 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Correction in Learning using SVMs
Jan 10, 2013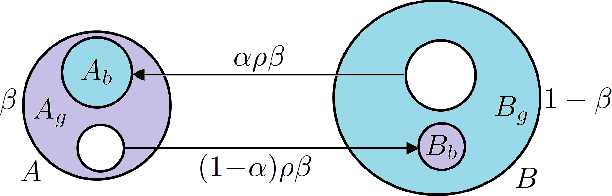
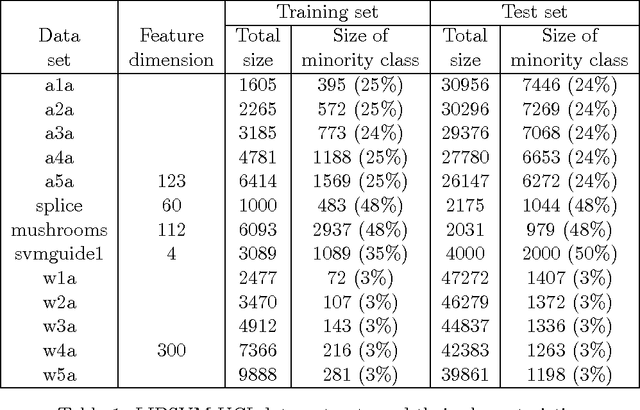
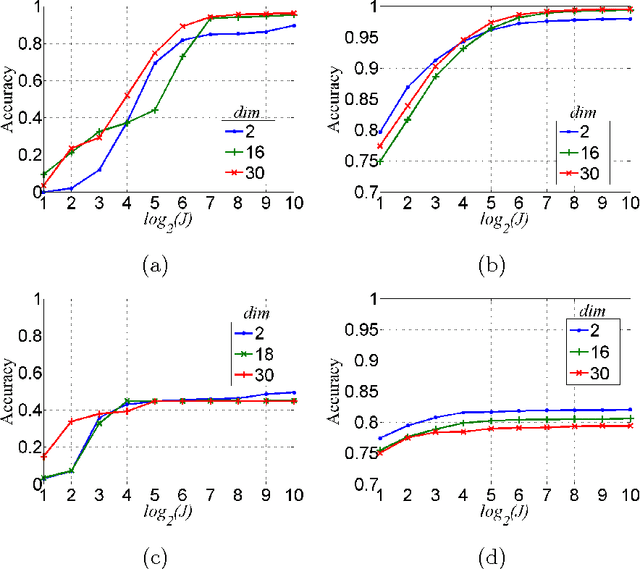
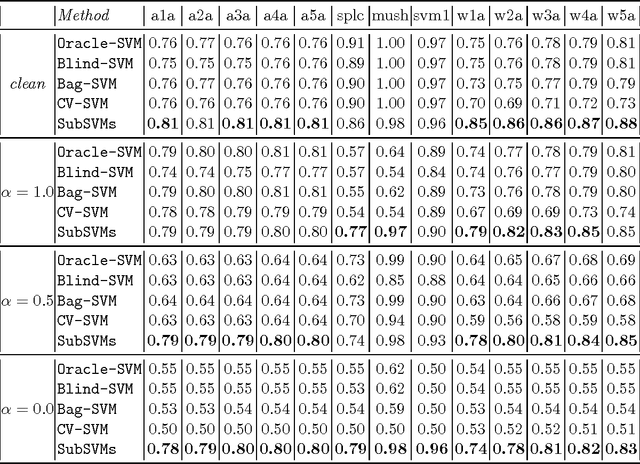
This paper is concerned with learning binary classifiers under adversarial label-noise. We introduce the problem of error-correction in learning where the goal is to recover the original clean data from a label-manipulated version of it, given (i) no constraints on the adversary other than an upper-bound on the number of errors, and (ii) some regularity properties for the original data. We present a simple and practical error-correction algorithm called SubSVMs that learns individual SVMs on several small-size (log-size), class-balanced, random subsets of the data and then reclassifies the training points using a majority vote. Our analysis reveals the need for the two main ingredients of SubSVMs, namely class-balanced sampling and subsampled bagging. Experimental results on synthetic as well as benchmark UCI data demonstrate the effectiveness of our approach. In addition to noise-tolerance, log-size subsampled bagging also yields significant run-time benefits over standard SVMs.
Streaming Algorithms for Pattern Discovery over Dynamically Changing Event Sequences
May 21, 2012
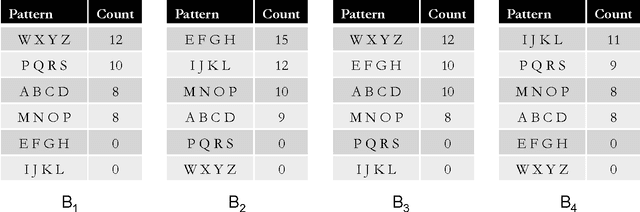
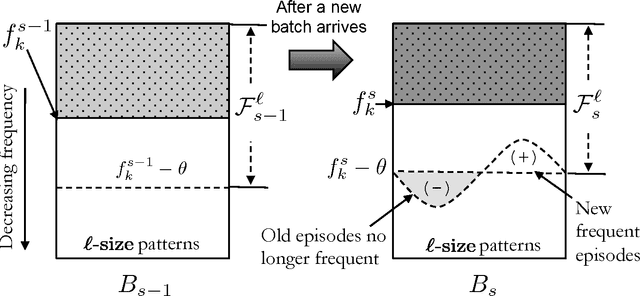
Discovering frequent episodes over event sequences is an important data mining task. In many applications, events constituting the data sequence arrive as a stream, at furious rates, and recent trends (or frequent episodes) can change and drift due to the dynamical nature of the underlying event generation process. The ability to detect and track such the changing sets of frequent episodes can be valuable in many application scenarios. Current methods for frequent episode discovery are typically multipass algorithms, making them unsuitable in the streaming context. In this paper, we propose a new streaming algorithm for discovering frequent episodes over a window of recent events in the stream. Our algorithm processes events as they arrive, one batch at a time, while discovering the top frequent episodes over a window consisting of several batches in the immediate past. We derive approximation guarantees for our algorithm under the condition that frequent episodes are approximately well-separated from infrequent ones in every batch of the window. We present extensive experimental evaluations of our algorithm on both real and synthetic data. We also present comparisons with baselines and adaptations of streaming algorithms from itemset mining literature.
A Learning Framework for Self-Tuning Histograms
Dec 02, 2011

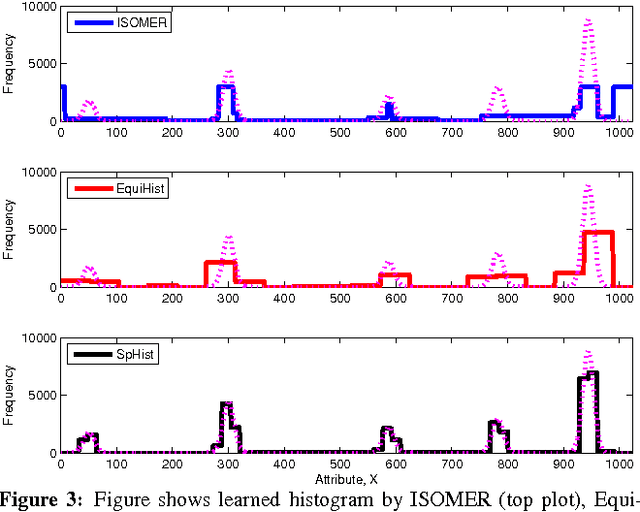
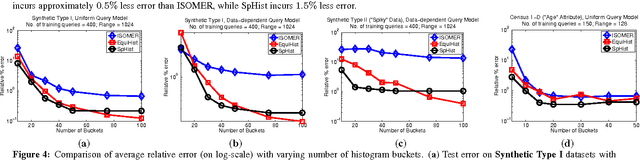
In this paper, we consider the problem of estimating self-tuning histograms using query workloads. To this end, we propose a general learning theoretic formulation. Specifically, we use query feedback from a workload as training data to estimate a histogram with a small memory footprint that minimizes the expected error on future queries. Our formulation provides a framework in which different approaches can be studied and developed. We first study the simple class of equi-width histograms and present a learning algorithm, EquiHist, that is competitive in many settings. We also provide formal guarantees for equi-width histograms that highlight scenarios in which equi-width histograms can be expected to succeed or fail. We then go beyond equi-width histograms and present a novel learning algorithm, SpHist, for estimating general histograms. Here we use Haar wavelets to reduce the problem of learning histograms to that of learning a sparse vector. Both algorithms have multiple advantages over existing methods: 1) simple and scalable extensions to multi-dimensional data, 2) scalability with number of histogram buckets and size of query feedback, 3) natural extensions to incorporate new feedback and handle database updates. We demonstrate these advantages over the current state-of-the-art, ISOMER, through detailed experiments on real and synthetic data. In particular, we show that SpHist obtains up to 50% less error than ISOMER on real-world multi-dimensional datasets.
Lexical Co-occurrence, Statistical Significance, and Word Association
Aug 31, 2010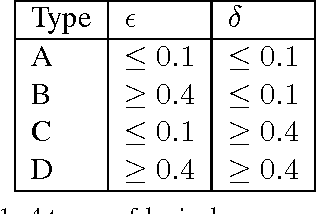
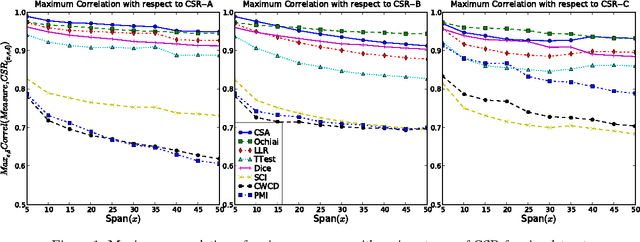

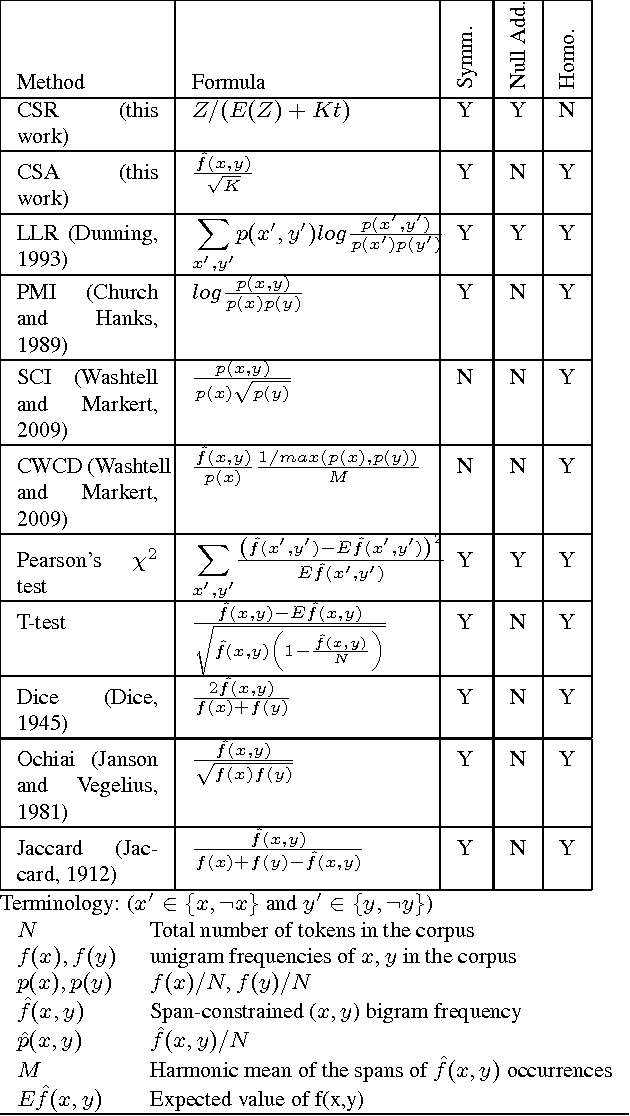
Lexical co-occurrence is an important cue for detecting word associations. We present a theoretical framework for discovering statistically significant lexical co-occurrences from a given corpus. In contrast with the prevalent practice of giving weightage to unigram frequencies, we focus only on the documents containing both the terms (of a candidate bigram). We detect biases in span distributions of associated words, while being agnostic to variations in global unigram frequencies. Our framework has the fidelity to distinguish different classes of lexical co-occurrences, based on strengths of the document and corpuslevel cues of co-occurrence in the data. We perform extensive experiments on benchmark data sets to study the performance of various co-occurrence measures that are currently known in literature. We find that a relatively obscure measure called Ochiai, and a newly introduced measure CSA capture the notion of lexical co-occurrence best, followed next by LLR, Dice, and TTest, while another popular measure, PMI, suprisingly, performs poorly in the context of lexical co-occurrence.
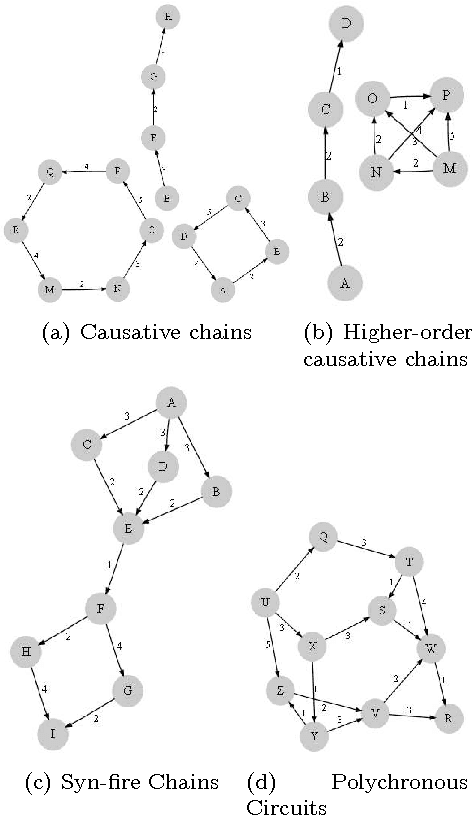
A unified view of Automata-based algorithms for Frequent Episode Discovery
Jul 05, 2010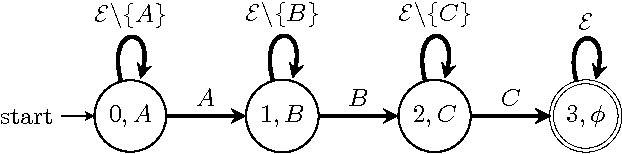
Frequent Episode Discovery framework is a popular framework in Temporal Data Mining with many applications. Over the years many different notions of frequencies of episodes have been proposed along with different algorithms for episode discovery. In this paper we present a unified view of all such frequency counting algorithms. We present a generic algorithm such that all current algorithms are special cases of it. This unified view allows one to gain insights into different frequencies and we present quantitative relationships among different frequencies. Our unified view also helps in obtaining correctness proofs for various algorithms as we show here. We also point out how this unified view helps us to consider generalization of the algorithm so that they can discover episodes with general partial orders.
Discovering general partial orders in event streams
Dec 11, 2009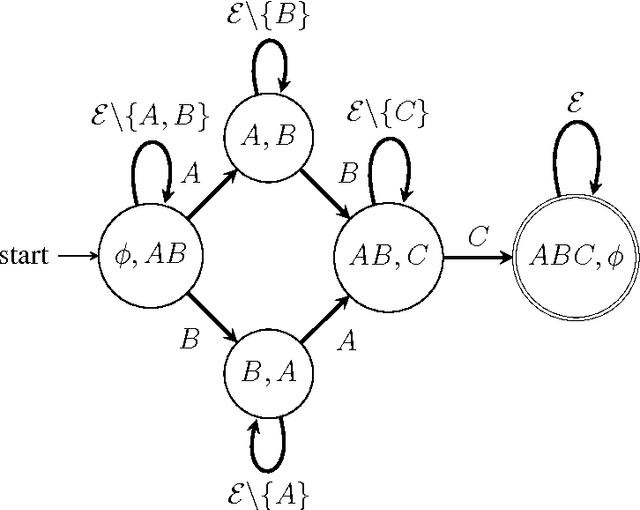
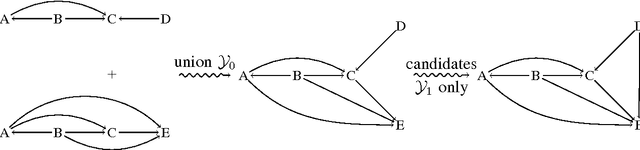
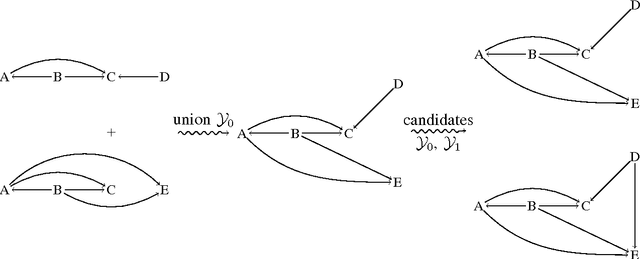
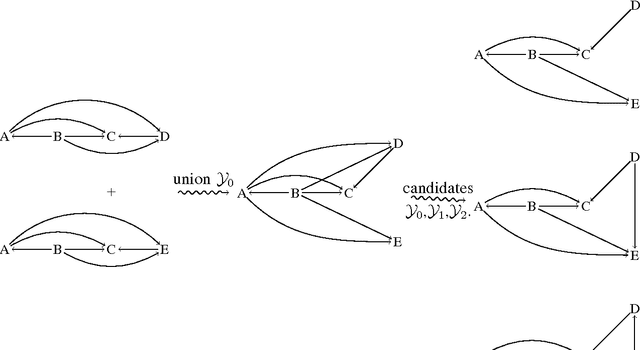
Frequent episode discovery is a popular framework for pattern discovery in event streams. An episode is a partially ordered set of nodes with each node associated with an event type. Efficient (and separate) algorithms exist for episode discovery when the associated partial order is total (serial episode) and trivial (parallel episode). In this paper, we propose efficient algorithms for discovering frequent episodes with general partial orders. These algorithms can be easily specialized to discover serial or parallel episodes. Also, the algorithms are flexible enough to be specialized for mining in the space of certain interesting subclasses of partial orders. We point out that there is an inherent combinatorial explosion in frequent partial order mining and most importantly, frequency alone is not a sufficient measure of interestingness. We propose a new interestingness measure for general partial order episodes and a discovery method based on this measure, for filtering out uninteresting partial orders. Simulations demonstrate the effectiveness of our algorithms.
Temporal data mining for root-cause analysis of machine faults in automotive assembly lines
Apr 30, 2009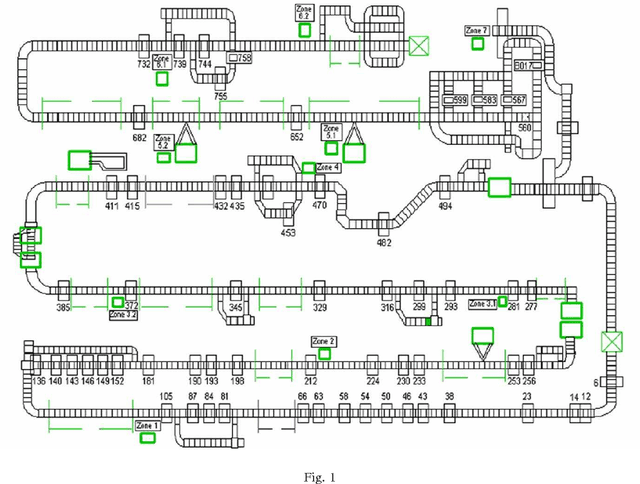

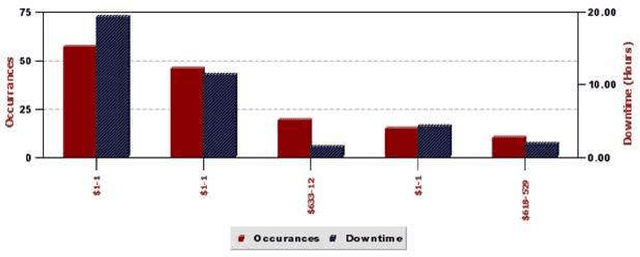
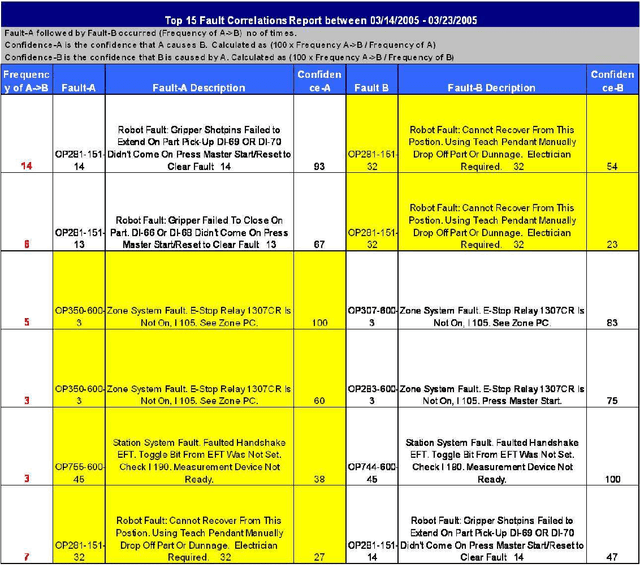
Engine assembly is a complex and heavily automated distributed-control process, with large amounts of faults data logged everyday. We describe an application of temporal data mining for analyzing fault logs in an engine assembly plant. Frequent episode discovery framework is a model-free method that can be used to deduce (temporal) correlations among events from the logs in an efficient manner. In addition to being theoretically elegant and computationally efficient, frequent episodes are also easy to interpret in the form actionable recommendations. Incorporation of domain-specific information is critical to successful application of the method for analyzing fault logs in the manufacturing domain. We show how domain-specific knowledge can be incorporated using heuristic rules that act as pre-filters and post-filters to frequent episode discovery. The system described here is currently being used in one of the engine assembly plants of General Motors and is planned for adaptation in other plants. To the best of our knowledge, this paper presents the first real, large-scale application of temporal data mining in the manufacturing domain. We believe that the ideas presented in this paper can help practitioners engineer tools for analysis in other similar or related application domains as well.
Inferring Dynamic Bayesian Networks using Frequent Episode Mining
Apr 14, 2009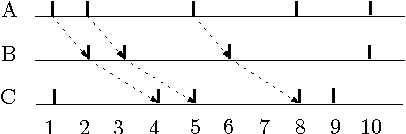
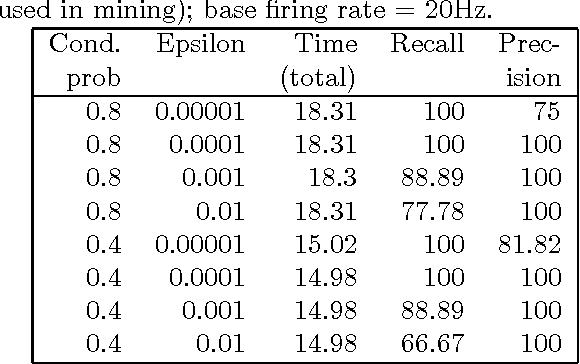
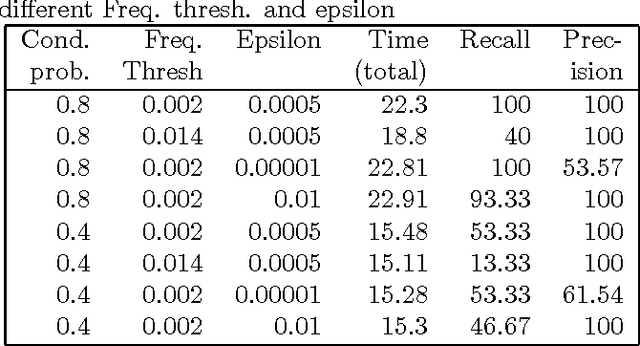
Motivation: Several different threads of research have been proposed for modeling and mining temporal data. On the one hand, approaches such as dynamic Bayesian networks (DBNs) provide a formal probabilistic basis to model relationships between time-indexed random variables but these models are intractable to learn in the general case. On the other, algorithms such as frequent episode mining are scalable to large datasets but do not exhibit the rigorous probabilistic interpretations that are the mainstay of the graphical models literature. Results: We present a unification of these two seemingly diverse threads of research, by demonstrating how dynamic (discrete) Bayesian networks can be inferred from the results of frequent episode mining. This helps bridge the modeling emphasis of the former with the counting emphasis of the latter. First, we show how, under reasonable assumptions on data characteristics and on influences of random variables, the optimal DBN structure can be computed using a greedy, local, algorithm. Next, we connect the optimality of the DBN structure with the notion of fixed-delay episodes and their counts of distinct occurrences. Finally, to demonstrate the practical feasibility of our approach, we focus on a specific (but broadly applicable) class of networks, called excitatory networks, and show how the search for the optimal DBN structure can be conducted using just information from frequent episodes. Application on datasets gathered from mathematical models of spiking neurons as well as real neuroscience datasets are presented. Availability: Algorithmic implementations, simulator codebases, and datasets are available from our website at http://neural-code.cs.vt.edu/dbn