 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQonvolution: Towards Learning High-Frequency Signals with Queried Convolution
Dec 15, 2025Accurately learning high-frequency signals is a challenge in computer vision and graphics, as neural networks often struggle with these signals due to spectral bias or optimization difficulties. While current techniques like Fourier encodings have made great strides in improving performance, there remains scope for improvement when presented with high-frequency information. This paper introduces Queried-Convolutions (Qonvolutions), a simple yet powerful modification using the neighborhood properties of convolution. Qonvolution convolves a low-frequency signal with queries (such as coordinates) to enhance the learning of intricate high-frequency signals. We empirically demonstrate that Qonvolutions enhance performance across a variety of high-frequency learning tasks crucial to both the computer vision and graphics communities, including 1D regression, 2D super-resolution, 2D image regression, and novel view synthesis (NVS). In particular, by combining Gaussian splatting with Qonvolutions for NVS, we showcase state-of-the-art performance on real-world complex scenes, even outperforming powerful radiance field models on image quality.
Adaptive Memory Replay for Continual Learning
Apr 18, 2024Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
A Probabilistic Framework for Modular Continual Learning
Jun 11, 2023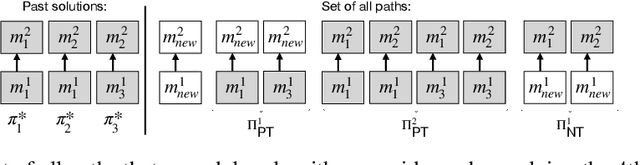
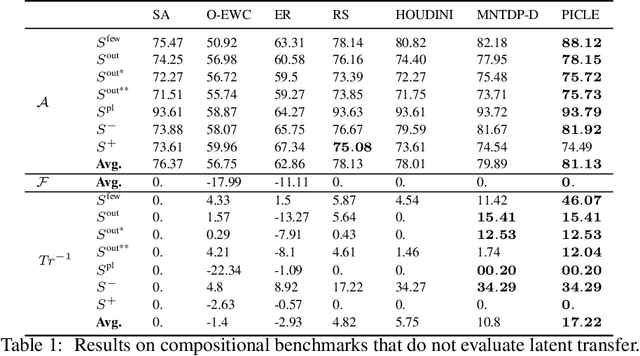

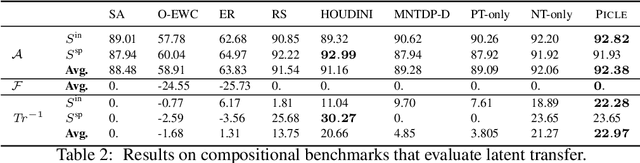
Modular approaches, which use a different composition of modules for each problem and avoid forgetting by design, have been shown to be a promising direction in continual learning (CL). However, searching through the large, discrete space of possible module compositions is a challenge because evaluating a composition's performance requires a round of neural network training. To address this challenge, we develop a modular CL framework, called PICLE, that accelerates search by using a probabilistic model to cheaply compute the fitness of each composition. The model combines prior knowledge about good module compositions with dataset-specific information. Its use is complemented by splitting up the search space into subsets, such as perceptual and latent subsets. We show that PICLE is the first modular CL algorithm to achieve different types of transfer while scaling to large search spaces. We evaluate it on two benchmark suites designed to capture different desiderata of CL techniques. On these benchmarks, PICLE offers significantly better performance than state-of-the-art CL baselines.
HOUDINI: Lifelong Learning as Program Synthesis
Oct 28, 2018
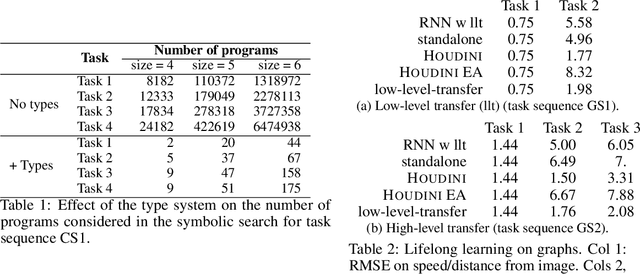

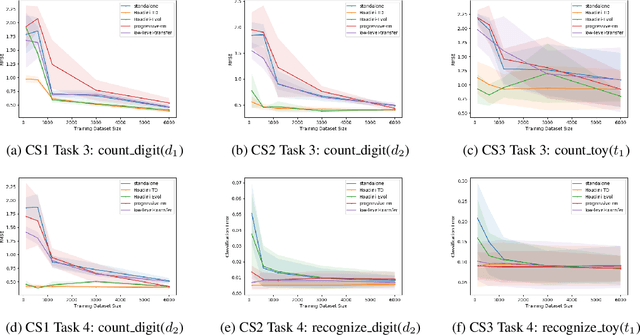
We present a neurosymbolic framework for the lifelong learning of algorithmic tasks that mix perception and procedural reasoning. Reusing high-level concepts across domains and learning complex procedures are key challenges in lifelong learning. We show that a program synthesis approach that combines gradient descent with combinatorial search over programs can be a more effective response to these challenges than purely neural methods. Our framework, called HOUDINI, represents neural networks as strongly typed, differentiable functional programs that use symbolic higher-order combinators to compose a library of neural functions. Our learning algorithm consists of: (1) a symbolic program synthesizer that performs a type-directed search over parameterized programs, and decides on the library functions to reuse, and the architectures to combine them, while learning a sequence of tasks; and (2) a neural module that trains these programs using stochastic gradient descent. We evaluate HOUDINI on three benchmarks that combine perception with the algorithmic tasks of counting, summing, and shortest-path computation. Our experiments show that HOUDINI transfers high-level concepts more effectively than traditional transfer learning and progressive neural networks, and that the typed representation of networks significantly accelerates the search.
VEEGAN: Reducing Mode Collapse in GANs using Implicit Variational Learning
Nov 06, 2017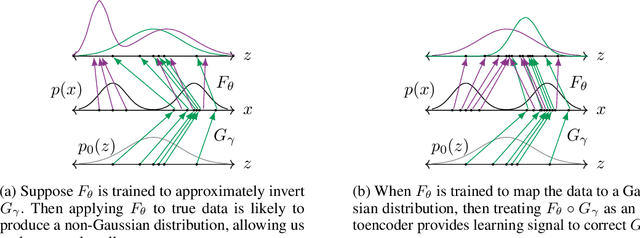
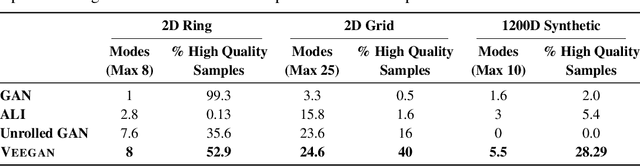

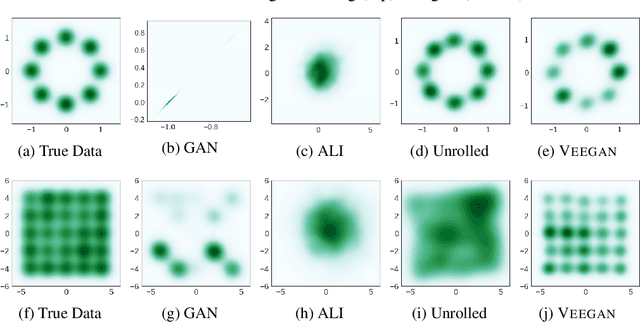
Deep generative models provide powerful tools for distributions over complicated manifolds, such as those of natural images. But many of these methods, including generative adversarial networks (GANs), can be difficult to train, in part because they are prone to mode collapse, which means that they characterize only a few modes of the true distribution. To address this, we introduce VEEGAN, which features a reconstructor network, reversing the action of the generator by mapping from data to noise. Our training objective retains the original asymptotic consistency guarantee of GANs, and can be interpreted as a novel autoencoder loss over the noise. In sharp contrast to a traditional autoencoder over data points, VEEGAN does not require specifying a loss function over the data, but rather only over the representations, which are standard normal by assumption. On an extensive set of synthetic and real world image datasets, VEEGAN indeed resists mode collapsing to a far greater extent than other recent GAN variants, and produces more realistic samples.