In author name disambiguation, author forenames are used to decide which name instances are disambiguated together and how much they are likely to refer to the same author. Despite such a crucial role of forenames, their effect on the performances of heuristic (string matching) and algorithmic disambiguation is not well understood. This study assesses the contributions of forenames in author name disambiguation using multiple labeled datasets under varying ratios and lengths of full forenames, reflecting real-world scenarios in which an author is represented by forename variants (synonym) and some authors share the same forenames (homonym). Results show that increasing the ratios of full forenames improves substantially the performances of both heuristic and machine-learning-based disambiguation. Performance gains by algorithmic disambiguation are pronounced when many forenames are initialized or homonym is prevalent. As the ratios of full forenames increase, however, they become marginal compared to the performances by string matching. Using a small portion of forename strings does not reduce much the performances of both heuristic and algorithmic disambiguation compared to using full-length strings. These findings provide practical suggestions such as restoring initialized forenames into a full-string format via record linkage for improved disambiguation performances.
* 25 pages
ORCID-linked labeled data for evaluating author name disambiguation at scale
Feb 05, 2021
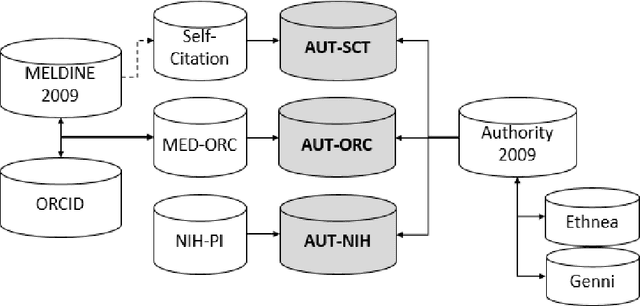

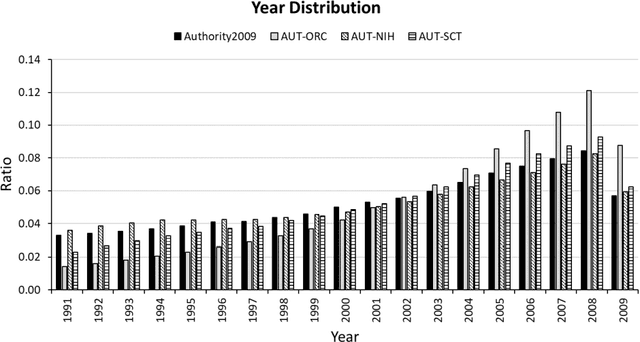
How can we evaluate the performance of a disambiguation method implemented on big bibliographic data? This study suggests that the open researcher profile system, ORCID, can be used as an authority source to label name instances at scale. This study demonstrates the potential by evaluating the disambiguation performances of Author-ity2009 (which algorithmically disambiguates author names in MEDLINE) using 3 million name instances that are automatically labeled through linkage to 5 million ORCID researcher profiles. Results show that although ORCID-linked labeled data do not effectively represent the population of name instances in Author-ity2009, they do effectively capture the 'high precision over high recall' performances of Author-ity2009. In addition, ORCID-linked labeled data can provide nuanced details about the Author-ity2009's performance when name instances are evaluated within and across ethnicity categories. As ORCID continues to be expanded to include more researchers, labeled data via ORCID-linkage can be improved in representing the population of a whole disambiguated data and updated on a regular basis. This can benefit author name disambiguation researchers and practitioners who need large-scale labeled data but lack resources for manual labeling or access to other authority sources for linkage-based labeling. The ORCID-linked labeled data for Author-tiy2009 are publicly available for validation and reuse.