 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataFreeShield: Defending Adversarial Attacks without Training Data
Jun 21, 2024Recent advances in adversarial robustness rely on an abundant set of training data, where using external or additional datasets has become a common setting. However, in real life, the training data is often kept private for security and privacy issues, while only the pretrained weight is available to the public. In such scenarios, existing methods that assume accessibility to the original data become inapplicable. Thus we investigate the pivotal problem of data-free adversarial robustness, where we try to achieve adversarial robustness without accessing any real data. Through a preliminary study, we highlight the severity of the problem by showing that robustness without the original dataset is difficult to achieve, even with similar domain datasets. To address this issue, we propose DataFreeShield, which tackles the problem from two perspectives: surrogate dataset generation and adversarial training using the generated data. Through extensive validation, we show that DataFreeShield outperforms baselines, demonstrating that the proposed method sets the first entirely data-free solution for the adversarial robustness problem.
Slice-and-Forge: Making Better Use of Caches for Graph Convolutional Network Accelerators
Jan 24, 2023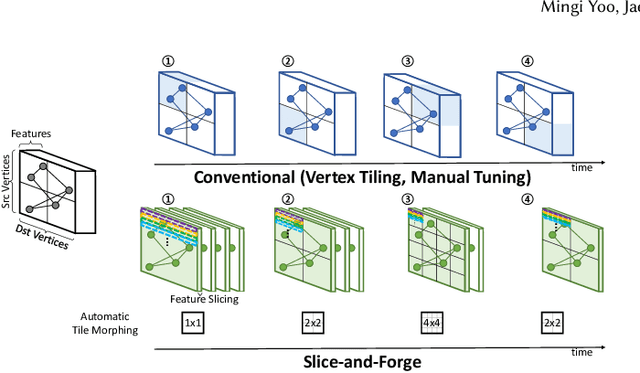

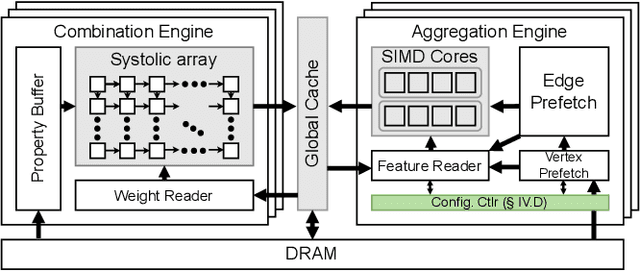

Graph convolutional networks (GCNs) are becoming increasingly popular as they can process a wide variety of data formats that prior deep neural networks cannot easily support. One key challenge in designing hardware accelerators for GCNs is the vast size and randomness in their data access patterns which greatly reduces the effectiveness of the limited on-chip cache. Aimed at improving the effectiveness of the cache by mitigating the irregular data accesses, prior studies often employ the vertex tiling techniques used in traditional graph processing applications. While being effective at enhancing the cache efficiency, those approaches are often sensitive to the tiling configurations where the optimal setting heavily depends on target input datasets. Furthermore, the existing solutions require manual tuning through trial-and-error or rely on sub-optimal analytical models. In this paper, we propose Slice-and-Forge (SnF), an efficient hardware accelerator for GCNs which greatly improves the effectiveness of the limited on-chip cache. SnF chooses a tiling strategy named feature slicing that splits the features into vertical slices and processes them in the outermost loop of the execution. This particular choice results in a repetition of the identical computational patterns over irregular graph data over multiple rounds. Taking advantage of such repetitions, SnF dynamically tunes its tile size. Our experimental results reveal that SnF can achieve 1.73x higher performance in geomean compared to prior work on multi-engine settings, and 1.46x higher performance in geomean on small scale settings, without the need for off-line analyses.
Deep Composer Classification Using Symbolic Representation
Oct 26, 2020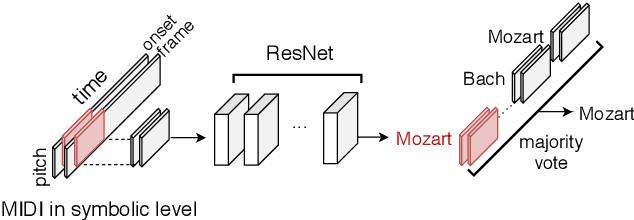
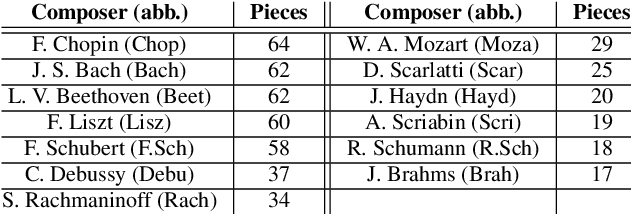
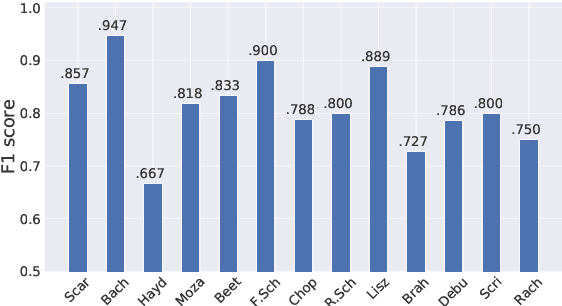
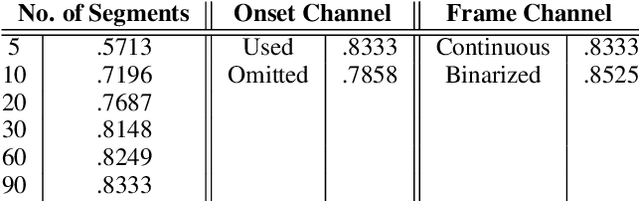
In this study, we train deep neural networks to classify composer on a symbolic domain. The model takes a two-channel two-dimensional input, i.e., onset and note activations of time-pitch representation, which is converted from MIDI recordings and performs a single-label classification. On the experiments conducted on MAESTRO dataset, we report an F1 value of 0.8333 for the classification of 13~classical composers.