 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon: Fair Active Learning using Multi-armed Bandits
Jan 24, 2024



Biased data can lead to unfair machine learning models, highlighting the importance of embedding fairness at the beginning of data analysis, particularly during dataset curation and labeling. In response, we propose Falcon, a scalable fair active learning framework. Falcon adopts a data-centric approach that improves machine learning model fairness via strategic sample selection. Given a user-specified group fairness measure, Falcon identifies samples from "target groups" (e.g., (attribute=female, label=positive)) that are the most informative for improving fairness. However, a challenge arises since these target groups are defined using ground truth labels that are not available during sample selection. To handle this, we propose a novel trial-and-error method, where we postpone using a sample if the predicted label is different from the expected one and falls outside the target group. We also observe the trade-off that selecting more informative samples results in higher likelihood of postponing due to undesired label prediction, and the optimal balance varies per dataset. We capture the trade-off between informativeness and postpone rate as policies and propose to automatically select the best policy using adversarial multi-armed bandit methods, given their computational efficiency and theoretical guarantees. Experiments show that Falcon significantly outperforms existing fair active learning approaches in terms of fairness and accuracy and is more efficient. In particular, only Falcon supports a proper trade-off between accuracy and fairness where its maximum fairness score is 1.8-4.5x higher than the second-best results.
iFlipper: Label Flipping for Individual Fairness
Sep 15, 2022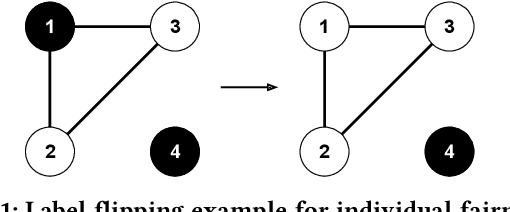
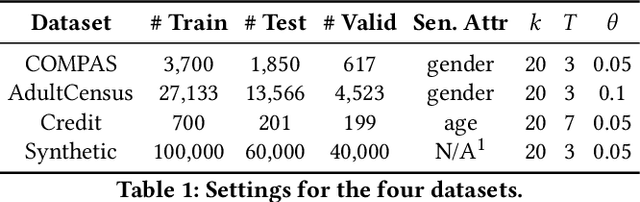
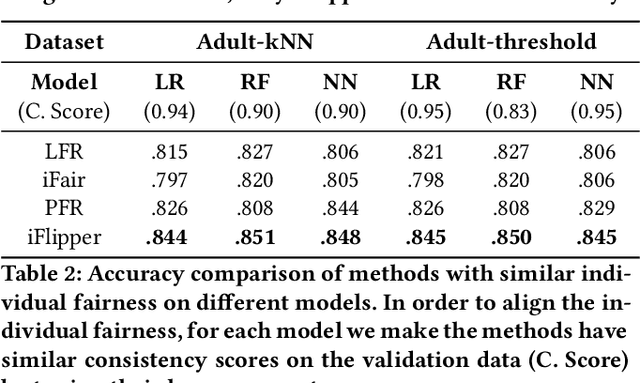
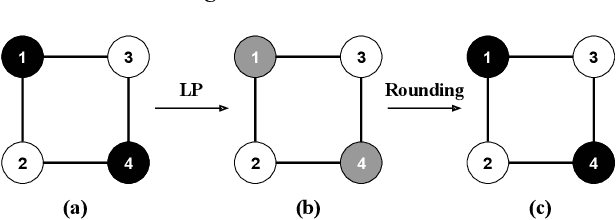
As machine learning becomes prevalent, mitigating any unfairness present in the training data becomes critical. Among the various notions of fairness, this paper focuses on the well-known individual fairness, which states that similar individuals should be treated similarly. While individual fairness can be improved when training a model (in-processing), we contend that fixing the data before model training (pre-processing) is a more fundamental solution. In particular, we show that label flipping is an effective pre-processing technique for improving individual fairness. Our system iFlipper solves the optimization problem of minimally flipping labels given a limit to the individual fairness violations, where a violation occurs when two similar examples in the training data have different labels. We first prove that the problem is NP-hard. We then propose an approximate linear programming algorithm and provide theoretical guarantees on how close its result is to the optimal solution in terms of the number of label flips. We also propose techniques for making the linear programming solution more optimal without exceeding the violations limit. Experiments on real datasets show that iFlipper significantly outperforms other pre-processing baselines in terms of individual fairness and accuracy on unseen test sets. In addition, iFlipper can be combined with in-processing techniques for even better results.
Responsible AI Challenges in End-to-end Machine Learning
Jan 15, 2021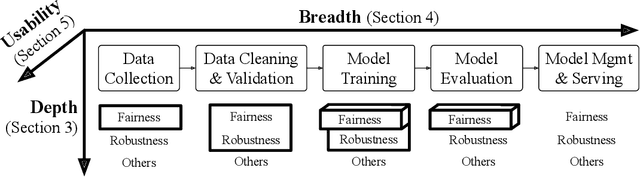
Responsible AI is becoming critical as AI is widely used in our everyday lives. Many companies that deploy AI publicly state that when training a model, we not only need to improve its accuracy, but also need to guarantee that the model does not discriminate against users (fairness), is resilient to noisy or poisoned data (robustness), is explainable, and more. In addition, these objectives are not only relevant to model training, but to all steps of end-to-end machine learning, which include data collection, data cleaning and validation, model training, model evaluation, and model management and serving. Finally, responsible AI is conceptually challenging, and supporting all the objectives must be as easy as possible. We thus propose three key research directions towards this vision - depth, breadth, and usability - to measure progress and introduce our ongoing research. First, responsible AI must be deeply supported where multiple objectives like fairness and robust must be handled together. To this end, we propose FR-Train, a holistic framework for fair and robust model training in the presence of data bias and poisoning. Second, responsible AI must be broadly supported, preferably in all steps of machine learning. Currently we focus on the data pre-processing steps and propose Slice Tuner, a selective data acquisition framework for training fair and accurate models, and MLClean, a data cleaning framework that also improves fairness and robustness. Finally, responsible AI must be usable where the techniques must be easy to deploy and actionable. We propose FairBatch, a batch selection approach for fairness that is effective and simple to use, and Slice Finder, a model evaluation tool that automatically finds problematic slices. We believe we scratched the surface of responsible AI for end-to-end machine learning and suggest research challenges moving forward.
Slice Tuner: A Selective Data Collection Framework for Accurate and Fair Machine Learning Models
Mar 10, 2020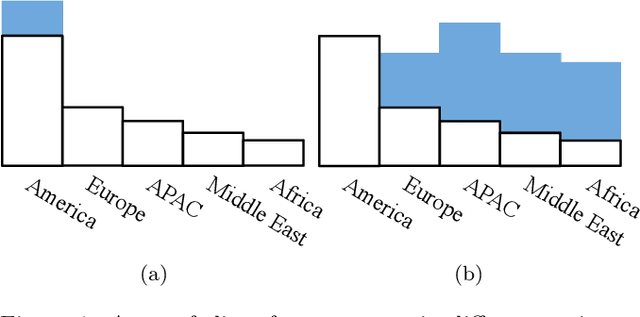

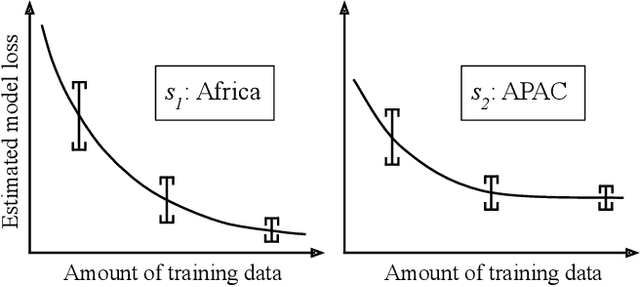
As machine learning becomes democratized in the era of Software 2.0, one of the most serious bottlenecks is collecting enough labeled data to ensure accurate and fair models. Recent techniques including crowdsourcing provide cost-effective ways to gather such data. However, simply collecting data as much as possible is not necessarily an effective strategy for optimizing accuracy and fairness. For example, if an online app store has enough training data for certain slices of data (say American customers), but not for others, collecting more American customer data will only bias the model training. Instead, we contend that one needs to selectively collect data and propose Slice Tuner, which collects possibly-different amounts of data per slice such that the model accuracy and fairness on all slices are optimized. At its core, Slice Tuner maintains learning curves of slices that estimate the model accuracies given more data and uses convex optimization to find the best data collection strategy. The key challenges of estimating learning curves are that they may be inaccurate if there is not enough data, and there may be dependencies among slices where collecting data for one slice influences the learning curves of others. We solve these issues by iteratively and efficiently updating the learning curves as more data is collected. We evaluate Slice Tuner on real datasets using crowdsourcing for data collection and show that Slice Tuner significantly outperforms baselines in terms of model accuracy and fairness, even for initially small slices. We believe Slice Tuner is a practical tool for suggesting concrete action items based on model analysis.
Data Cleaning for Accurate, Fair, and Robust Models: A Big Data - AI Integration Approach
Apr 22, 2019
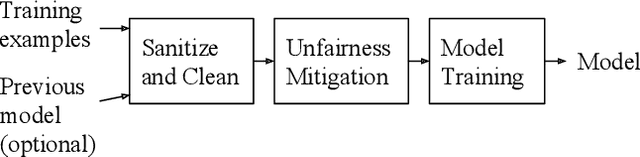
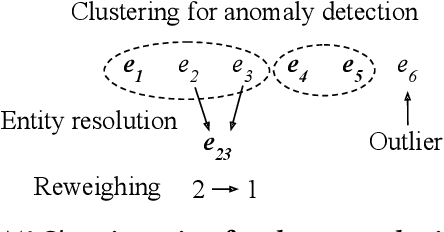
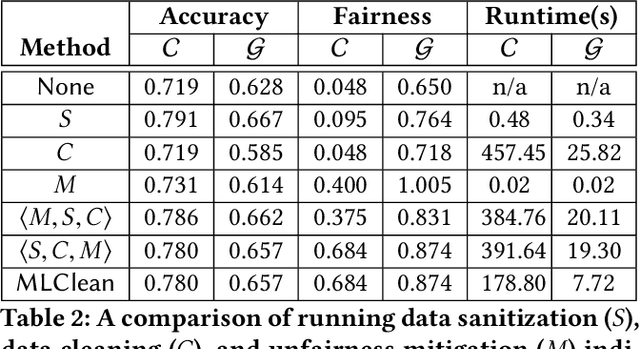
The wide use of machine learning is fundamentally changing the software development paradigm (a.k.a. Software 2.0) where data becomes a first-class citizen, on par with code. As machine learning is used in sensitive applications, it becomes imperative that the trained model is accurate, fair, and robust to attacks. While many techniques have been proposed to improve the model training process (in-processing approach) or the trained model itself (post-processing), we argue that the most effective method is to clean the root cause of error: the data the model is trained on (pre-processing). Historically, there are at least three research communities that have been separately studying this problem: data management, machine learning (model fairness), and security. Although a significant amount of research has been done by each community, ultimately the same datasets must be preprocessed, and there is little understanding how the techniques relate to each other and can possibly be integrated. We contend that it is time to extend the notion of data cleaning for modern machine learning needs. We identify dependencies among the data preprocessing techniques and propose MLClean, a unified data cleaning framework that integrates the techniques and helps train accurate and fair models. This work is part of a broader trend of Big data -- Artificial Intelligence (AI) integration.