 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGCN: Exploiting Compressed-Sparse Features in Deep Graph Convolutional Network Accelerators
Jan 25, 2023
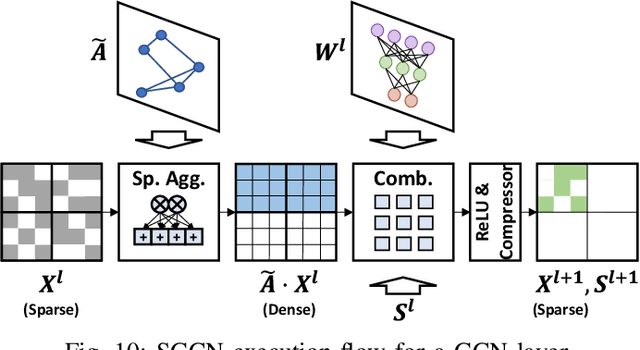


Graph convolutional networks (GCNs) are becoming increasingly popular as they overcome the limited applicability of prior neural networks. A GCN takes as input an arbitrarily structured graph and executes a series of layers which exploit the graph's structure to calculate their output features. One recent trend in GCNs is the use of deep network architectures. As opposed to the traditional GCNs which only span around two to five layers deep, modern GCNs now incorporate tens to hundreds of layers with the help of residual connections. From such deep GCNs, we find an important characteristic that they exhibit very high intermediate feature sparsity. We observe that with deep layers and residual connections, the number of zeros in the intermediate features sharply increases. This reveals a new opportunity for accelerators to exploit in GCN executions that was previously not present. In this paper, we propose SGCN, a fast and energy-efficient GCN accelerator which fully exploits the sparse intermediate features of modern GCNs. SGCN suggests several techniques to achieve significantly higher performance and energy efficiency than the existing accelerators. First, SGCN employs a GCN-friendly feature compression format. We focus on reducing the off-chip memory traffic, which often is the bottleneck for GCN executions. Second, we propose microarchitectures for seamlessly handling the compressed feature format. Third, to better handle locality in the existence of the varying sparsity, SGCN employs sparsity-aware cooperation. Sparsity-aware cooperation creates a pattern that exhibits multiple reuse windows, such that the cache can capture diverse sizes of working sets and therefore adapt to the varying level of sparsity. We show that SGCN achieves 1.71x speedup and 43.9% higher energy efficiency compared to the existing accelerators.
Slice-and-Forge: Making Better Use of Caches for Graph Convolutional Network Accelerators
Jan 24, 2023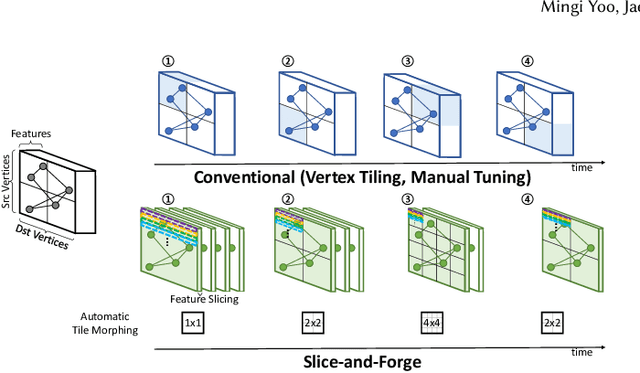

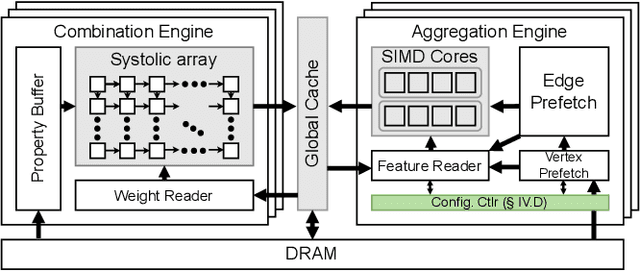

Graph convolutional networks (GCNs) are becoming increasingly popular as they can process a wide variety of data formats that prior deep neural networks cannot easily support. One key challenge in designing hardware accelerators for GCNs is the vast size and randomness in their data access patterns which greatly reduces the effectiveness of the limited on-chip cache. Aimed at improving the effectiveness of the cache by mitigating the irregular data accesses, prior studies often employ the vertex tiling techniques used in traditional graph processing applications. While being effective at enhancing the cache efficiency, those approaches are often sensitive to the tiling configurations where the optimal setting heavily depends on target input datasets. Furthermore, the existing solutions require manual tuning through trial-and-error or rely on sub-optimal analytical models. In this paper, we propose Slice-and-Forge (SnF), an efficient hardware accelerator for GCNs which greatly improves the effectiveness of the limited on-chip cache. SnF chooses a tiling strategy named feature slicing that splits the features into vertical slices and processes them in the outermost loop of the execution. This particular choice results in a repetition of the identical computational patterns over irregular graph data over multiple rounds. Taking advantage of such repetitions, SnF dynamically tunes its tile size. Our experimental results reveal that SnF can achieve 1.73x higher performance in geomean compared to prior work on multi-engine settings, and 1.46x higher performance in geomean on small scale settings, without the need for off-line analyses.