 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataFreeShield: Defending Adversarial Attacks without Training Data
Jun 21, 2024Recent advances in adversarial robustness rely on an abundant set of training data, where using external or additional datasets has become a common setting. However, in real life, the training data is often kept private for security and privacy issues, while only the pretrained weight is available to the public. In such scenarios, existing methods that assume accessibility to the original data become inapplicable. Thus we investigate the pivotal problem of data-free adversarial robustness, where we try to achieve adversarial robustness without accessing any real data. Through a preliminary study, we highlight the severity of the problem by showing that robustness without the original dataset is difficult to achieve, even with similar domain datasets. To address this issue, we propose DataFreeShield, which tackles the problem from two perspectives: surrogate dataset generation and adversarial training using the generated data. Through extensive validation, we show that DataFreeShield outperforms baselines, demonstrating that the proposed method sets the first entirely data-free solution for the adversarial robustness problem.
The ReturnZero System for VoxCeleb Speaker Recognition Challenge 2022
Sep 21, 2022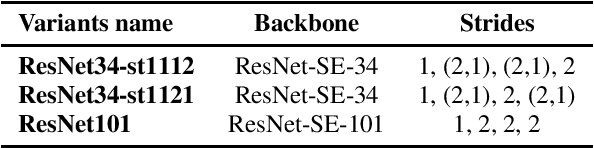
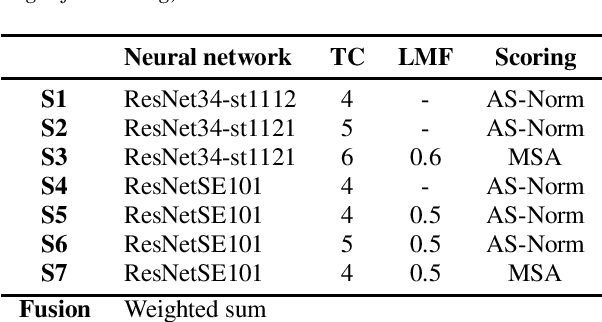
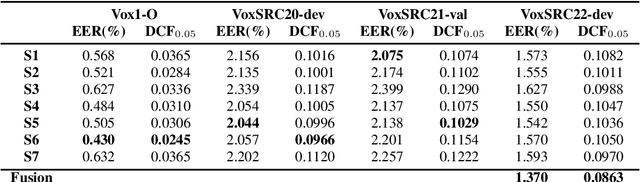
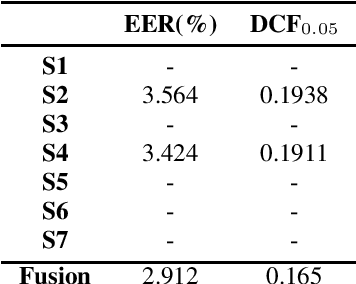
In this paper, we describe the top-scoring submissions for team RTZR VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22) in the closed dataset, speaker verification Track 1. The top performed system is a fusion of 7 models, which contains 3 different types of model architectures. We focus on training models to learn extra-temporal information. Therefore, all models were trained with 4-6 second frames for each utterance. Also, we apply the Large Margin Fine-tuning strategy which has shown good performance on the previous challenges for some of our fusion models. While the evaluation process, we apply the scoring methods with adaptive symmetric normalization (AS-Norm) and matrix score average (MSA). Finally, we mix up models with logistic regression to fuse all the trained models. The final submission achieves 0.165 DCF and 2.912% EER on the VoxSRC22 test set.
Deep Composer Classification Using Symbolic Representation
Oct 26, 2020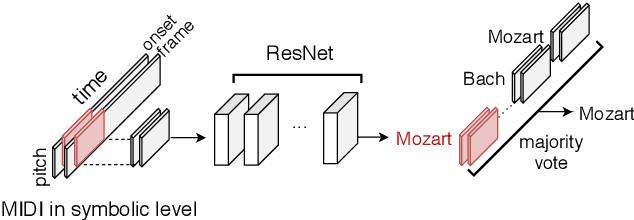
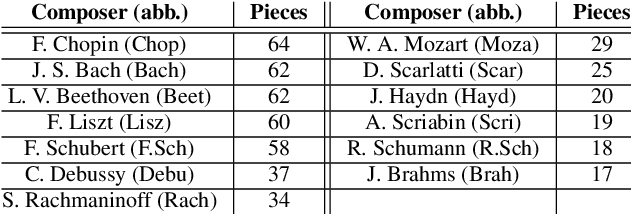
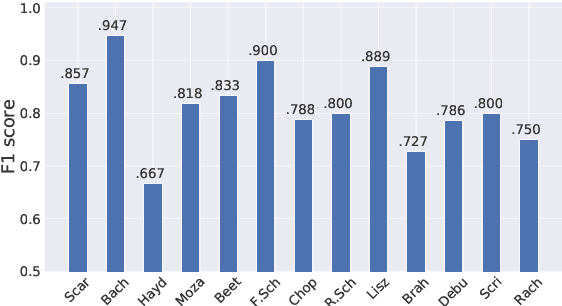
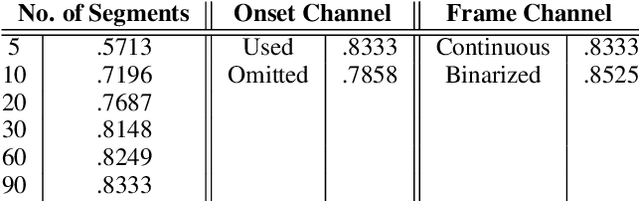
In this study, we train deep neural networks to classify composer on a symbolic domain. The model takes a two-channel two-dimensional input, i.e., onset and note activations of time-pitch representation, which is converted from MIDI recordings and performs a single-label classification. On the experiments conducted on MAESTRO dataset, we report an F1 value of 0.8333 for the classification of 13~classical composers.