 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon: Fair Active Learning using Multi-armed Bandits
Jan 24, 2024



Biased data can lead to unfair machine learning models, highlighting the importance of embedding fairness at the beginning of data analysis, particularly during dataset curation and labeling. In response, we propose Falcon, a scalable fair active learning framework. Falcon adopts a data-centric approach that improves machine learning model fairness via strategic sample selection. Given a user-specified group fairness measure, Falcon identifies samples from "target groups" (e.g., (attribute=female, label=positive)) that are the most informative for improving fairness. However, a challenge arises since these target groups are defined using ground truth labels that are not available during sample selection. To handle this, we propose a novel trial-and-error method, where we postpone using a sample if the predicted label is different from the expected one and falls outside the target group. We also observe the trade-off that selecting more informative samples results in higher likelihood of postponing due to undesired label prediction, and the optimal balance varies per dataset. We capture the trade-off between informativeness and postpone rate as policies and propose to automatically select the best policy using adversarial multi-armed bandit methods, given their computational efficiency and theoretical guarantees. Experiments show that Falcon significantly outperforms existing fair active learning approaches in terms of fairness and accuracy and is more efficient. In particular, only Falcon supports a proper trade-off between accuracy and fairness where its maximum fairness score is 1.8-4.5x higher than the second-best results.
iFlipper: Label Flipping for Individual Fairness
Sep 15, 2022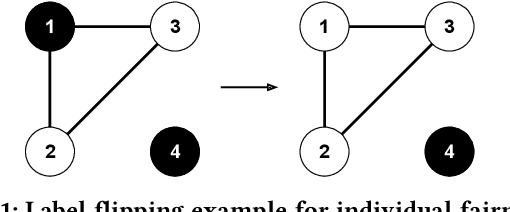
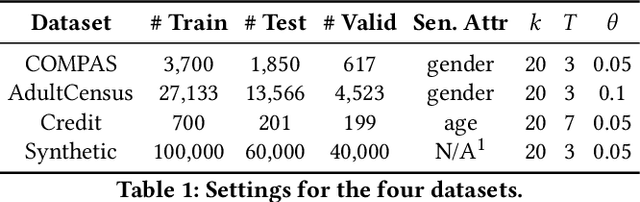
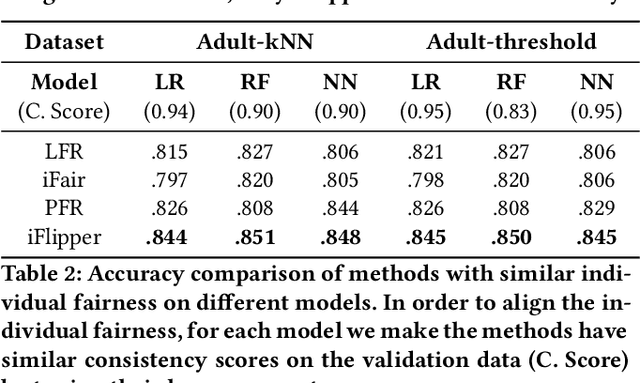
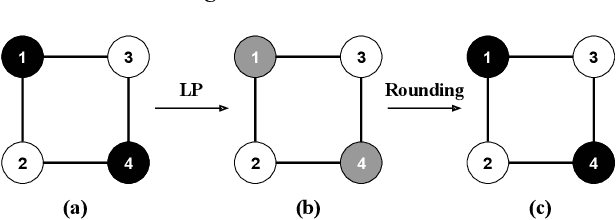
As machine learning becomes prevalent, mitigating any unfairness present in the training data becomes critical. Among the various notions of fairness, this paper focuses on the well-known individual fairness, which states that similar individuals should be treated similarly. While individual fairness can be improved when training a model (in-processing), we contend that fixing the data before model training (pre-processing) is a more fundamental solution. In particular, we show that label flipping is an effective pre-processing technique for improving individual fairness. Our system iFlipper solves the optimization problem of minimally flipping labels given a limit to the individual fairness violations, where a violation occurs when two similar examples in the training data have different labels. We first prove that the problem is NP-hard. We then propose an approximate linear programming algorithm and provide theoretical guarantees on how close its result is to the optimal solution in terms of the number of label flips. We also propose techniques for making the linear programming solution more optimal without exceeding the violations limit. Experiments on real datasets show that iFlipper significantly outperforms other pre-processing baselines in terms of individual fairness and accuracy on unseen test sets. In addition, iFlipper can be combined with in-processing techniques for even better results.
OmniFair: A Declarative System for Model-Agnostic Group Fairness in Machine Learning
Mar 13, 2021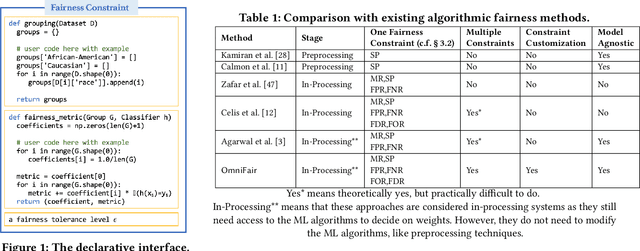

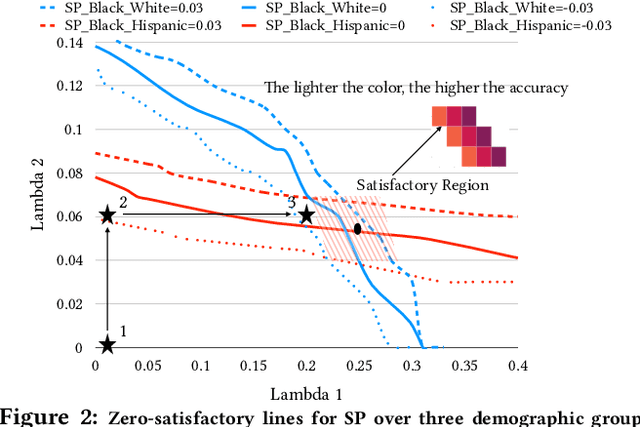

Machine learning (ML) is increasingly being used to make decisions in our society. ML models, however, can be unfair to certain demographic groups (e.g., African Americans or females) according to various fairness metrics. Existing techniques for producing fair ML models either are limited to the type of fairness constraints they can handle (e.g., preprocessing) or require nontrivial modifications to downstream ML training algorithms (e.g., in-processing). We propose a declarative system OmniFair for supporting group fairness in ML. OmniFair features a declarative interface for users to specify desired group fairness constraints and supports all commonly used group fairness notions, including statistical parity, equalized odds, and predictive parity. OmniFair is also model-agnostic in the sense that it does not require modifications to a chosen ML algorithm. OmniFair also supports enforcing multiple user declared fairness constraints simultaneously while most previous techniques cannot. The algorithms in OmniFair maximize model accuracy while meeting the specified fairness constraints, and their efficiency is optimized based on the theoretically provable monotonicity property regarding the trade-off between accuracy and fairness that is unique to our system. We conduct experiments on commonly used datasets that exhibit bias against minority groups in the fairness literature. We show that OmniFair is more versatile than existing algorithmic fairness approaches in terms of both supported fairness constraints and downstream ML models. OmniFair reduces the accuracy loss by up to $94.8\%$ compared with the second best method. OmniFair also achieves similar running time to preprocessing methods, and is up to $270\times$ faster than in-processing methods.
ALEX: An Updatable Adaptive Learned Index
May 21, 2019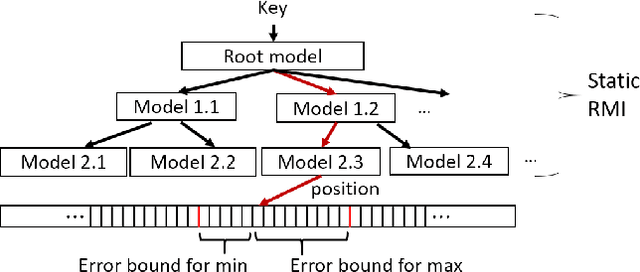

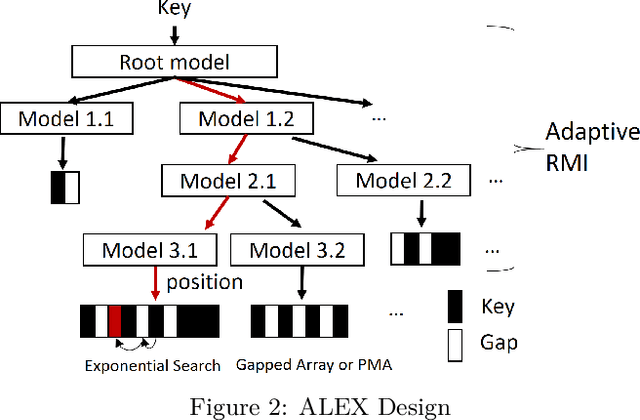
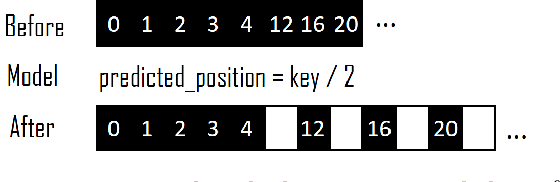
Recent work on "learned indexes" has revolutionized the way we look at the decades-old field of DBMS indexing. The key idea is that indexes are "models" that predict the position of a key in a dataset. Indexes can, thus, be learned. The original work by Kraska et al. shows surprising results in terms of search performance and space requirements: A learned index beats a B+Tree by a factor of up to three in search time and by an order of magnitude in memory footprint, however it is limited to static, read-only workloads. This paper presents a new class of learned indexes called ALEX which addresses issues that arise when implementing dynamic, updatable learned indexes. Compared to the learned index from Kraska et al., ALEX has up to 3000X lower space requirements, but has up to 2.7X higher search performance on static workloads. Compared to a B+Tree, ALEX achieves up to 3.5X and 3.3X higher performance on static and some dynamic workloads, respectively, with up to 5 orders of magnitude smaller index size. Our detailed experiments show that ALEX presents a key step towards making learned indexes practical for a broader class of database workloads with dynamic updates.
Accelerating Generalized Linear Models with MLWeaving: A One-Size-Fits-All System for Any-precision Learning (Technical Report)
Mar 28, 2019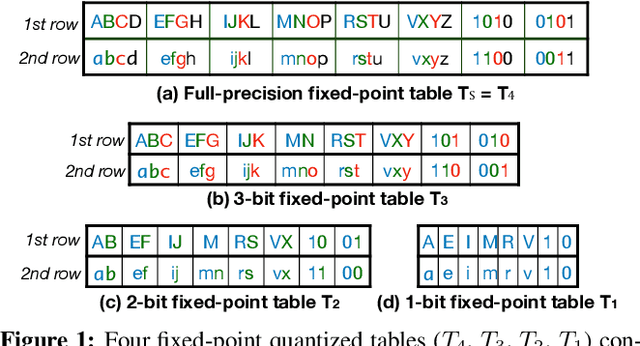
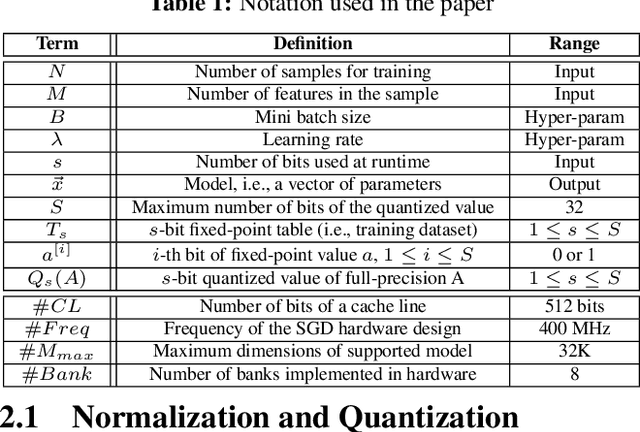
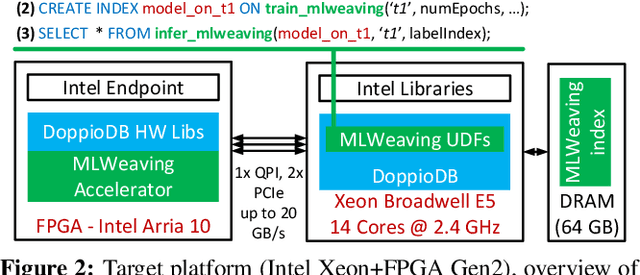
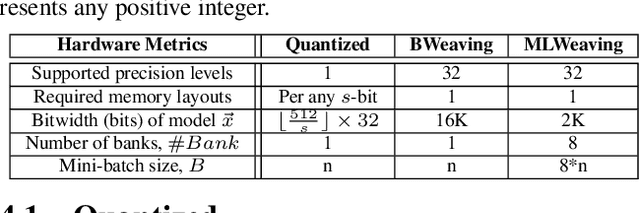
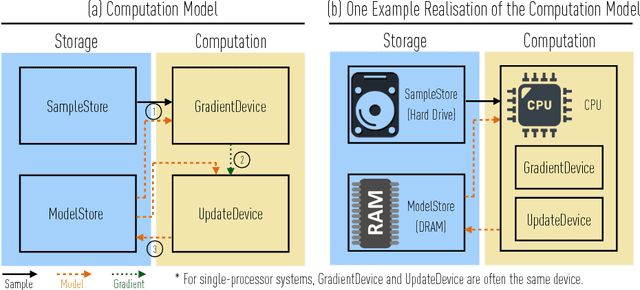
Learning from the data stored in a database is an important function increasingly available in relational engines. Methods using lower precision input data are of special interest given their overall higher efficiency but, in databases, these methods have a hidden cost: the quantization of the real value into a smaller number is an expensive step. To address the issue, in this paper we present MLWeaving, a data structure and hardware acceleration technique intended to speed up learning of generalized linear models in databases. ML-Weaving provides a compact, in-memory representation enabling the retrieval of data at any level of precision. MLWeaving also takes advantage of the increasing availability of FPGA-based accelerators to provide a highly efficient implementation of stochastic gradient descent. The solution adopted in MLWeaving is more efficient than existing designs in terms of space (since it can process any resolution on the same design) and resources (via the use of bit-serial multipliers). MLWeaving also enables the runtime tuning of precision, instead of a fixed precision level during the training. We illustrate this using a simple, dynamic precision schedule. Experimental results show MLWeaving achieves up to16 performance improvement over low-precision CPU implementations of first-order methods.
* 18 pages
MLBench: How Good Are Machine Learning Clouds for Binary Classification Tasks on Structured Data?
Oct 16, 2017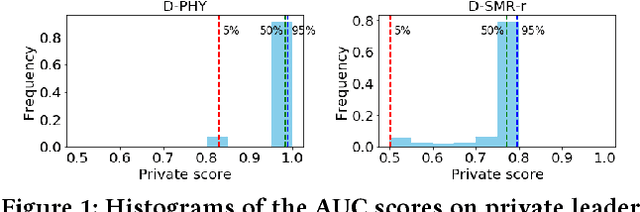
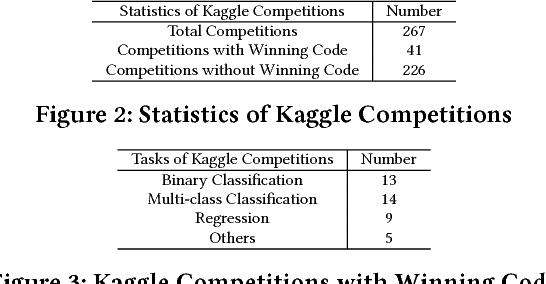
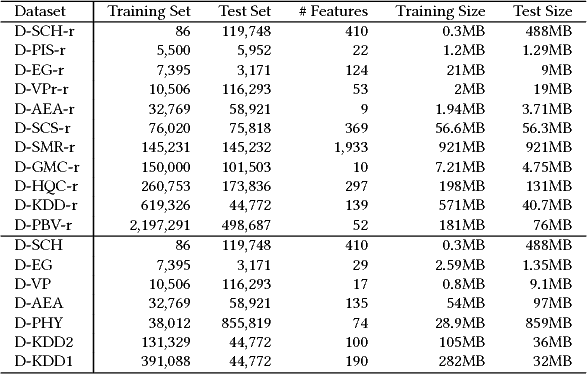
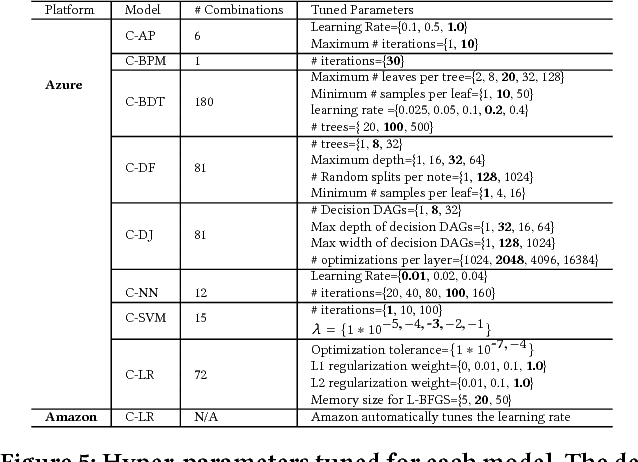
We conduct an empirical study of machine learning functionalities provided by major cloud service providers, which we call machine learning clouds. Machine learning clouds hold the promise of hiding all the sophistication of running large-scale machine learning: Instead of specifying how to run a machine learning task, users only specify what machine learning task to run and the cloud figures out the rest. Raising the level of abstraction, however, rarely comes free - a performance penalty is possible. How good, then, are current machine learning clouds on real-world machine learning workloads? We study this question with a focus on binary classication problems. We present mlbench, a novel benchmark constructed by harvesting datasets from Kaggle competitions. We then compare the performance of the top winning code available from Kaggle with that of running machine learning clouds from both Azure and Amazon on mlbench. Our comparative study reveals the strength and weakness of existing machine learning clouds and points out potential future directions for improvement.
The ZipML Framework for Training Models with End-to-End Low Precision: The Cans, the Cannots, and a Little Bit of Deep Learning
Jun 19, 2017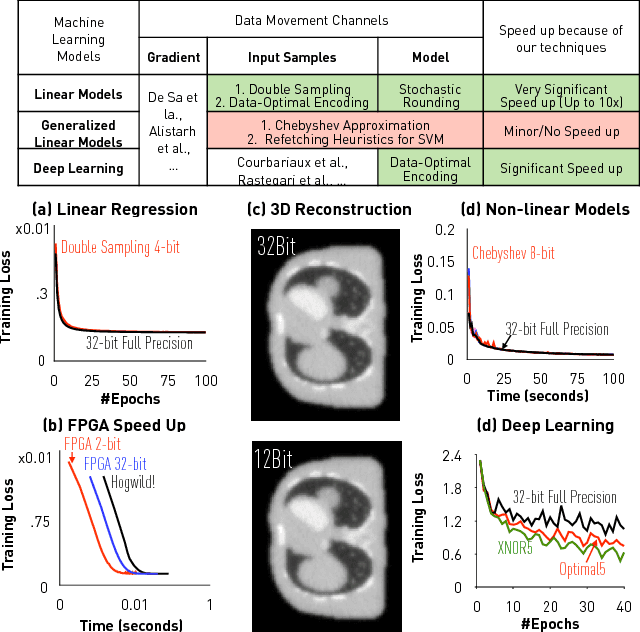
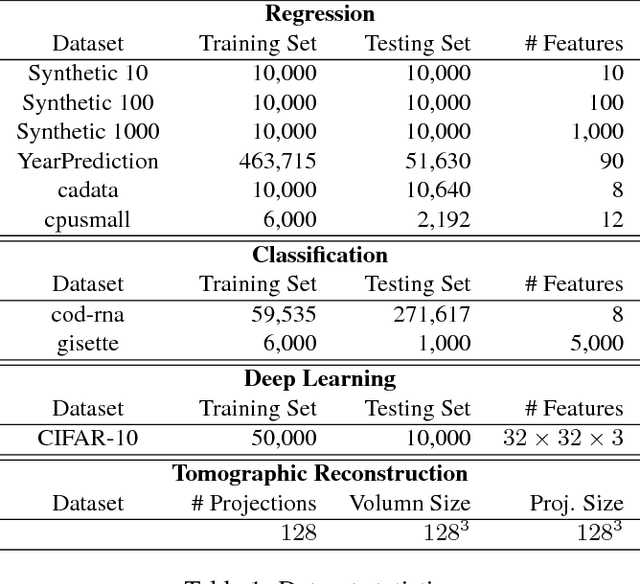
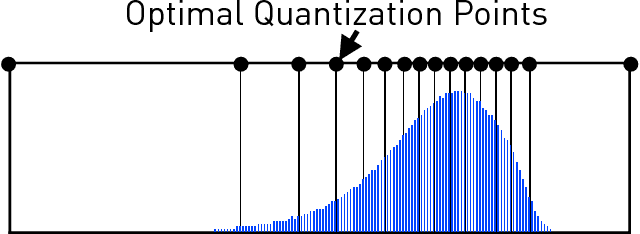
Recently there has been significant interest in training machine-learning models at low precision: by reducing precision, one can reduce computation and communication by one order of magnitude. We examine training at reduced precision, both from a theoretical and practical perspective, and ask: is it possible to train models at end-to-end low precision with provable guarantees? Can this lead to consistent order-of-magnitude speedups? We present a framework called ZipML to answer these questions. For linear models, the answer is yes. We develop a simple framework based on one simple but novel strategy called double sampling. Our framework is able to execute training at low precision with no bias, guaranteeing convergence, whereas naive quantization would introduce significant bias. We validate our framework across a range of applications, and show that it enables an FPGA prototype that is up to 6.5x faster than an implementation using full 32-bit precision. We further develop a variance-optimal stochastic quantization strategy and show that it can make a significant difference in a variety of settings. When applied to linear models together with double sampling, we save up to another 1.7x in data movement compared with uniform quantization. When training deep networks with quantized models, we achieve higher accuracy than the state-of-the-art XNOR-Net. Finally, we extend our framework through approximation to non-linear models, such as SVM. We show that, although using low-precision data induces bias, we can appropriately bound and control the bias. We find in practice 8-bit precision is often sufficient to converge to the correct solution. Interestingly, however, in practice we notice that our framework does not always outperform the naive rounding approach. We discuss this negative result in detail.
Generative Adversarial Networks recover features in astrophysical images of galaxies beyond the deconvolution limit
Feb 01, 2017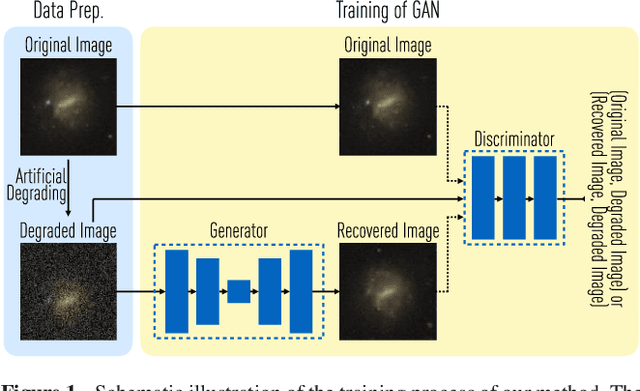
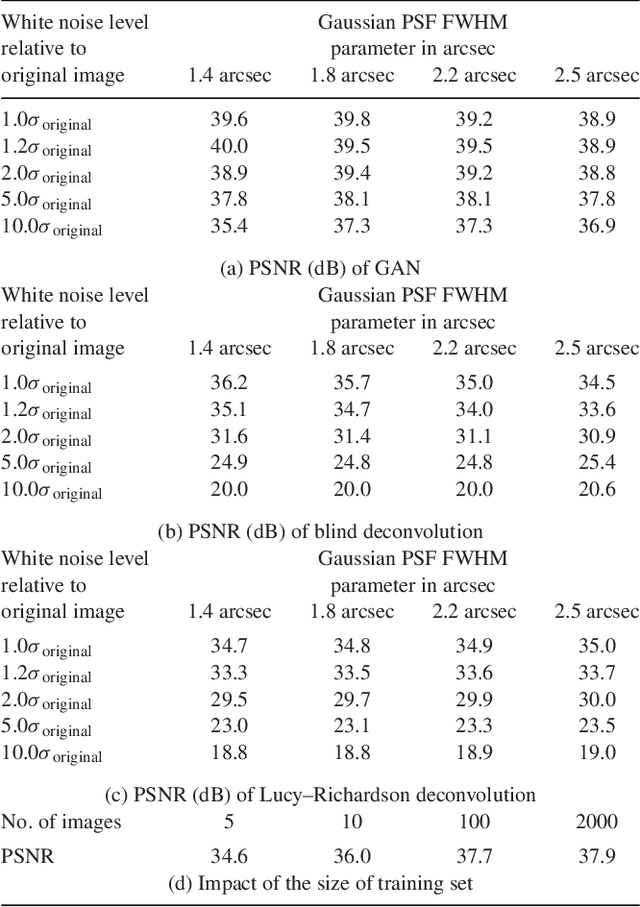
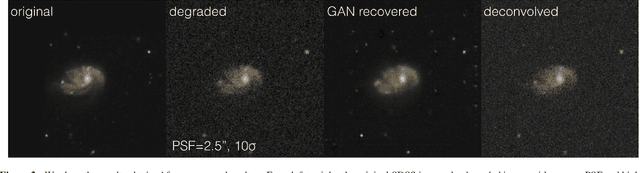

Observations of astrophysical objects such as galaxies are limited by various sources of random and systematic noise from the sky background, the optical system of the telescope and the detector used to record the data. Conventional deconvolution techniques are limited in their ability to recover features in imaging data by the Shannon-Nyquist sampling theorem. Here we train a generative adversarial network (GAN) on a sample of $4,550$ images of nearby galaxies at $0.01<z<0.02$ from the Sloan Digital Sky Survey and conduct $10\times$ cross validation to evaluate the results. We present a method using a GAN trained on galaxy images that can recover features from artificially degraded images with worse seeing and higher noise than the original with a performance which far exceeds simple deconvolution. The ability to better recover detailed features such as galaxy morphology from low-signal-to-noise and low angular resolution imaging data significantly increases our ability to study existing data sets of astrophysical objects as well as future observations with observatories such as the Large Synoptic Sky Telescope (LSST) and the Hubble and James Webb space telescopes.