 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-training quantization of vision encoders needs prefixing registers
Oct 06, 2025



Transformer-based vision encoders -- such as CLIP -- are central to multimodal intelligence, powering applications from autonomous web agents to robotic control. Since these applications often demand real-time processing of massive visual data, reducing the inference cost of vision encoders is critical. Post-training quantization offers a practical path, but remains challenging even at 8-bit precision due to massive-scale activations (i.e., outliers). In this work, we propose $\textit{RegCache}$, a training-free algorithm to mitigate outliers in vision encoders, enabling quantization with significantly smaller accuracy drops. The proposed RegCache introduces outlier-prone yet semantically meaningless prefix tokens to the target vision encoder, which prevents other tokens from having outliers. Notably, we observe that outliers in vision encoders behave differently from those in language models, motivating two technical innovations: middle-layer prefixing and token deletion. Experiments show that our method consistently improves the accuracy of quantized models across both text-supervised and self-supervised vision encoders.
MimiQ: Low-Bit Data-Free Quantization of Vision Transformers
Jul 29, 2024Data-free quantization (DFQ) is a technique that creates a lightweight network from its full-precision counterpart without the original training data, often through a synthetic dataset. Although several DFQ methods have been proposed for vision transformer (ViT) architectures, they fail to achieve efficacy in low-bit settings. Examining the existing methods, we identify that their synthetic data produce misaligned attention maps, while those of the real samples are highly aligned. From the observation of aligned attention, we find that aligning attention maps of synthetic data helps to improve the overall performance of quantized ViTs. Motivated by this finding, we devise \aname, a novel DFQ method designed for ViTs that focuses on inter-head attention similarity. First, we generate synthetic data by aligning head-wise attention responses in relation to spatial query patches. Then, we apply head-wise structural attention distillation to align the attention maps of the quantized network to those of the full-precision teacher. The experimental results show that the proposed method significantly outperforms baselines, setting a new state-of-the-art performance for data-free ViT quantization.
Prefixing Attention Sinks can Mitigate Activation Outliers for Large Language Model Quantization
Jun 17, 2024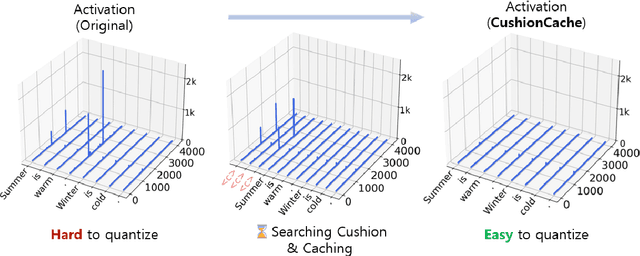
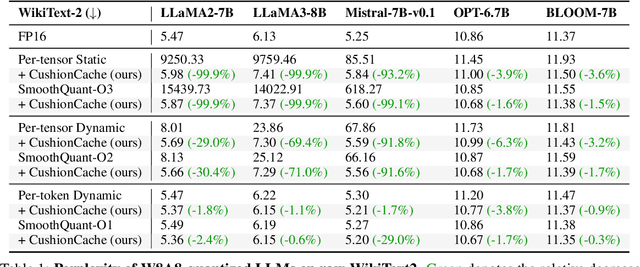
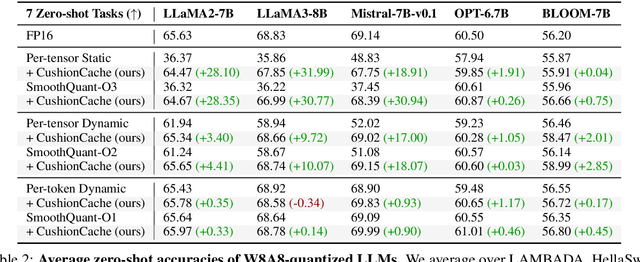
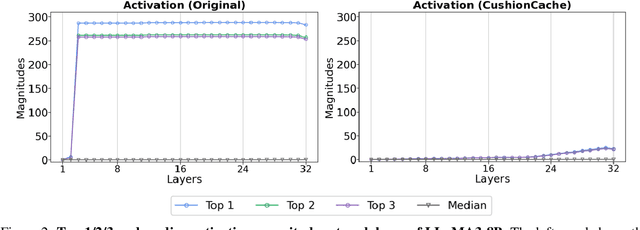
Despite recent advances in LLM quantization, activation quantization remains to be challenging due to the activation outliers. Conventional remedies, e.g., mixing precisions for different channels, introduce extra overhead and reduce the speedup. In this work, we develop a simple yet effective strategy to facilitate per-tensor activation quantization by preventing the generation of problematic tokens. Precisely, we propose a method to find a set of key-value cache, coined CushionCache, which mitigates outliers in subsequent tokens when inserted as a prefix. CushionCache works in two steps: First, we greedily search for a prompt token sequence that minimizes the maximum activation values in subsequent tokens. Then, we further tune the token cache to regularize the activations of subsequent tokens to be more quantization-friendly. The proposed method successfully addresses activation outliers of LLMs, providing a substantial performance boost for per-tensor activation quantization methods. We thoroughly evaluate our method over a wide range of models and benchmarks and find that it significantly surpasses the established baseline of per-tensor W8A8 quantization and can be seamlessly integrated with the recent activation quantization method.