 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Program Generation Modulo Static Analysis
Nov 22, 2021
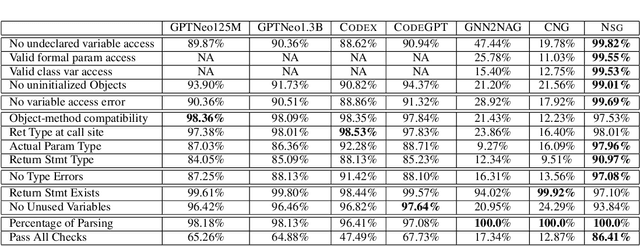
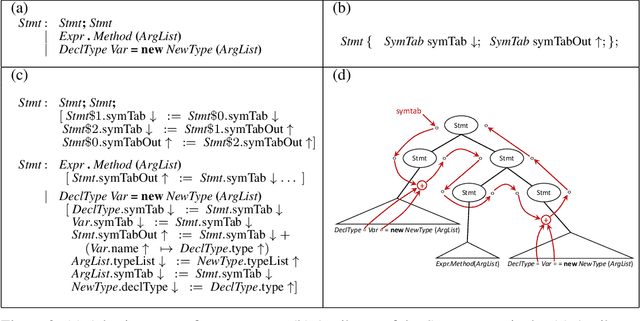

State-of-the-art neural models of source code tend to be evaluated on the generation of individual expressions and lines of code, and commonly fail on long-horizon tasks such as the generation of entire method bodies. We propose to address this deficiency using weak supervision from a static program analyzer. Our neurosymbolic method allows a deep generative model to symbolically compute, using calls to a static-analysis tool, long-distance semantic relationships in the code that it has already generated. During training, the model observes these relationships and learns to generate programs conditioned on them. We apply our approach to the problem of generating entire Java methods given the remainder of the class that contains the method. Our experiments show that the approach substantially outperforms state-of-the-art transformers and a model that explicitly tries to learn program semantics on this task, both in terms of producing programs free of basic semantic errors and in terms of syntactically matching the ground truth.
Meta-Meta-Classification for One-Shot Learning
May 12, 2020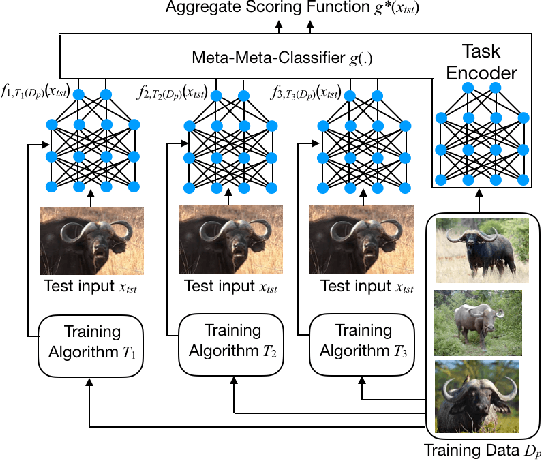
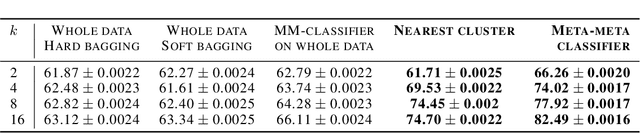
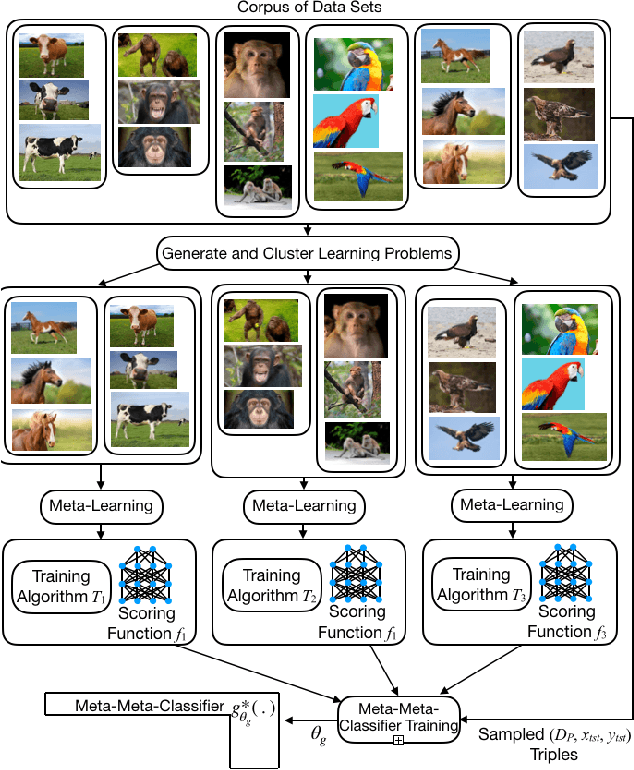

We present a new approach, called meta-meta-classification, to learning in small-data settings. In this approach, one uses a large set of learning problems to design an ensemble of learners, where each learner has high bias and low variance and is skilled at solving a specific type of learning problem. The meta-meta classifier learns how to examine a given learning problem and combine the various learners to solve the problem. The meta-meta-learning approach is especially suited to solving few-shot learning tasks, as it is easier to learn to classify a new learning problem with little data than it is to apply a learning algorithm to a small data set. We evaluate the approach on a one-shot, one-class-versus-all classification task and show that it is able to outperform traditional meta-learning as well as ensembling approaches.
HOUDINI: Lifelong Learning as Program Synthesis
Oct 28, 2018
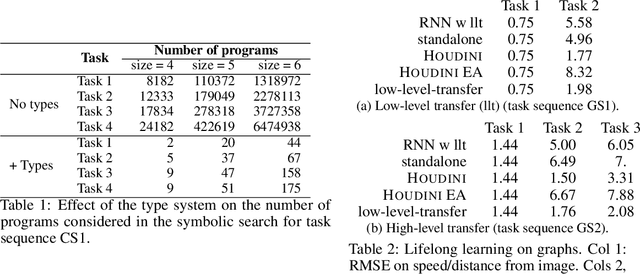

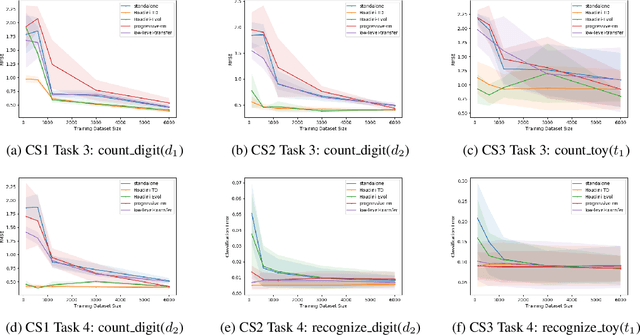
We present a neurosymbolic framework for the lifelong learning of algorithmic tasks that mix perception and procedural reasoning. Reusing high-level concepts across domains and learning complex procedures are key challenges in lifelong learning. We show that a program synthesis approach that combines gradient descent with combinatorial search over programs can be a more effective response to these challenges than purely neural methods. Our framework, called HOUDINI, represents neural networks as strongly typed, differentiable functional programs that use symbolic higher-order combinators to compose a library of neural functions. Our learning algorithm consists of: (1) a symbolic program synthesizer that performs a type-directed search over parameterized programs, and decides on the library functions to reuse, and the architectures to combine them, while learning a sequence of tasks; and (2) a neural module that trains these programs using stochastic gradient descent. We evaluate HOUDINI on three benchmarks that combine perception with the algorithmic tasks of counting, summing, and shortest-path computation. Our experiments show that HOUDINI transfers high-level concepts more effectively than traditional transfer learning and progressive neural networks, and that the typed representation of networks significantly accelerates the search.
Lexical Co-occurrence, Statistical Significance, and Word Association
Aug 31, 2010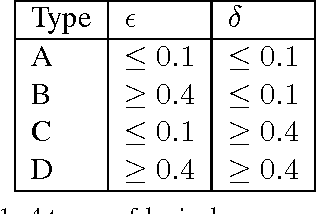
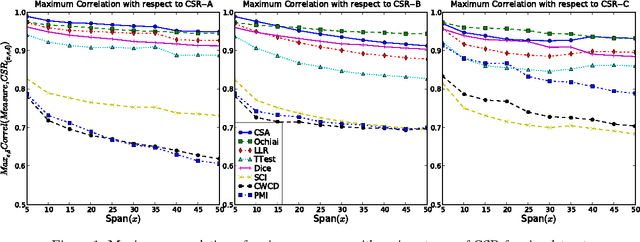

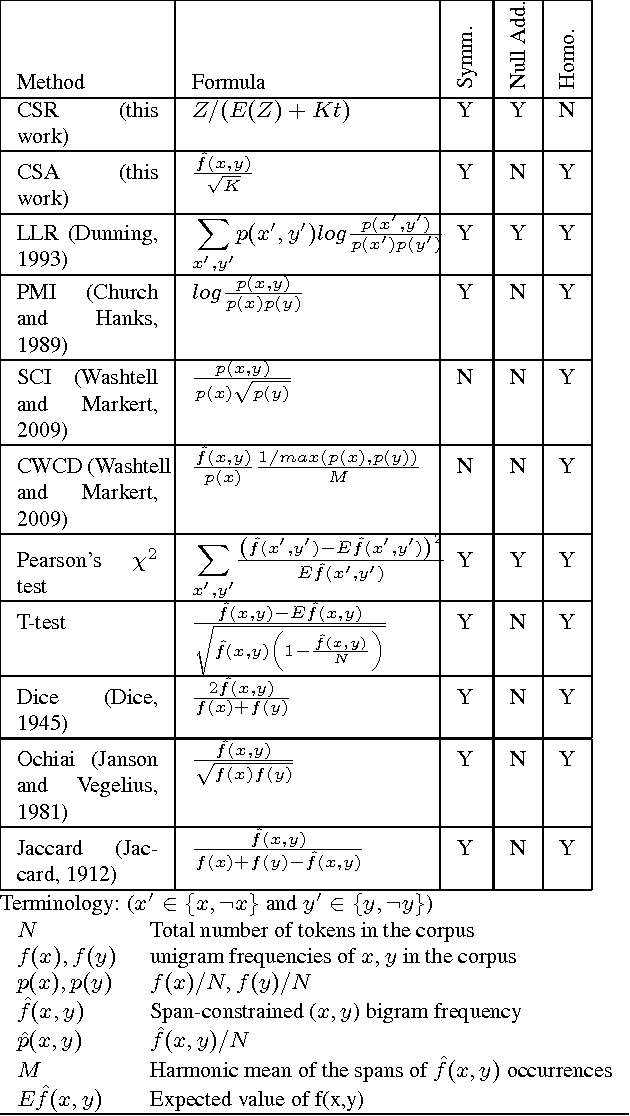
Lexical co-occurrence is an important cue for detecting word associations. We present a theoretical framework for discovering statistically significant lexical co-occurrences from a given corpus. In contrast with the prevalent practice of giving weightage to unigram frequencies, we focus only on the documents containing both the terms (of a candidate bigram). We detect biases in span distributions of associated words, while being agnostic to variations in global unigram frequencies. Our framework has the fidelity to distinguish different classes of lexical co-occurrences, based on strengths of the document and corpuslevel cues of co-occurrence in the data. We perform extensive experiments on benchmark data sets to study the performance of various co-occurrence measures that are currently known in literature. We find that a relatively obscure measure called Ochiai, and a newly introduced measure CSA capture the notion of lexical co-occurrence best, followed next by LLR, Dice, and TTest, while another popular measure, PMI, suprisingly, performs poorly in the context of lexical co-occurrence.