 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI Fuels Solo Entrepreneurship, but Teams Still Lead at the Top
May 11, 2026Recent advances in generative artificial intelligence (AI) are reshaping who enters entrepreneurship, but not who reaches the top of the quality distribution. Using data on over 160,000 product launches on Product Hunt, we find that entrepreneurial entry increased sharply following the public release of ChatGPT-3.5, driven disproportionately by solo entrepreneurs. This shift toward solo entry is particularly pronounced in categories that historically favored team-based ventures. However, much of this growth reflects low-commitment, experimental entry and does not translate into greater representation among the highest-quality outcomes. Team-based ventures are increasingly dominant in the top tiers of platform rankings. These findings suggest that generative AI lowers barriers to solo entrepreneurship while reinforcing team-based advantages.
Pipette: Automatic Fine-grained Large Language Model Training Configurator for Real-World Clusters
May 28, 2024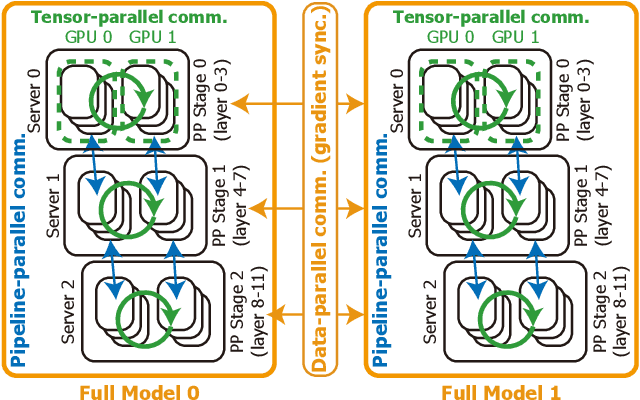
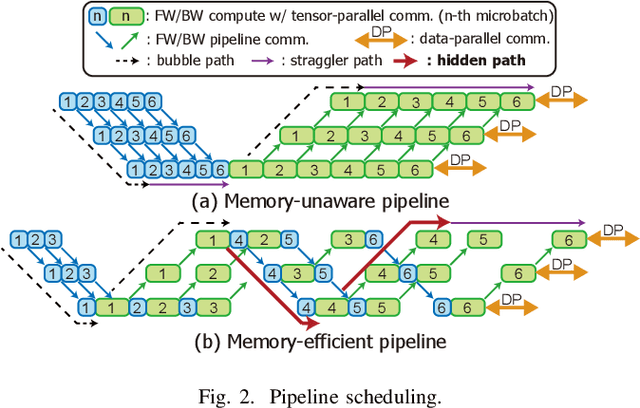
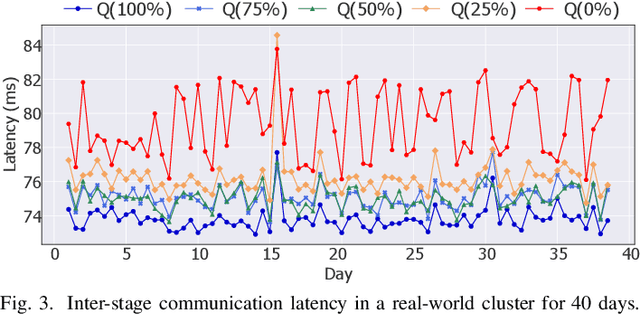
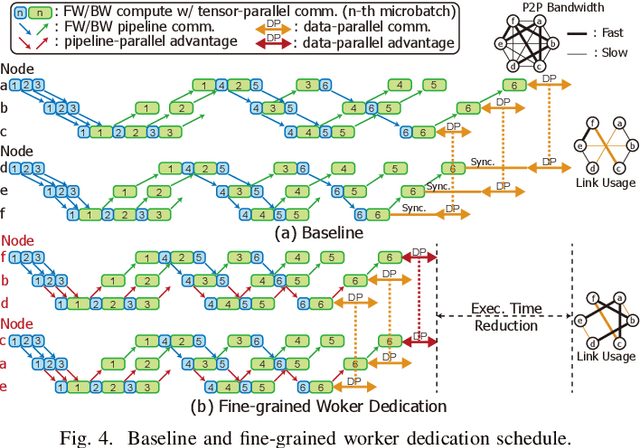
Training large language models (LLMs) is known to be challenging because of the huge computational and memory capacity requirements. To address these issues, it is common to use a cluster of GPUs with 3D parallelism, which splits a model along the data batch, pipeline stage, and intra-layer tensor dimensions. However, the use of 3D parallelism produces the additional challenge of finding the optimal number of ways on each dimension and mapping the split models onto the GPUs. Several previous studies have attempted to automatically find the optimal configuration, but many of these lacked several important aspects. For instance, the heterogeneous nature of the interconnect speeds is often ignored. While the peak bandwidths for the interconnects are usually made equal, the actual attained bandwidth varies per link in real-world clusters. Combined with the critical path modeling that does not properly consider the communication, they easily fall into sub-optimal configurations. In addition, they often fail to consider the memory requirement per GPU, often recommending solutions that could not be executed. To address these challenges, we propose Pipette, which is an automatic fine-grained LLM training configurator for real-world clusters. By devising better performance models along with the memory estimator and fine-grained individual GPU assignment, Pipette achieves faster configurations that satisfy the memory constraints. We evaluated Pipette on large clusters to show that it provides a significant speedup over the prior art. The implementation of Pipette is available at https://github.com/yimjinkyu1/date2024_pipette.
Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System
Mar 11, 2024



The recent huge advance of Large Language Models (LLMs) is mainly driven by the increase in the number of parameters. This has led to substantial memory capacity requirements, necessitating the use of dozens of GPUs just to meet the capacity. One popular solution to this is storage-offloaded training, which uses host memory and storage as an extended memory hierarchy. However, this obviously comes at the cost of storage bandwidth bottleneck because storage devices have orders of magnitude lower bandwidth compared to that of GPU device memories. Our work, Smart-Infinity, addresses the storage bandwidth bottleneck of storage-offloaded LLM training using near-storage processing devices on a real system. The main component of Smart-Infinity is SmartUpdate, which performs parameter updates on custom near-storage accelerators. We identify that moving parameter updates to the storage side removes most of the storage traffic. In addition, we propose an efficient data transfer handler structure to address the system integration issues for Smart-Infinity. The handler allows overlapping data transfers with fixed memory consumption by reusing the device buffer. Lastly, we propose accelerator-assisted gradient compression/decompression to enhance the scalability of Smart-Infinity. When scaling to multiple near-storage processing devices, the write traffic on the shared channel becomes the bottleneck. To alleviate this, we compress the gradients on the GPU and decompress them on the accelerators. It provides further acceleration from reduced traffic. As a result, Smart-Infinity achieves a significant speedup compared to the baseline. Notably, Smart-Infinity is a ready-to-use approach that is fully integrated into PyTorch on a real system. We will open-source Smart-Infinity to facilitate its use.
PeerAiD: Improving Adversarial Distillation from a Specialized Peer Tutor
Mar 11, 2024Adversarial robustness of the neural network is a significant concern when it is applied to security-critical domains. In this situation, adversarial distillation is a promising option which aims to distill the robustness of the teacher network to improve the robustness of a small student network. Previous works pretrain the teacher network to make it robust to the adversarial examples aimed at itself. However, the adversarial examples are dependent on the parameters of the target network. The fixed teacher network inevitably degrades its robustness against the unseen transferred adversarial examples which targets the parameters of the student network in the adversarial distillation process. We propose PeerAiD to make a peer network learn the adversarial examples of the student network instead of adversarial examples aimed at itself. PeerAiD is an adversarial distillation that trains the peer network and the student network simultaneously in order to make the peer network specialized for defending the student network. We observe that such peer networks surpass the robustness of pretrained robust teacher network against student-attacked adversarial samples. With this peer network and adversarial distillation, PeerAiD achieves significantly higher robustness of the student network with AutoAttack (AA) accuracy up to 1.66%p and improves the natural accuracy of the student network up to 4.72%p with ResNet-18 and TinyImageNet dataset.
GraNNDis: Efficient Unified Distributed Training Framework for Deep GNNs on Large Clusters
Nov 12, 2023



Graph neural networks (GNNs) are one of the most rapidly growing fields within deep learning. According to the growth in the dataset and the model size used for GNNs, an important problem is that it becomes nearly impossible to keep the whole network on GPU memory. Among numerous attempts, distributed training is one popular approach to address the problem. However, due to the nature of GNNs, existing distributed approaches suffer from poor scalability, mainly due to the slow external server communications. In this paper, we propose GraNNDis, an efficient distributed GNN training framework for training GNNs on large graphs and deep layers. GraNNDis introduces three new techniques. First, shared preloading provides a training structure for a cluster of multi-GPU servers. We suggest server-wise preloading of essential vertex dependencies to reduce the low-bandwidth external server communications. Second, we present expansion-aware sampling. Because shared preloading alone has limitations because of the neighbor explosion, expansion-aware sampling reduces vertex dependencies that span across server boundaries. Third, we propose cooperative batching to create a unified framework for full-graph and minibatch training. It significantly reduces redundant memory usage in mini-batch training. From this, GraNNDis enables a reasonable trade-off between full-graph and mini-batch training through unification especially when the entire graph does not fit into the GPU memory. With experiments conducted on a multi-server/multi-GPU cluster, we show that GraNNDis provides superior speedup over the state-of-the-art distributed GNN training frameworks.
Pipe-BD: Pipelined Parallel Blockwise Distillation
Jan 29, 2023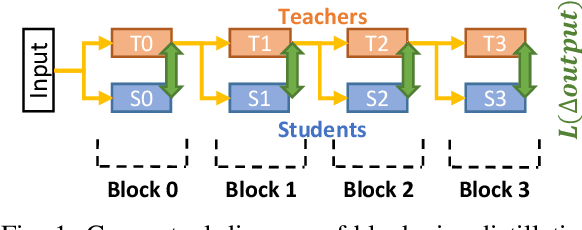
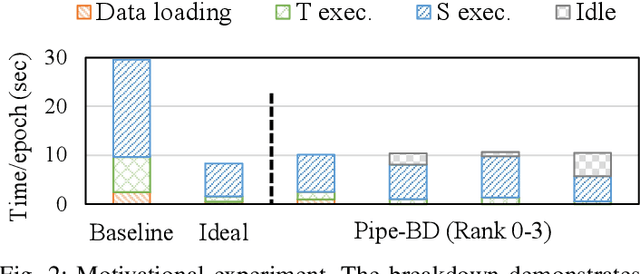
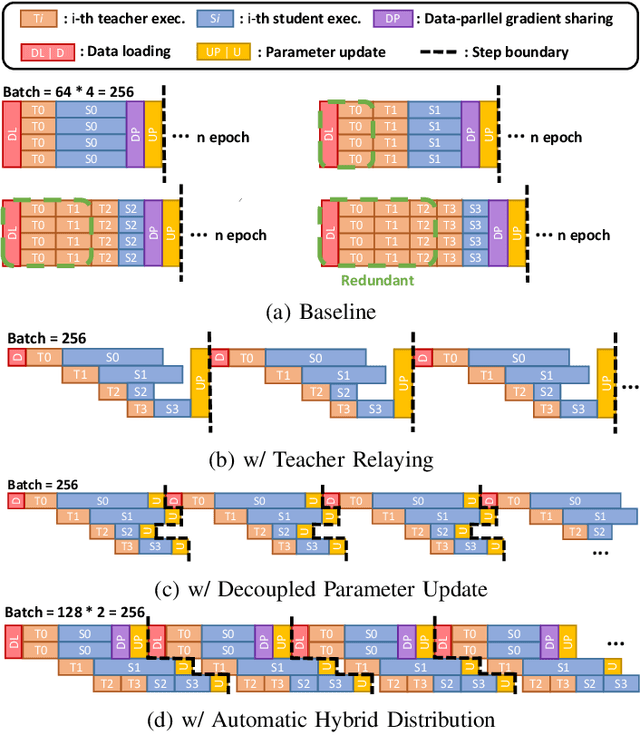
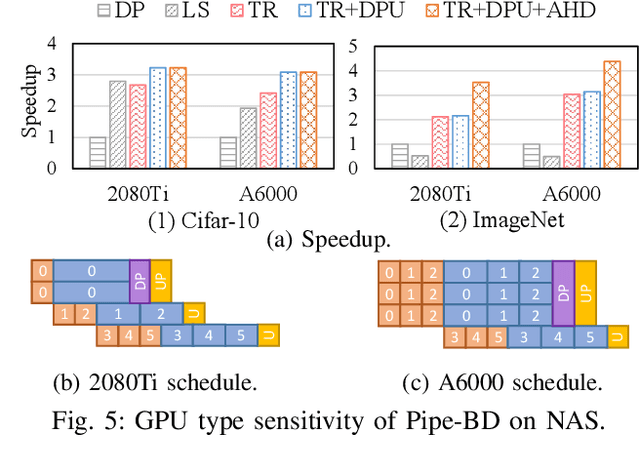
Training large deep neural network models is highly challenging due to their tremendous computational and memory requirements. Blockwise distillation provides one promising method towards faster convergence by splitting a large model into multiple smaller models. In state-of-the-art blockwise distillation methods, training is performed block-by-block in a data-parallel manner using multiple GPUs. To produce inputs for the student blocks, the teacher model is executed from the beginning until the current block under training. However, this results in a high overhead of redundant teacher execution, low GPU utilization, and extra data loading. To address these problems, we propose Pipe-BD, a novel parallelization method for blockwise distillation. Pipe-BD aggressively utilizes pipeline parallelism for blockwise distillation, eliminating redundant teacher block execution and increasing per-device batch size for better resource utilization. We also extend to hybrid parallelism for efficient workload balancing. As a result, Pipe-BD achieves significant acceleration without modifying the mathematical formulation of blockwise distillation. We implement Pipe-BD on PyTorch, and experiments reveal that Pipe-BD is effective on multiple scenarios, models, and datasets.
SGCN: Exploiting Compressed-Sparse Features in Deep Graph Convolutional Network Accelerators
Jan 25, 2023
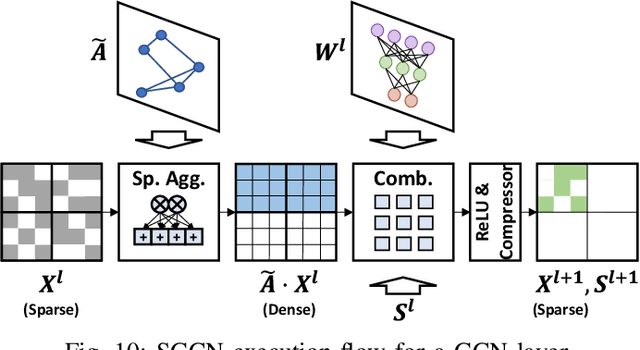


Graph convolutional networks (GCNs) are becoming increasingly popular as they overcome the limited applicability of prior neural networks. A GCN takes as input an arbitrarily structured graph and executes a series of layers which exploit the graph's structure to calculate their output features. One recent trend in GCNs is the use of deep network architectures. As opposed to the traditional GCNs which only span around two to five layers deep, modern GCNs now incorporate tens to hundreds of layers with the help of residual connections. From such deep GCNs, we find an important characteristic that they exhibit very high intermediate feature sparsity. We observe that with deep layers and residual connections, the number of zeros in the intermediate features sharply increases. This reveals a new opportunity for accelerators to exploit in GCN executions that was previously not present. In this paper, we propose SGCN, a fast and energy-efficient GCN accelerator which fully exploits the sparse intermediate features of modern GCNs. SGCN suggests several techniques to achieve significantly higher performance and energy efficiency than the existing accelerators. First, SGCN employs a GCN-friendly feature compression format. We focus on reducing the off-chip memory traffic, which often is the bottleneck for GCN executions. Second, we propose microarchitectures for seamlessly handling the compressed feature format. Third, to better handle locality in the existence of the varying sparsity, SGCN employs sparsity-aware cooperation. Sparsity-aware cooperation creates a pattern that exhibits multiple reuse windows, such that the cache can capture diverse sizes of working sets and therefore adapt to the varying level of sparsity. We show that SGCN achieves 1.71x speedup and 43.9% higher energy efficiency compared to the existing accelerators.
Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression
Jan 24, 2023



In training of modern large natural language processing (NLP) models, it has become a common practice to split models using 3D parallelism to multiple GPUs. Such technique, however, suffers from a high overhead of inter-node communication. Compressing the communication is one way to mitigate the overhead by reducing the inter-node traffic volume; however, the existing compression techniques have critical limitations to be applied for NLP models with 3D parallelism in that 1) only the data parallelism traffic is targeted, and 2) the existing compression schemes already harm the model quality too much. In this paper, we present Optimus-CC, a fast and scalable distributed training framework for large NLP models with aggressive communication compression. Optimus-CC differs from existing communication compression frameworks in the following ways: First, we compress pipeline parallel (inter-stage) traffic. In specific, we compress the inter-stage backpropagation and the embedding synchronization in addition to the existing data-parallel traffic compression methods. Second, we propose techniques to avoid the model quality drop that comes from the compression. We further provide mathematical and empirical analyses to show that our techniques can successfully suppress the compression error. Lastly, we analyze the pipeline and opt to selectively compress those traffic lying on the critical path. This further helps reduce the compression error. We demonstrate our solution on a GPU cluster, and achieve superior speedup from the baseline state-of-the-art solutions for distributed training without sacrificing the model quality.
Slice-and-Forge: Making Better Use of Caches for Graph Convolutional Network Accelerators
Jan 24, 2023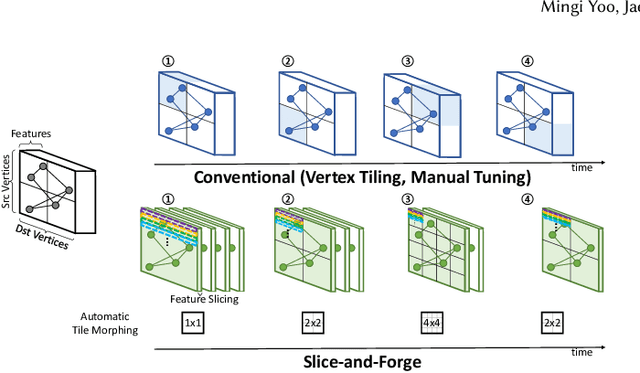

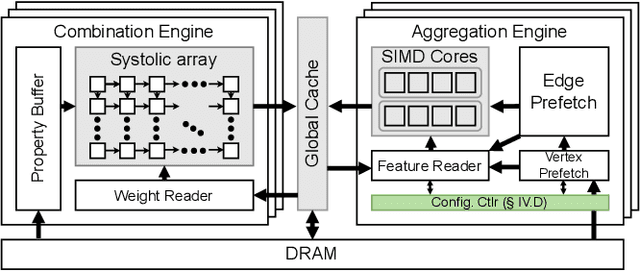

Graph convolutional networks (GCNs) are becoming increasingly popular as they can process a wide variety of data formats that prior deep neural networks cannot easily support. One key challenge in designing hardware accelerators for GCNs is the vast size and randomness in their data access patterns which greatly reduces the effectiveness of the limited on-chip cache. Aimed at improving the effectiveness of the cache by mitigating the irregular data accesses, prior studies often employ the vertex tiling techniques used in traditional graph processing applications. While being effective at enhancing the cache efficiency, those approaches are often sensitive to the tiling configurations where the optimal setting heavily depends on target input datasets. Furthermore, the existing solutions require manual tuning through trial-and-error or rely on sub-optimal analytical models. In this paper, we propose Slice-and-Forge (SnF), an efficient hardware accelerator for GCNs which greatly improves the effectiveness of the limited on-chip cache. SnF chooses a tiling strategy named feature slicing that splits the features into vertical slices and processes them in the outermost loop of the execution. This particular choice results in a repetition of the identical computational patterns over irregular graph data over multiple rounds. Taking advantage of such repetitions, SnF dynamically tunes its tile size. Our experimental results reveal that SnF can achieve 1.73x higher performance in geomean compared to prior work on multi-engine settings, and 1.46x higher performance in geomean on small scale settings, without the need for off-line analyses.