 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilent Abandonment in Text-Based Contact Centers: Identifying, Quantifying, and Mitigating its Operational Impacts
Jan 16, 2025In the quest to improve services, companies offer customers the option to interact with agents via texting. Such contact centers face unique challenges compared to traditional call centers, as measuring customer experience proxies like abandonment and patience involves uncertainty. A key source of this uncertainty is silent abandonment, where customers leave without notifying the system, wasting agent time and leaving their status unclear. Silent abandonment also obscures whether a customer was served or left. Our goals are to measure the magnitude of silent abandonment and mitigate its effects. Classification models show that 3%-70% of customers across 17 companies abandon silently. In one study, 71.3% of abandoning customers did so silently, reducing agent efficiency by 3.2% and system capacity by 15.3%, incurring $5,457 in annual costs per agent. We develop an expectation-maximization (EM) algorithm to estimate customer patience under uncertainty and identify influencing covariates. We find that companies should use classification models to estimate abandonment scope and our EM algorithm to assess patience. We suggest strategies to operationally mitigate the impact of silent abandonment by predicting suspected silent-abandonment behavior or changing service design. Specifically, we show that while allowing customers to write while waiting in the queue creates a missing data challenge, it also significantly increases patience and reduces service time, leading to reduced abandonment and lower staffing requirements.
Fair Class-Incremental Learning using Sample Weighting
Oct 02, 2024Model fairness is becoming important in class-incremental learning for Trustworthy AI. While accuracy has been a central focus in class-incremental learning, fairness has been relatively understudied. However, naively using all the samples of the current task for training results in unfair catastrophic forgetting for certain sensitive groups including classes. We theoretically analyze that forgetting occurs if the average gradient vector of the current task data is in an "opposite direction" compared to the average gradient vector of a sensitive group, which means their inner products are negative. We then propose a fair class-incremental learning framework that adjusts the training weights of current task samples to change the direction of the average gradient vector and thus reduce the forgetting of underperforming groups and achieve fairness. For various group fairness measures, we formulate optimization problems to minimize the overall losses of sensitive groups while minimizing the disparities among them. We also show the problems can be solved with linear programming and propose an efficient Fairness-aware Sample Weighting (FSW) algorithm. Experiments show that FSW achieves better accuracy-fairness tradeoff results than state-of-the-art approaches on real datasets.
Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System
Mar 11, 2024



The recent huge advance of Large Language Models (LLMs) is mainly driven by the increase in the number of parameters. This has led to substantial memory capacity requirements, necessitating the use of dozens of GPUs just to meet the capacity. One popular solution to this is storage-offloaded training, which uses host memory and storage as an extended memory hierarchy. However, this obviously comes at the cost of storage bandwidth bottleneck because storage devices have orders of magnitude lower bandwidth compared to that of GPU device memories. Our work, Smart-Infinity, addresses the storage bandwidth bottleneck of storage-offloaded LLM training using near-storage processing devices on a real system. The main component of Smart-Infinity is SmartUpdate, which performs parameter updates on custom near-storage accelerators. We identify that moving parameter updates to the storage side removes most of the storage traffic. In addition, we propose an efficient data transfer handler structure to address the system integration issues for Smart-Infinity. The handler allows overlapping data transfers with fixed memory consumption by reusing the device buffer. Lastly, we propose accelerator-assisted gradient compression/decompression to enhance the scalability of Smart-Infinity. When scaling to multiple near-storage processing devices, the write traffic on the shared channel becomes the bottleneck. To alleviate this, we compress the gradients on the GPU and decompress them on the accelerators. It provides further acceleration from reduced traffic. As a result, Smart-Infinity achieves a significant speedup compared to the baseline. Notably, Smart-Infinity is a ready-to-use approach that is fully integrated into PyTorch on a real system. We will open-source Smart-Infinity to facilitate its use.
Falcon: Fair Active Learning using Multi-armed Bandits
Jan 24, 2024



Biased data can lead to unfair machine learning models, highlighting the importance of embedding fairness at the beginning of data analysis, particularly during dataset curation and labeling. In response, we propose Falcon, a scalable fair active learning framework. Falcon adopts a data-centric approach that improves machine learning model fairness via strategic sample selection. Given a user-specified group fairness measure, Falcon identifies samples from "target groups" (e.g., (attribute=female, label=positive)) that are the most informative for improving fairness. However, a challenge arises since these target groups are defined using ground truth labels that are not available during sample selection. To handle this, we propose a novel trial-and-error method, where we postpone using a sample if the predicted label is different from the expected one and falls outside the target group. We also observe the trade-off that selecting more informative samples results in higher likelihood of postponing due to undesired label prediction, and the optimal balance varies per dataset. We capture the trade-off between informativeness and postpone rate as policies and propose to automatically select the best policy using adversarial multi-armed bandit methods, given their computational efficiency and theoretical guarantees. Experiments show that Falcon significantly outperforms existing fair active learning approaches in terms of fairness and accuracy and is more efficient. In particular, only Falcon supports a proper trade-off between accuracy and fairness where its maximum fairness score is 1.8-4.5x higher than the second-best results.
A Hybrid Antenna Switching Scheme for Dynamic Channel Sounding
Apr 20, 2023Channel sounding is essential for the development of radio systems. One flexible strategy is the switched-array-based channel sounding, where antenna elements are activated at different time instants to measure the channel spatial characteristics. Although its hardware complexity is decreased due to fewer radio-frequency (RF) chains, sequentially switching the antenna elements can result in aliasing in the joint estimation of angles and Doppler frequencies of multipath components (MPCs). Therefore, pseudo-random switching has been proposed to mitigate such aliasing and increase estimation accuracy in both angular and Doppler domains. Nevertheless, the increased Doppler resolution could cause additional post-processing complexity of parameter estimation, which is relevant when the Doppler frequencies are not of interest, e.g., for spatial channel modeling. This paper proposes an improved hybrid sequential and random switching scheme. The primary purpose is to maintain the estimation accuracy of angles of MPCs while decreasing the resolution of Doppler frequencies for minimized complexity of channel parameter estimation. A simulated-annealing algorithm is exploited to obtain an optimized switching sequence. The effectiveness of the proposed scheme is also demonstrated with a realistic antenna array.
iFlipper: Label Flipping for Individual Fairness
Sep 15, 2022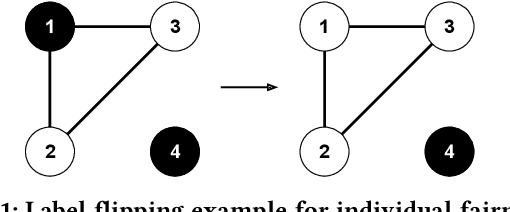
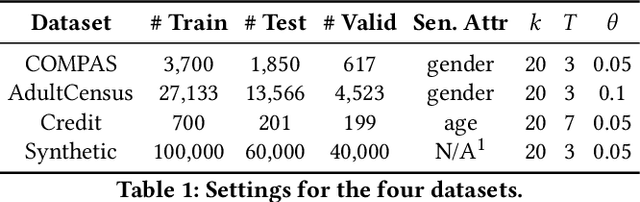
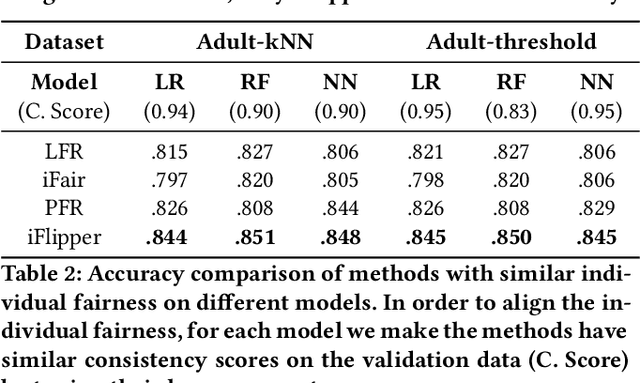
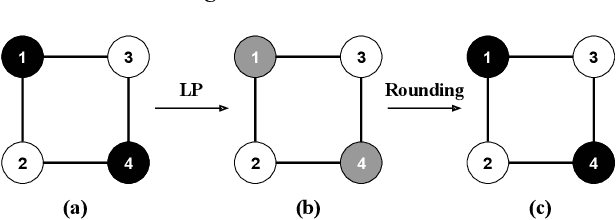
As machine learning becomes prevalent, mitigating any unfairness present in the training data becomes critical. Among the various notions of fairness, this paper focuses on the well-known individual fairness, which states that similar individuals should be treated similarly. While individual fairness can be improved when training a model (in-processing), we contend that fixing the data before model training (pre-processing) is a more fundamental solution. In particular, we show that label flipping is an effective pre-processing technique for improving individual fairness. Our system iFlipper solves the optimization problem of minimally flipping labels given a limit to the individual fairness violations, where a violation occurs when two similar examples in the training data have different labels. We first prove that the problem is NP-hard. We then propose an approximate linear programming algorithm and provide theoretical guarantees on how close its result is to the optimal solution in terms of the number of label flips. We also propose techniques for making the linear programming solution more optimal without exceeding the violations limit. Experiments on real datasets show that iFlipper significantly outperforms other pre-processing baselines in terms of individual fairness and accuracy on unseen test sets. In addition, iFlipper can be combined with in-processing techniques for even better results.
Learning a high-dimensional classification rule using auxiliary outcomes
Nov 11, 2020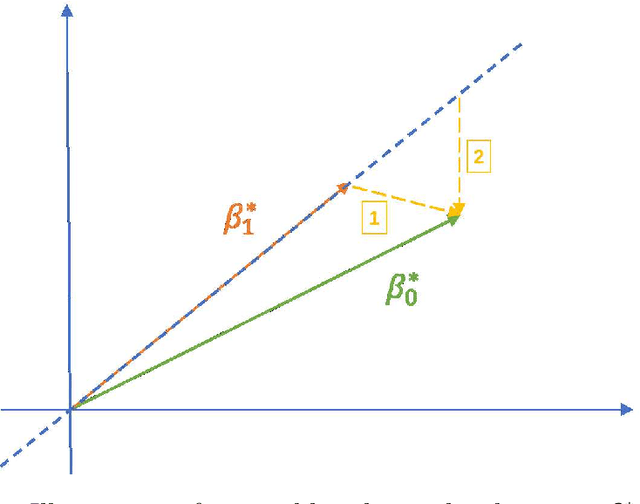
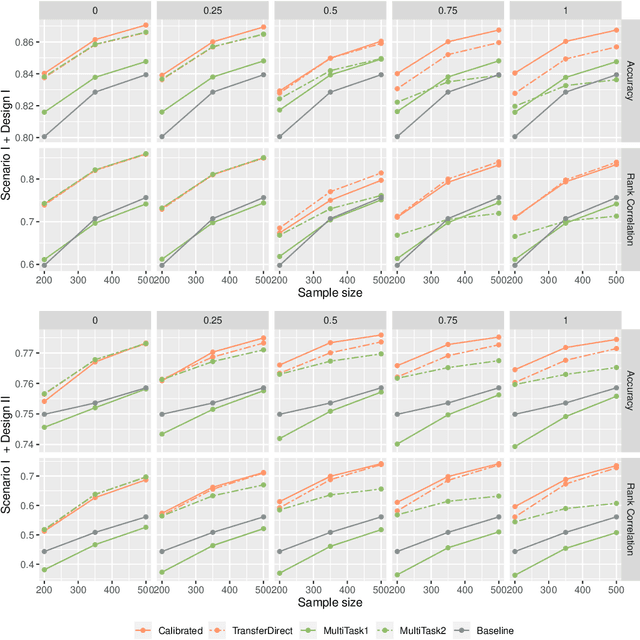
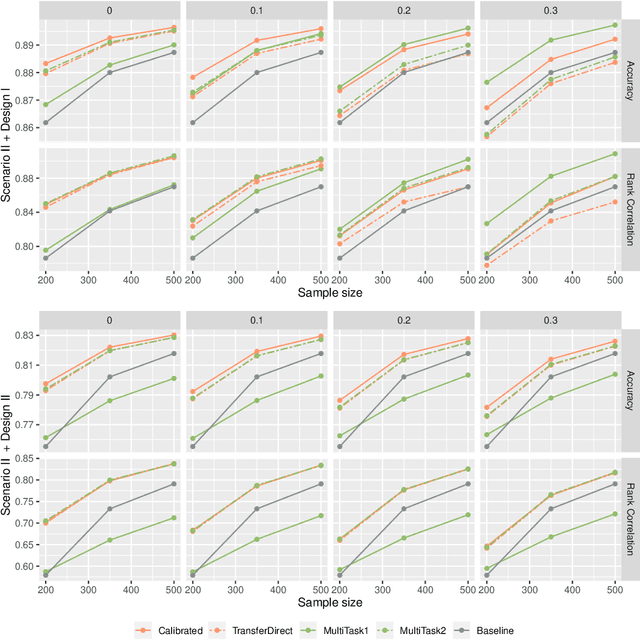
Correlated outcomes are common in many practical problems. Based on a decomposition of estimation bias into two types, within-subspace and against-subspace, we develop a robust approach to estimating the classification rule for the outcome of interest with the presence of auxiliary outcomes in high-dimensional settings. The proposed method includes a pooled estimation step using all outcomes to gain efficiency, and a subsequent calibration step using only the outcome of interest to correct both types of biases. We show that when the pooled estimator has a low estimation error and a sparse against-subspace bias, the calibrated estimator can achieve a lower estimation error than that when using only the single outcome of interest. An inference procedure for the calibrated estimator is also provided. Simulations and a real data analysis are conducted to justify the superiority of the proposed method.