 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Place Updates of a Graph Index for Streaming Approximate Nearest Neighbor Search
Feb 19, 2025Indices for approximate nearest neighbor search (ANNS) are a basic component for information retrieval and widely used in database, search, recommendation and RAG systems. In these scenarios, documents or other objects are inserted into and deleted from the working set at a high rate, requiring a stream of updates to the vector index. Algorithms based on proximity graph indices are the most efficient indices for ANNS, winning many benchmark competitions. However, it is challenging to update such graph index at a high rate, while supporting stable recall after many updates. Since the graph is singly-linked, deletions are hard because there is no fast way to find in-neighbors of a deleted vertex. Therefore, to update the graph, state-of-the-art algorithms such as FreshDiskANN accumulate deletions in a batch and periodically consolidate, removing edges to deleted vertices and modifying the graph to ensure recall stability. In this paper, we present IP-DiskANN (InPlaceUpdate-DiskANN), the first algorithm to avoid batch consolidation by efficiently processing each insertion and deletion in-place. Our experiments using standard benchmarks show that IP-DiskANN has stable recall over various lengthy update patterns in both high-recall and low-recall regimes. Further, its query throughput and update speed are better than using the batch consolidation algorithm and HNSW.
Qd-tree: Learning Data Layouts for Big Data Analytics
Apr 22, 2020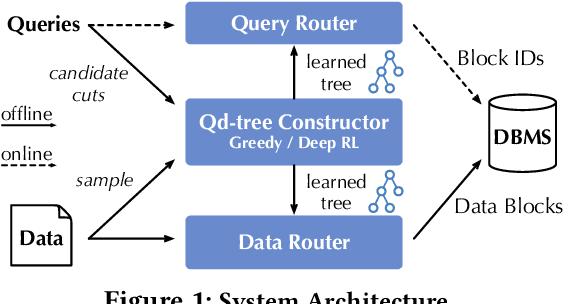

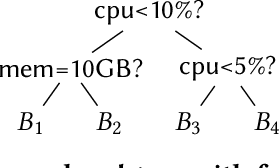
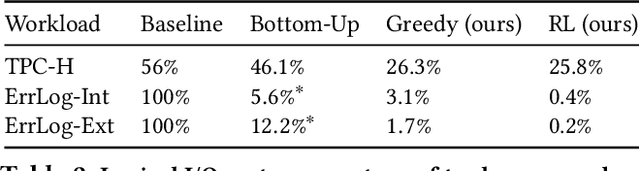
Corporations today collect data at an unprecedented and accelerating scale, making the need to run queries on large datasets increasingly important. Technologies such as columnar block-based data organization and compression have become standard practice in most commercial database systems. However, the problem of best assigning records to data blocks on storage is still open. For example, today's systems usually partition data by arrival time into row groups, or range/hash partition the data based on selected fields. For a given workload, however, such techniques are unable to optimize for the important metric of the number of blocks accessed by a query. This metric directly relates to the I/O cost, and therefore performance, of most analytical queries. Further, they are unable to exploit additional available storage to drive this metric down further. In this paper, we propose a new framework called a query-data routing tree, or qd-tree, to address this problem, and propose two algorithms for their construction based on greedy and deep reinforcement learning techniques. Experiments over benchmark and real workloads show that a qd-tree can provide physical speedups of more than an order of magnitude compared to current blocking schemes, and can reach within 2X of the lower bound for data skipping based on selectivity, while providing complete semantic descriptions of created blocks.
ALEX: An Updatable Adaptive Learned Index
May 21, 2019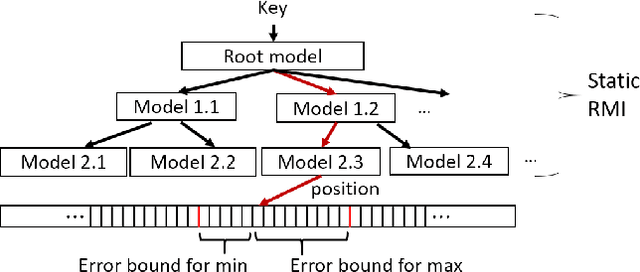

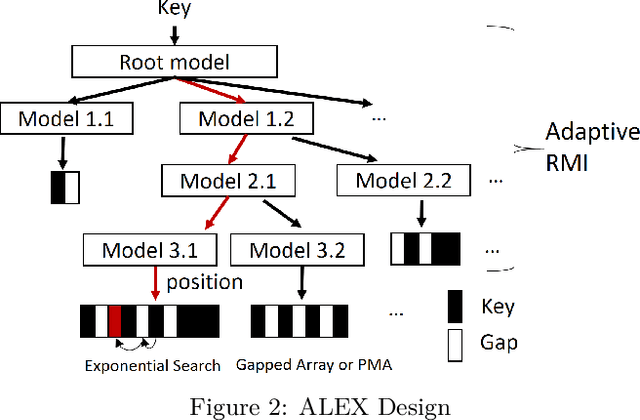
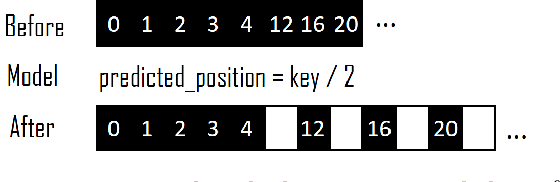
Recent work on "learned indexes" has revolutionized the way we look at the decades-old field of DBMS indexing. The key idea is that indexes are "models" that predict the position of a key in a dataset. Indexes can, thus, be learned. The original work by Kraska et al. shows surprising results in terms of search performance and space requirements: A learned index beats a B+Tree by a factor of up to three in search time and by an order of magnitude in memory footprint, however it is limited to static, read-only workloads. This paper presents a new class of learned indexes called ALEX which addresses issues that arise when implementing dynamic, updatable learned indexes. Compared to the learned index from Kraska et al., ALEX has up to 3000X lower space requirements, but has up to 2.7X higher search performance on static workloads. Compared to a B+Tree, ALEX achieves up to 3.5X and 3.3X higher performance on static and some dynamic workloads, respectively, with up to 5 orders of magnitude smaller index size. Our detailed experiments show that ALEX presents a key step towards making learned indexes practical for a broader class of database workloads with dynamic updates.
Streaming Algorithms for Pattern Discovery over Dynamically Changing Event Sequences
May 21, 2012
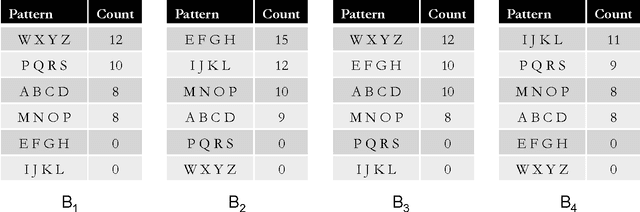
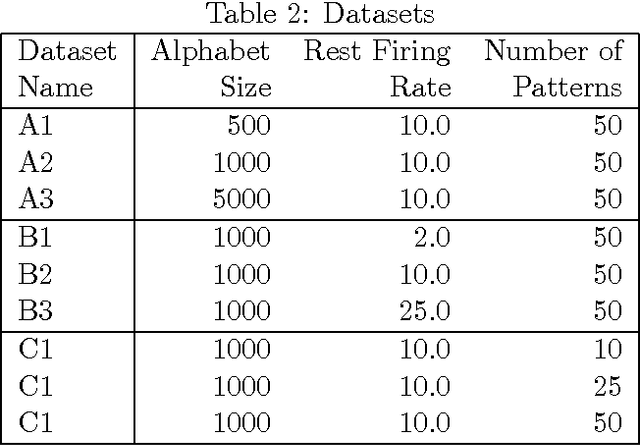
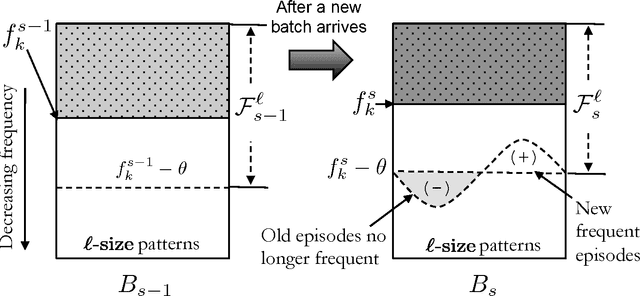
Discovering frequent episodes over event sequences is an important data mining task. In many applications, events constituting the data sequence arrive as a stream, at furious rates, and recent trends (or frequent episodes) can change and drift due to the dynamical nature of the underlying event generation process. The ability to detect and track such the changing sets of frequent episodes can be valuable in many application scenarios. Current methods for frequent episode discovery are typically multipass algorithms, making them unsuitable in the streaming context. In this paper, we propose a new streaming algorithm for discovering frequent episodes over a window of recent events in the stream. Our algorithm processes events as they arrive, one batch at a time, while discovering the top frequent episodes over a window consisting of several batches in the immediate past. We derive approximation guarantees for our algorithm under the condition that frequent episodes are approximately well-separated from infrequent ones in every batch of the window. We present extensive experimental evaluations of our algorithm on both real and synthetic data. We also present comparisons with baselines and adaptations of streaming algorithms from itemset mining literature.