 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ReturnZero System for VoxCeleb Speaker Recognition Challenge 2022
Sep 21, 2022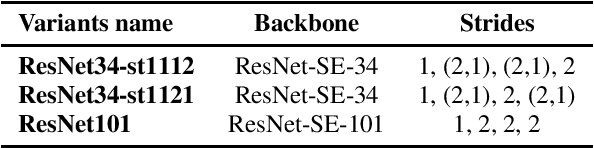
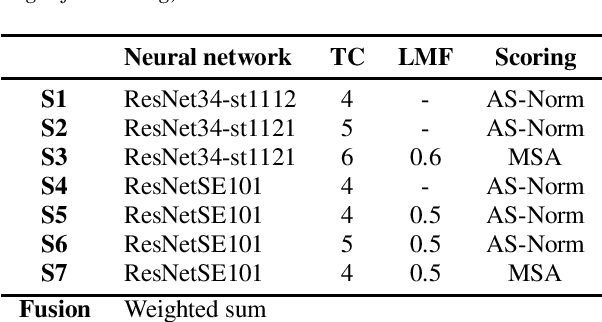
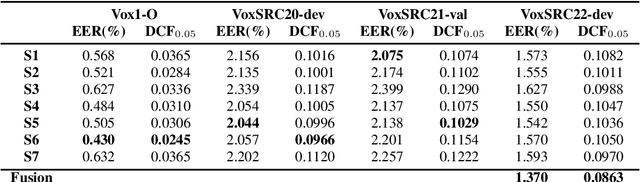
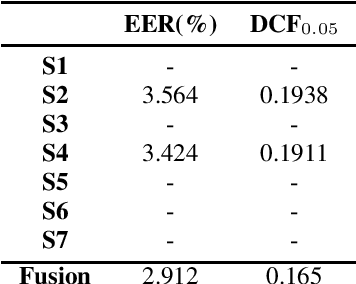
In this paper, we describe the top-scoring submissions for team RTZR VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22) in the closed dataset, speaker verification Track 1. The top performed system is a fusion of 7 models, which contains 3 different types of model architectures. We focus on training models to learn extra-temporal information. Therefore, all models were trained with 4-6 second frames for each utterance. Also, we apply the Large Margin Fine-tuning strategy which has shown good performance on the previous challenges for some of our fusion models. While the evaluation process, we apply the scoring methods with adaptive symmetric normalization (AS-Norm) and matrix score average (MSA). Finally, we mix up models with logistic regression to fuse all the trained models. The final submission achieves 0.165 DCF and 2.912% EER on the VoxSRC22 test set.