 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-guided Plan and Retrieval: A Strategic Alignment for Interpretable User Satisfaction Estimation in Dialogue
Mar 06, 2025
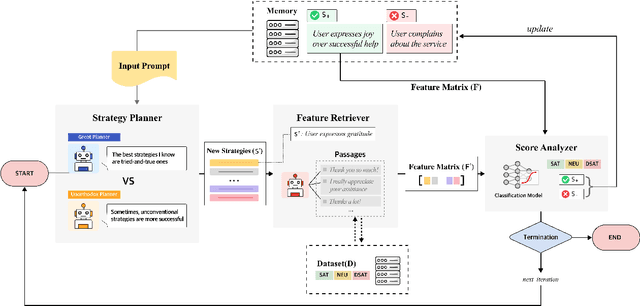

Understanding user satisfaction with conversational systems, known as User Satisfaction Estimation (USE), is essential for assessing dialogue quality and enhancing user experiences. However, existing methods for USE face challenges due to limited understanding of underlying reasons for user dissatisfaction and the high costs of annotating user intentions. To address these challenges, we propose PRAISE (Plan and Retrieval Alignment for Interpretable Satisfaction Estimation), an interpretable framework for effective user satisfaction prediction. PRAISE operates through three key modules. The Strategy Planner develops strategies, which are natural language criteria for classifying user satisfaction. The Feature Retriever then incorporates knowledge on user satisfaction from Large Language Models (LLMs) and retrieves relevance features from utterances. Finally, the Score Analyzer evaluates strategy predictions and classifies user satisfaction. Experimental results demonstrate that PRAISE achieves state-of-the-art performance on three benchmarks for the USE task. Beyond its superior performance, PRAISE offers additional benefits. It enhances interpretability by providing instance-level explanations through effective alignment of utterances with strategies. Moreover, PRAISE operates more efficiently than existing approaches by eliminating the need for LLMs during the inference phase.
Safe-Embed: Unveiling the Safety-Critical Knowledge of Sentence Encoders
Jul 09, 2024Despite the impressive capabilities of Large Language Models (LLMs) in various tasks, their vulnerability to unsafe prompts remains a critical issue. These prompts can lead LLMs to generate responses on illegal or sensitive topics, posing a significant threat to their safe and ethical use. Existing approaches attempt to address this issue using classification models, but they have several drawbacks. With the increasing complexity of unsafe prompts, similarity search-based techniques that identify specific features of unsafe prompts provide a more robust and effective solution to this evolving problem. This paper investigates the potential of sentence encoders to distinguish safe from unsafe prompts, and the ability to classify various unsafe prompts according to a safety taxonomy. We introduce new pairwise datasets and the Categorical Purity (CP) metric to measure this capability. Our findings reveal both the effectiveness and limitations of existing sentence encoders, proposing directions to improve sentence encoders to operate as more robust safety detectors. Our code is available at https://github.com/JwdanielJung/Safe-Embed.
Pipette: Automatic Fine-grained Large Language Model Training Configurator for Real-World Clusters
May 28, 2024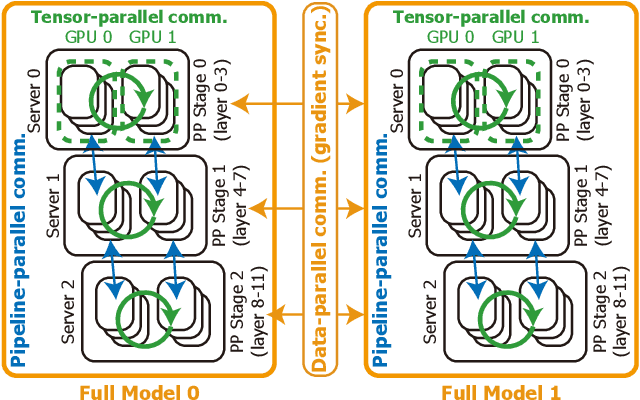
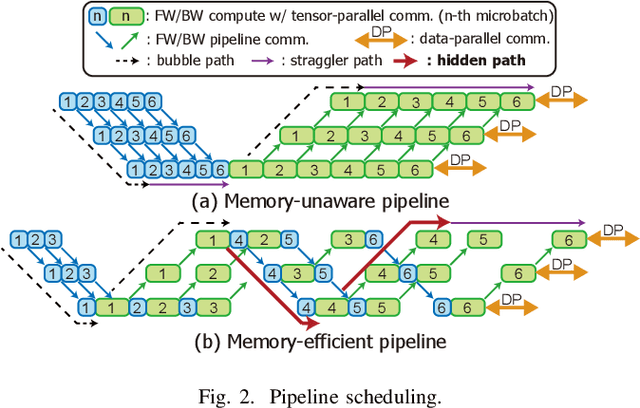
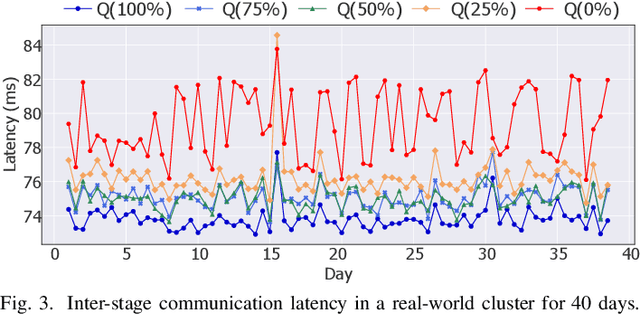
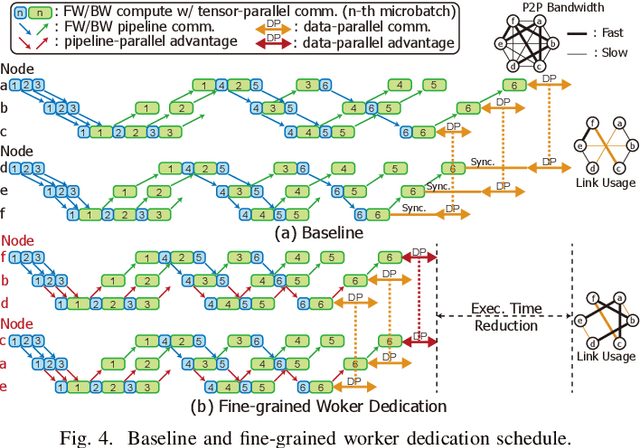
Training large language models (LLMs) is known to be challenging because of the huge computational and memory capacity requirements. To address these issues, it is common to use a cluster of GPUs with 3D parallelism, which splits a model along the data batch, pipeline stage, and intra-layer tensor dimensions. However, the use of 3D parallelism produces the additional challenge of finding the optimal number of ways on each dimension and mapping the split models onto the GPUs. Several previous studies have attempted to automatically find the optimal configuration, but many of these lacked several important aspects. For instance, the heterogeneous nature of the interconnect speeds is often ignored. While the peak bandwidths for the interconnects are usually made equal, the actual attained bandwidth varies per link in real-world clusters. Combined with the critical path modeling that does not properly consider the communication, they easily fall into sub-optimal configurations. In addition, they often fail to consider the memory requirement per GPU, often recommending solutions that could not be executed. To address these challenges, we propose Pipette, which is an automatic fine-grained LLM training configurator for real-world clusters. By devising better performance models along with the memory estimator and fine-grained individual GPU assignment, Pipette achieves faster configurations that satisfy the memory constraints. We evaluated Pipette on large clusters to show that it provides a significant speedup over the prior art. The implementation of Pipette is available at https://github.com/yimjinkyu1/date2024_pipette.
PeerAiD: Improving Adversarial Distillation from a Specialized Peer Tutor
Mar 11, 2024Adversarial robustness of the neural network is a significant concern when it is applied to security-critical domains. In this situation, adversarial distillation is a promising option which aims to distill the robustness of the teacher network to improve the robustness of a small student network. Previous works pretrain the teacher network to make it robust to the adversarial examples aimed at itself. However, the adversarial examples are dependent on the parameters of the target network. The fixed teacher network inevitably degrades its robustness against the unseen transferred adversarial examples which targets the parameters of the student network in the adversarial distillation process. We propose PeerAiD to make a peer network learn the adversarial examples of the student network instead of adversarial examples aimed at itself. PeerAiD is an adversarial distillation that trains the peer network and the student network simultaneously in order to make the peer network specialized for defending the student network. We observe that such peer networks surpass the robustness of pretrained robust teacher network against student-attacked adversarial samples. With this peer network and adversarial distillation, PeerAiD achieves significantly higher robustness of the student network with AutoAttack (AA) accuracy up to 1.66%p and improves the natural accuracy of the student network up to 4.72%p with ResNet-18 and TinyImageNet dataset.
Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System
Mar 11, 2024



The recent huge advance of Large Language Models (LLMs) is mainly driven by the increase in the number of parameters. This has led to substantial memory capacity requirements, necessitating the use of dozens of GPUs just to meet the capacity. One popular solution to this is storage-offloaded training, which uses host memory and storage as an extended memory hierarchy. However, this obviously comes at the cost of storage bandwidth bottleneck because storage devices have orders of magnitude lower bandwidth compared to that of GPU device memories. Our work, Smart-Infinity, addresses the storage bandwidth bottleneck of storage-offloaded LLM training using near-storage processing devices on a real system. The main component of Smart-Infinity is SmartUpdate, which performs parameter updates on custom near-storage accelerators. We identify that moving parameter updates to the storage side removes most of the storage traffic. In addition, we propose an efficient data transfer handler structure to address the system integration issues for Smart-Infinity. The handler allows overlapping data transfers with fixed memory consumption by reusing the device buffer. Lastly, we propose accelerator-assisted gradient compression/decompression to enhance the scalability of Smart-Infinity. When scaling to multiple near-storage processing devices, the write traffic on the shared channel becomes the bottleneck. To alleviate this, we compress the gradients on the GPU and decompress them on the accelerators. It provides further acceleration from reduced traffic. As a result, Smart-Infinity achieves a significant speedup compared to the baseline. Notably, Smart-Infinity is a ready-to-use approach that is fully integrated into PyTorch on a real system. We will open-source Smart-Infinity to facilitate its use.
GraNNDis: Efficient Unified Distributed Training Framework for Deep GNNs on Large Clusters
Nov 12, 2023



Graph neural networks (GNNs) are one of the most rapidly growing fields within deep learning. According to the growth in the dataset and the model size used for GNNs, an important problem is that it becomes nearly impossible to keep the whole network on GPU memory. Among numerous attempts, distributed training is one popular approach to address the problem. However, due to the nature of GNNs, existing distributed approaches suffer from poor scalability, mainly due to the slow external server communications. In this paper, we propose GraNNDis, an efficient distributed GNN training framework for training GNNs on large graphs and deep layers. GraNNDis introduces three new techniques. First, shared preloading provides a training structure for a cluster of multi-GPU servers. We suggest server-wise preloading of essential vertex dependencies to reduce the low-bandwidth external server communications. Second, we present expansion-aware sampling. Because shared preloading alone has limitations because of the neighbor explosion, expansion-aware sampling reduces vertex dependencies that span across server boundaries. Third, we propose cooperative batching to create a unified framework for full-graph and minibatch training. It significantly reduces redundant memory usage in mini-batch training. From this, GraNNDis enables a reasonable trade-off between full-graph and mini-batch training through unification especially when the entire graph does not fit into the GPU memory. With experiments conducted on a multi-server/multi-GPU cluster, we show that GraNNDis provides superior speedup over the state-of-the-art distributed GNN training frameworks.
Pipe-BD: Pipelined Parallel Blockwise Distillation
Jan 29, 2023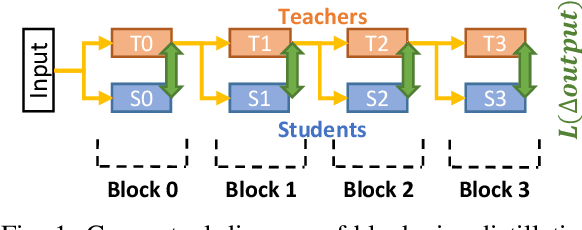
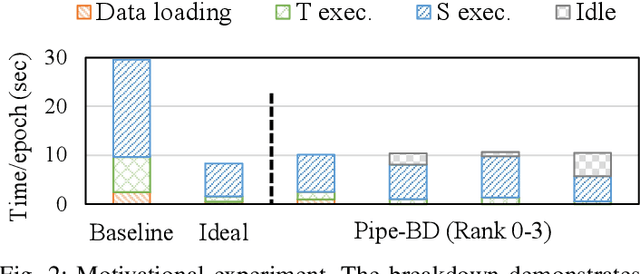
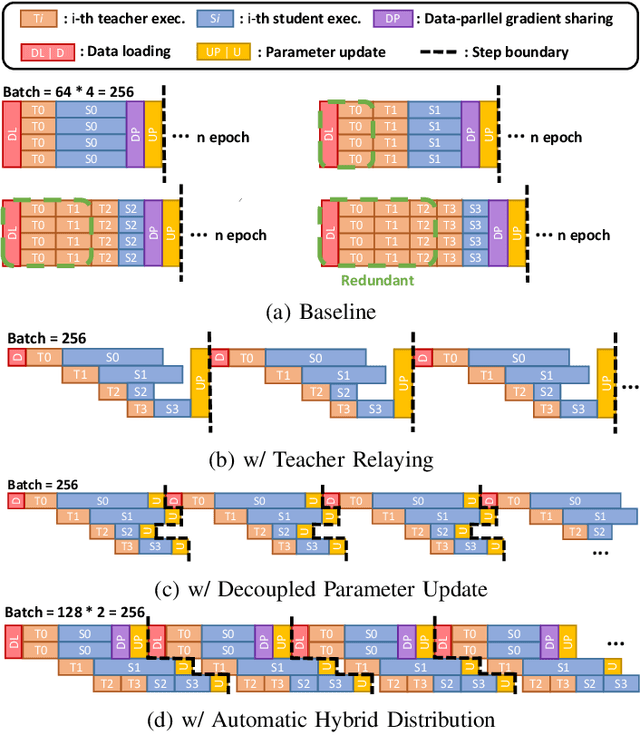
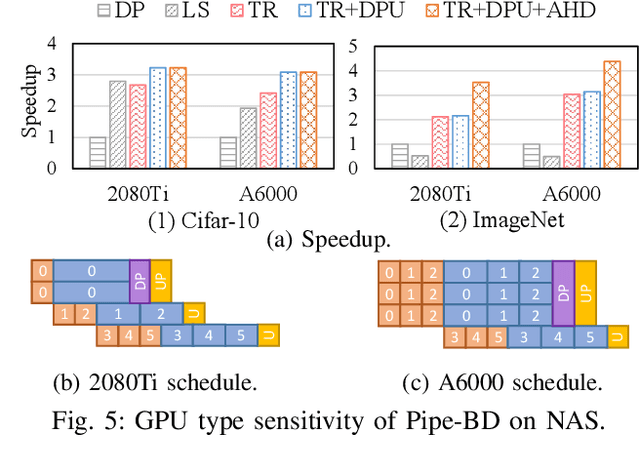
Training large deep neural network models is highly challenging due to their tremendous computational and memory requirements. Blockwise distillation provides one promising method towards faster convergence by splitting a large model into multiple smaller models. In state-of-the-art blockwise distillation methods, training is performed block-by-block in a data-parallel manner using multiple GPUs. To produce inputs for the student blocks, the teacher model is executed from the beginning until the current block under training. However, this results in a high overhead of redundant teacher execution, low GPU utilization, and extra data loading. To address these problems, we propose Pipe-BD, a novel parallelization method for blockwise distillation. Pipe-BD aggressively utilizes pipeline parallelism for blockwise distillation, eliminating redundant teacher block execution and increasing per-device batch size for better resource utilization. We also extend to hybrid parallelism for efficient workload balancing. As a result, Pipe-BD achieves significant acceleration without modifying the mathematical formulation of blockwise distillation. We implement Pipe-BD on PyTorch, and experiments reveal that Pipe-BD is effective on multiple scenarios, models, and datasets.
Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression
Jan 24, 2023



In training of modern large natural language processing (NLP) models, it has become a common practice to split models using 3D parallelism to multiple GPUs. Such technique, however, suffers from a high overhead of inter-node communication. Compressing the communication is one way to mitigate the overhead by reducing the inter-node traffic volume; however, the existing compression techniques have critical limitations to be applied for NLP models with 3D parallelism in that 1) only the data parallelism traffic is targeted, and 2) the existing compression schemes already harm the model quality too much. In this paper, we present Optimus-CC, a fast and scalable distributed training framework for large NLP models with aggressive communication compression. Optimus-CC differs from existing communication compression frameworks in the following ways: First, we compress pipeline parallel (inter-stage) traffic. In specific, we compress the inter-stage backpropagation and the embedding synchronization in addition to the existing data-parallel traffic compression methods. Second, we propose techniques to avoid the model quality drop that comes from the compression. We further provide mathematical and empirical analyses to show that our techniques can successfully suppress the compression error. Lastly, we analyze the pipeline and opt to selectively compress those traffic lying on the critical path. This further helps reduce the compression error. We demonstrate our solution on a GPU cluster, and achieve superior speedup from the baseline state-of-the-art solutions for distributed training without sacrificing the model quality.
Visual Relationship Detection with Language prior and Softmax
Apr 16, 2019

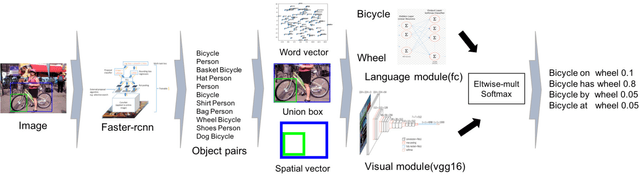
Visual relationship detection is an intermediate image understanding task that detects two objects and classifies a predicate that explains the relationship between two objects in an image. The three components are linguistically and visually correlated (e.g. "wear" is related to "person" and "shirt", while "laptop" is related to "table" and "on") thus, the solution space is huge because there are many possible cases between them. Language and visual modules are exploited and a sophisticated spatial vector is proposed. The models in this work outperformed the state of arts without costly linguistic knowledge distillation from a large text corpus and building complex loss functions. All experiments were only evaluated on Visual Relationship Detection and Visual Genome dataset.
* 6 pages, 4 figures