 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQd-tree: Learning Data Layouts for Big Data Analytics
Apr 22, 2020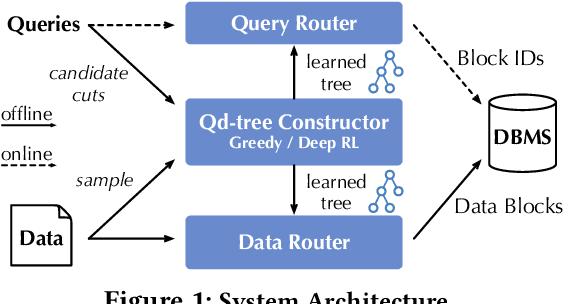

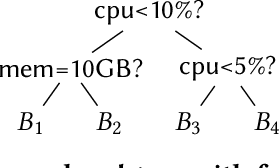
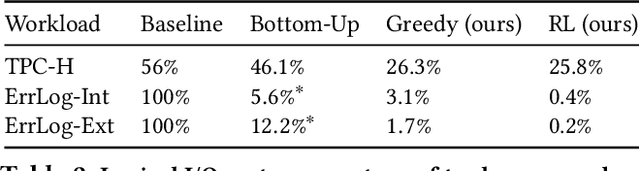
Corporations today collect data at an unprecedented and accelerating scale, making the need to run queries on large datasets increasingly important. Technologies such as columnar block-based data organization and compression have become standard practice in most commercial database systems. However, the problem of best assigning records to data blocks on storage is still open. For example, today's systems usually partition data by arrival time into row groups, or range/hash partition the data based on selected fields. For a given workload, however, such techniques are unable to optimize for the important metric of the number of blocks accessed by a query. This metric directly relates to the I/O cost, and therefore performance, of most analytical queries. Further, they are unable to exploit additional available storage to drive this metric down further. In this paper, we propose a new framework called a query-data routing tree, or qd-tree, to address this problem, and propose two algorithms for their construction based on greedy and deep reinforcement learning techniques. Experiments over benchmark and real workloads show that a qd-tree can provide physical speedups of more than an order of magnitude compared to current blocking schemes, and can reach within 2X of the lower bound for data skipping based on selectivity, while providing complete semantic descriptions of created blocks.
ALEX: An Updatable Adaptive Learned Index
May 21, 2019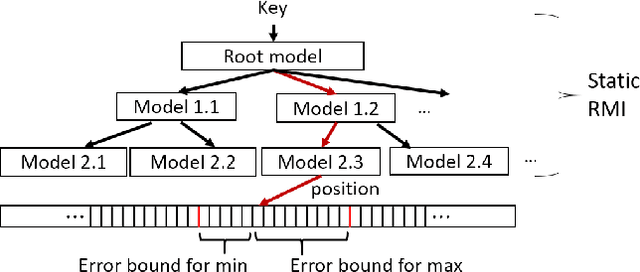

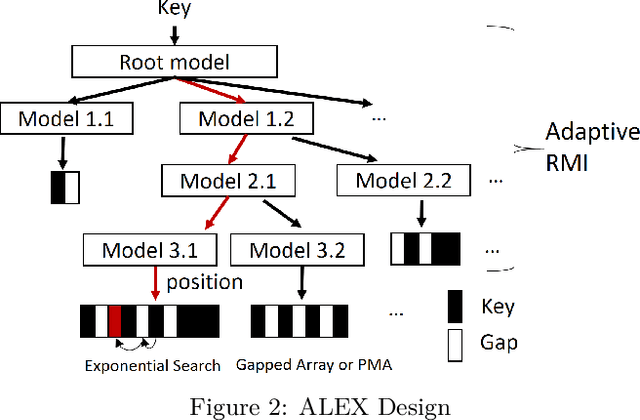
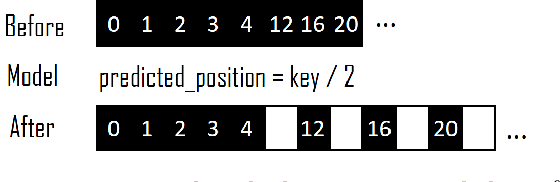
Recent work on "learned indexes" has revolutionized the way we look at the decades-old field of DBMS indexing. The key idea is that indexes are "models" that predict the position of a key in a dataset. Indexes can, thus, be learned. The original work by Kraska et al. shows surprising results in terms of search performance and space requirements: A learned index beats a B+Tree by a factor of up to three in search time and by an order of magnitude in memory footprint, however it is limited to static, read-only workloads. This paper presents a new class of learned indexes called ALEX which addresses issues that arise when implementing dynamic, updatable learned indexes. Compared to the learned index from Kraska et al., ALEX has up to 3000X lower space requirements, but has up to 2.7X higher search performance on static workloads. Compared to a B+Tree, ALEX achieves up to 3.5X and 3.3X higher performance on static and some dynamic workloads, respectively, with up to 5 orders of magnitude smaller index size. Our detailed experiments show that ALEX presents a key step towards making learned indexes practical for a broader class of database workloads with dynamic updates.
On Human Intellect and Machine Failures: Troubleshooting Integrative Machine Learning Systems
Nov 24, 2016


We study the problem of troubleshooting machine learning systems that rely on analytical pipelines of distinct components. Understanding and fixing errors that arise in such integrative systems is difficult as failures can occur at multiple points in the execution workflow. Moreover, errors can propagate, become amplified or be suppressed, making blame assignment difficult. We propose a human-in-the-loop methodology which leverages human intellect for troubleshooting system failures. The approach simulates potential component fixes through human computation tasks and measures the expected improvements in the holistic behavior of the system. The method provides guidance to designers about how they can best improve the system. We demonstrate the effectiveness of the approach on an automated image captioning system that has been pressed into real-world use.
Crowd Access Path Optimization: Diversity Matters
Aug 11, 2015
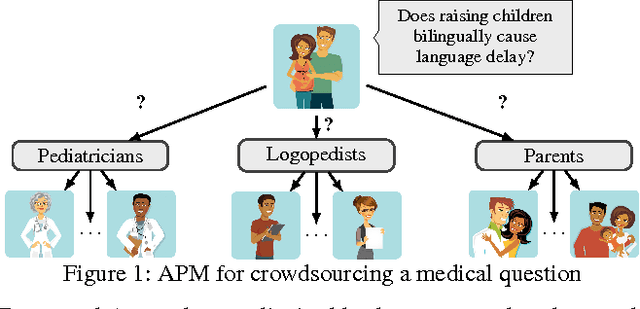
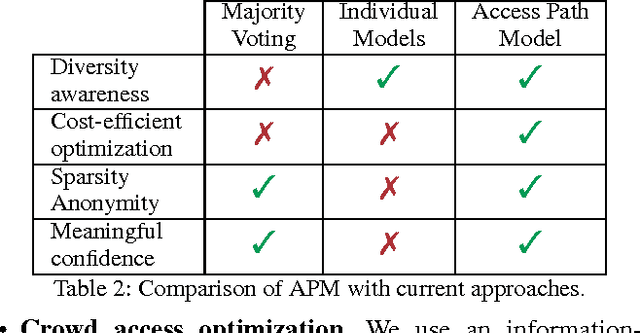
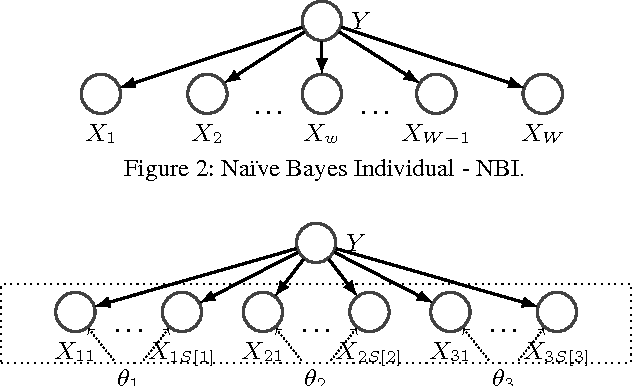
Quality assurance is one the most important challenges in crowdsourcing. Assigning tasks to several workers to increase quality through redundant answers can be expensive if asking homogeneous sources. This limitation has been overlooked by current crowdsourcing platforms resulting therefore in costly solutions. In order to achieve desirable cost-quality tradeoffs it is essential to apply efficient crowd access optimization techniques. Our work argues that optimization needs to be aware of diversity and correlation of information within groups of individuals so that crowdsourcing redundancy can be adequately planned beforehand. Based on this intuitive idea, we introduce the Access Path Model (APM), a novel crowd model that leverages the notion of access paths as an alternative way of retrieving information. APM aggregates answers ensuring high quality and meaningful confidence. Moreover, we devise a greedy optimization algorithm for this model that finds a provably good approximate plan to access the crowd. We evaluate our approach on three crowdsourced datasets that illustrate various aspects of the problem. Our results show that the Access Path Model combined with greedy optimization is cost-efficient and practical to overcome common difficulties in large-scale crowdsourcing like data sparsity and anonymity.
Discovering Valuable Items from Massive Data
Jun 02, 2015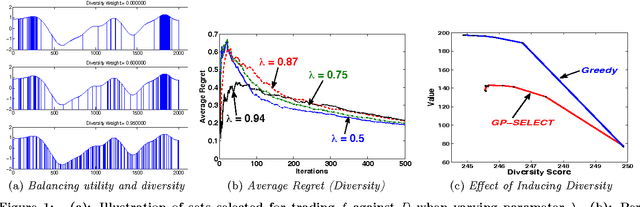
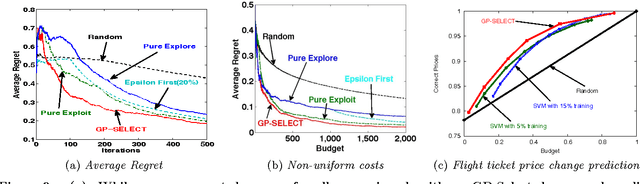
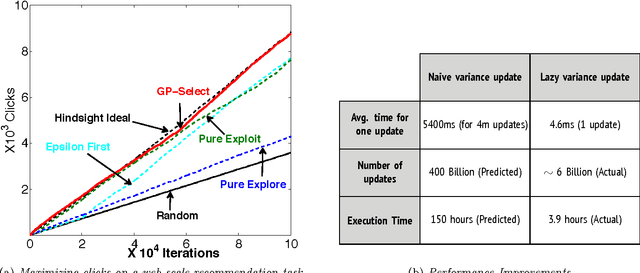
Suppose there is a large collection of items, each with an associated cost and an inherent utility that is revealed only once we commit to selecting it. Given a budget on the cumulative cost of the selected items, how can we pick a subset of maximal value? This task generalizes several important problems such as multi-arm bandits, active search and the knapsack problem. We present an algorithm, GP-Select, which utilizes prior knowledge about similarity be- tween items, expressed as a kernel function. GP-Select uses Gaussian process prediction to balance exploration (estimating the unknown value of items) and exploitation (selecting items of high value). We extend GP-Select to be able to discover sets that simultaneously have high utility and are diverse. Our preference for diversity can be specified as an arbitrary monotone submodular function that quantifies the diminishing returns obtained when selecting similar items. Furthermore, we exploit the structure of the model updates to achieve an order of magnitude (up to 40X) speedup in our experiments without resorting to approximations. We provide strong guarantees on the performance of GP-Select and apply it to three real-world case studies of industrial relevance: (1) Refreshing a repository of prices in a Global Distribution System for the travel industry, (2) Identifying diverse, binding-affine peptides in a vaccine de- sign task and (3) Maximizing clicks in a web-scale recommender system by recommending items to users.