 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimiQ: Low-Bit Data-Free Quantization of Vision Transformers
Jul 29, 2024Data-free quantization (DFQ) is a technique that creates a lightweight network from its full-precision counterpart without the original training data, often through a synthetic dataset. Although several DFQ methods have been proposed for vision transformer (ViT) architectures, they fail to achieve efficacy in low-bit settings. Examining the existing methods, we identify that their synthetic data produce misaligned attention maps, while those of the real samples are highly aligned. From the observation of aligned attention, we find that aligning attention maps of synthetic data helps to improve the overall performance of quantized ViTs. Motivated by this finding, we devise \aname, a novel DFQ method designed for ViTs that focuses on inter-head attention similarity. First, we generate synthetic data by aligning head-wise attention responses in relation to spatial query patches. Then, we apply head-wise structural attention distillation to align the attention maps of the quantized network to those of the full-precision teacher. The experimental results show that the proposed method significantly outperforms baselines, setting a new state-of-the-art performance for data-free ViT quantization.
DataFreeShield: Defending Adversarial Attacks without Training Data
Jun 21, 2024Recent advances in adversarial robustness rely on an abundant set of training data, where using external or additional datasets has become a common setting. However, in real life, the training data is often kept private for security and privacy issues, while only the pretrained weight is available to the public. In such scenarios, existing methods that assume accessibility to the original data become inapplicable. Thus we investigate the pivotal problem of data-free adversarial robustness, where we try to achieve adversarial robustness without accessing any real data. Through a preliminary study, we highlight the severity of the problem by showing that robustness without the original dataset is difficult to achieve, even with similar domain datasets. To address this issue, we propose DataFreeShield, which tackles the problem from two perspectives: surrogate dataset generation and adversarial training using the generated data. Through extensive validation, we show that DataFreeShield outperforms baselines, demonstrating that the proposed method sets the first entirely data-free solution for the adversarial robustness problem.
Enabling Hard Constraints in Differentiable Neural Network and Accelerator Co-Exploration
Jan 23, 2023Co-exploration of an optimal neural architecture and its hardware accelerator is an approach of rising interest which addresses the computational cost problem, especially in low-profile systems. The large co-exploration space is often handled by adopting the idea of differentiable neural architecture search. However, despite the superior search efficiency of the differentiable co-exploration, it faces a critical challenge of not being able to systematically satisfy hard constraints such as frame rate. To handle the hard constraint problem of differentiable co-exploration, we propose HDX, which searches for hard-constrained solutions without compromising the global design objectives. By manipulating the gradients in the interest of the given hard constraint, high-quality solutions satisfying the constraint can be obtained.
It's All In the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
Apr 01, 2022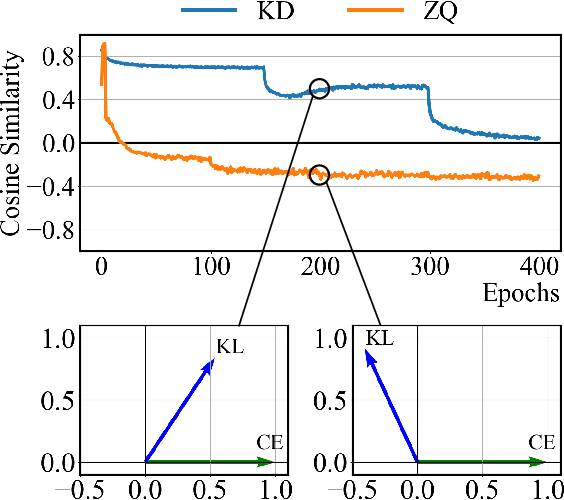
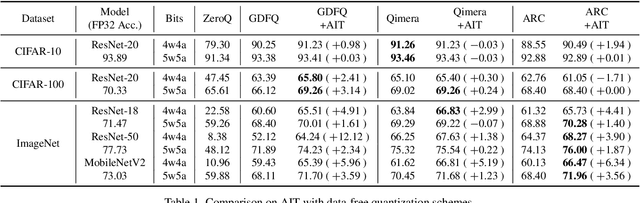
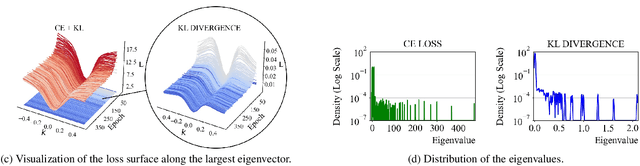
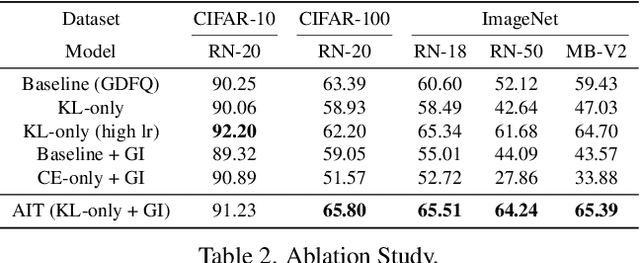
Model quantization is considered as a promising method to greatly reduce the resource requirements of deep neural networks. To deal with the performance drop induced by quantization errors, a popular method is to use training data to fine-tune quantized networks. In real-world environments, however, such a method is frequently infeasible because training data is unavailable due to security, privacy, or confidentiality concerns. Zero-shot quantization addresses such problems, usually by taking information from the weights of a full-precision teacher network to compensate the performance drop of the quantized networks. In this paper, we first analyze the loss surface of state-of-the-art zero-shot quantization techniques and provide several findings. In contrast to usual knowledge distillation problems, zero-shot quantization often suffers from 1) the difficulty of optimizing multiple loss terms together, and 2) the poor generalization capability due to the use of synthetic samples. Furthermore, we observe that many weights fail to cross the rounding threshold during training the quantized networks even when it is necessary to do so for better performance. Based on the observations, we propose AIT, a simple yet powerful technique for zero-shot quantization, which addresses the aforementioned two problems in the following way: AIT i) uses a KL distance loss only without a cross-entropy loss, and ii) manipulates gradients to guarantee that a certain portion of weights are properly updated after crossing the rounding thresholds. Experiments show that AIT outperforms the performance of many existing methods by a great margin, taking over the overall state-of-the-art position in the field.
Qimera: Data-free Quantization with Synthetic Boundary Supporting Samples
Nov 04, 2021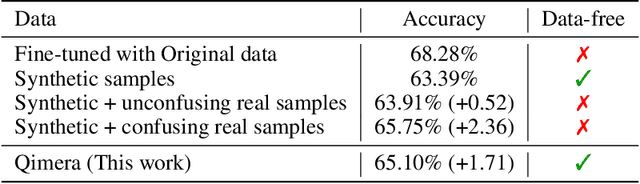
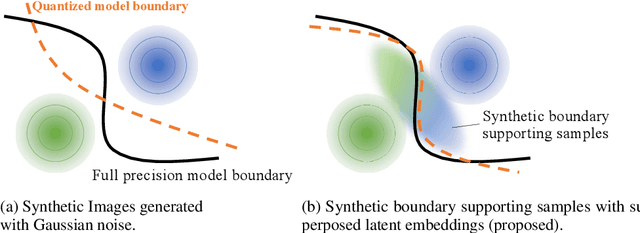
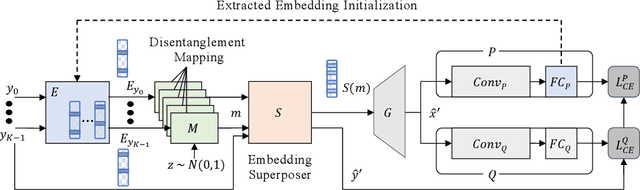
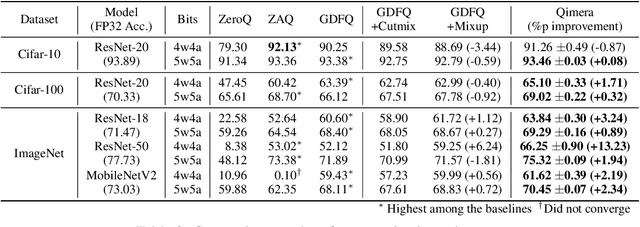
Model quantization is known as a promising method to compress deep neural networks, especially for inferences on lightweight mobile or edge devices. However, model quantization usually requires access to the original training data to maintain the accuracy of the full-precision models, which is often infeasible in real-world scenarios for security and privacy issues. A popular approach to perform quantization without access to the original data is to use synthetically generated samples, based on batch-normalization statistics or adversarial learning. However, the drawback of such approaches is that they primarily rely on random noise input to the generator to attain diversity of the synthetic samples. We find that this is often insufficient to capture the distribution of the original data, especially around the decision boundaries. To this end, we propose Qimera, a method that uses superposed latent embeddings to generate synthetic boundary supporting samples. For the superposed embeddings to better reflect the original distribution, we also propose using an additional disentanglement mapping layer and extracting information from the full-precision model. The experimental results show that Qimera achieves state-of-the-art performances for various settings on data-free quantization. Code is available at https://github.com/iamkanghyunchoi/qimera.
DANCE: Differentiable Accelerator/Network Co-Exploration
Sep 14, 2020

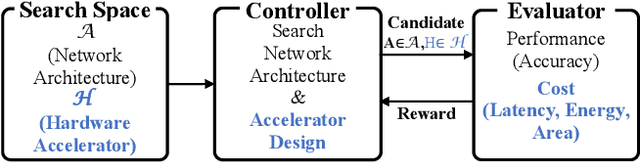

To cope with the ever-increasing computational demand of the DNN execution, recent neural architecture search (NAS) algorithms consider hardware cost metrics into account, such as GPU latency. To further pursue a fast, efficient execution, DNN-specialized hardware accelerators are being designed for multiple purposes, which far-exceeds the efficiency of the GPUs. However, those hardware-related metrics have been proven to exhibit non-linear relationships with the network architectures. Therefore it became a chicken-and-egg problem to optimize the network against the accelerator, or to optimize the accelerator against the network. In such circumstances, this work presents DANCE, a differentiable approach towards the co-exploration of the hardware accelerator and network architecture design. At the heart of DANCE is a differentiable evaluator network. By modeling the hardware evaluation software with a neural network, the relation between the accelerator architecture and the hardware metrics becomes differentiable, allowing the search to be performed with backpropagation. Compared to the naive existing approaches, our method performs co-exploration in a significantly shorter time, while achieving superior accuracy and hardware cost metrics.