 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fast and integrative algorithm for clustering performance evaluation in author name disambiguation
Paper and Code
Feb 05, 2021

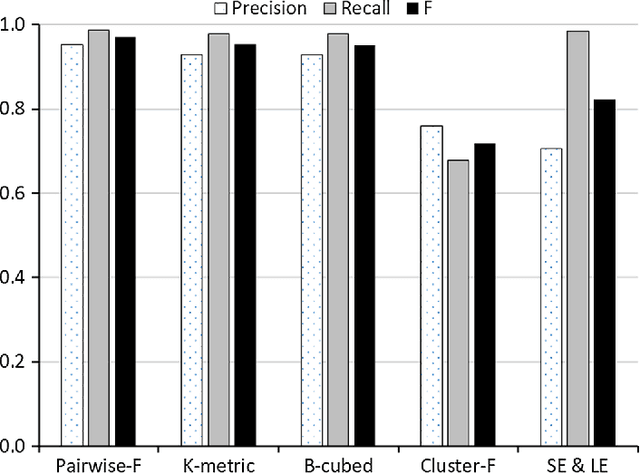

Author name disambiguation results are often evaluated by measures such as Cluster-F, K-metric, Pairwise-F, Splitting & Lumping Error, and B-cubed. Although these measures have distinctive evaluation schemes, this paper shows that they can be calculated in a single framework by a set of common steps that compare truth and predicted clusters through two hash tables recording information about name instances with their predicted cluster indices and frequencies of those indices per truth cluster. This integrative calculation reduces greatly calculation runtime, which is scalable to a clustering task involving millions of name instances within a few seconds. During the integration process, B-cubed and K-metric are shown to produce the same precision and recall scores. In this framework, especially, name instance pairs for Pairwise-F are counted using a heuristic, surpassing a state-of-the-art algorithm in speedy calculation. Details of the integrative calculation are described with examples and pseudo-code to assist scholars to implement each measure easily and validate the correctness of implementation. The integrative calculation will help scholars compare similarities and differences of multiple measures before they select ones that characterize best the clustering performances of their disambiguation methods.