 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pointwise Mutual Information (PMI) by Incorporating Significant Co-occurrence
Jul 02, 2013

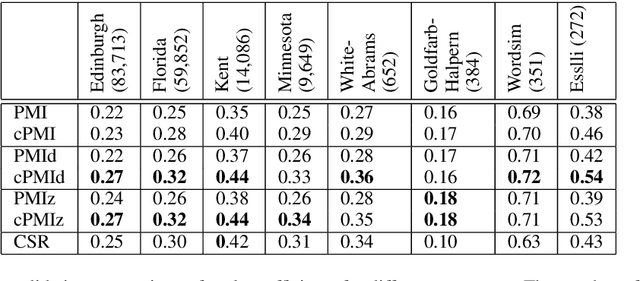

We design a new co-occurrence based word association measure by incorporating the concept of significant cooccurrence in the popular word association measure Pointwise Mutual Information (PMI). By extensive experiments with a large number of publicly available datasets we show that the newly introduced measure performs better than other co-occurrence based measures and despite being resource-light, compares well with the best known resource-heavy distributional similarity and knowledge based word association measures. We investigate the source of this performance improvement and find that of the two types of significant co-occurrence - corpus-level and document-level, the concept of corpus level significance combined with the use of document counts in place of word counts is responsible for all the performance gains observed. The concept of document level significance is not helpful for PMI adaptation.
Lexical Co-occurrence, Statistical Significance, and Word Association
Aug 31, 2010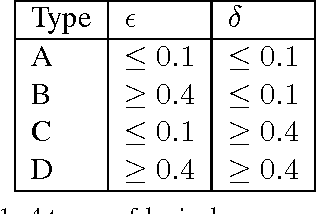
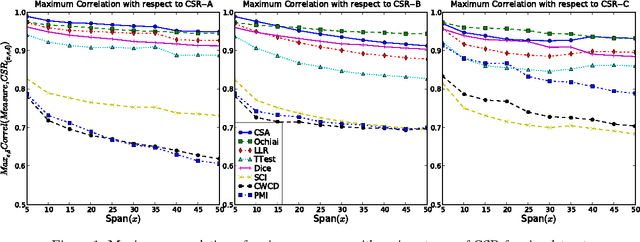

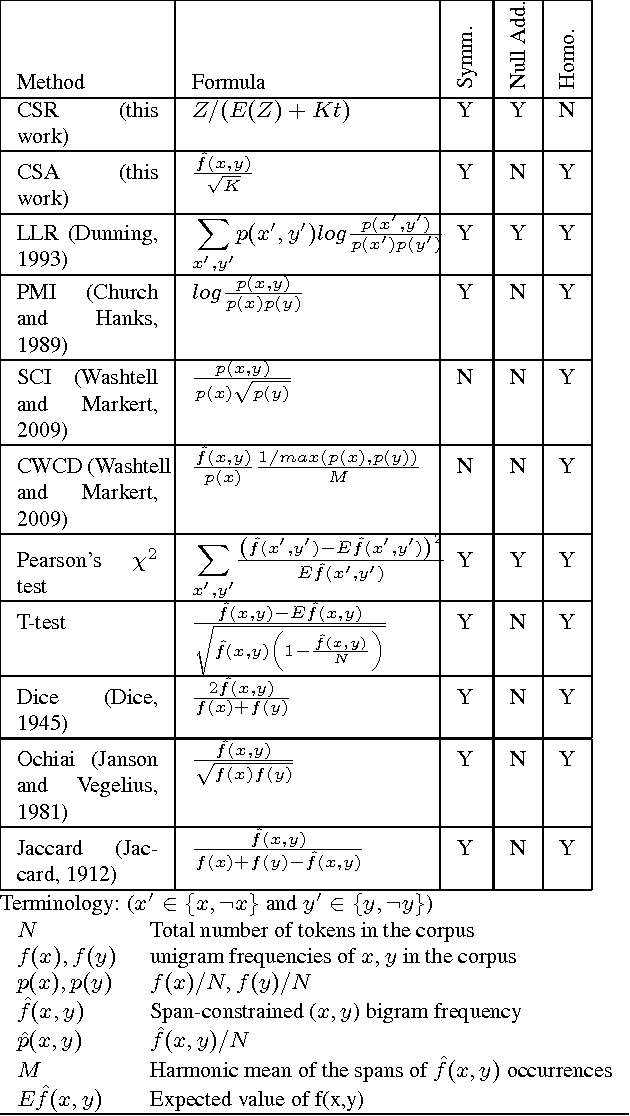
Lexical co-occurrence is an important cue for detecting word associations. We present a theoretical framework for discovering statistically significant lexical co-occurrences from a given corpus. In contrast with the prevalent practice of giving weightage to unigram frequencies, we focus only on the documents containing both the terms (of a candidate bigram). We detect biases in span distributions of associated words, while being agnostic to variations in global unigram frequencies. Our framework has the fidelity to distinguish different classes of lexical co-occurrences, based on strengths of the document and corpuslevel cues of co-occurrence in the data. We perform extensive experiments on benchmark data sets to study the performance of various co-occurrence measures that are currently known in literature. We find that a relatively obscure measure called Ochiai, and a newly introduced measure CSA capture the notion of lexical co-occurrence best, followed next by LLR, Dice, and TTest, while another popular measure, PMI, suprisingly, performs poorly in the context of lexical co-occurrence.