 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Inference in Capsule Networks Using Accumulated Routing Coefficients
Apr 15, 2019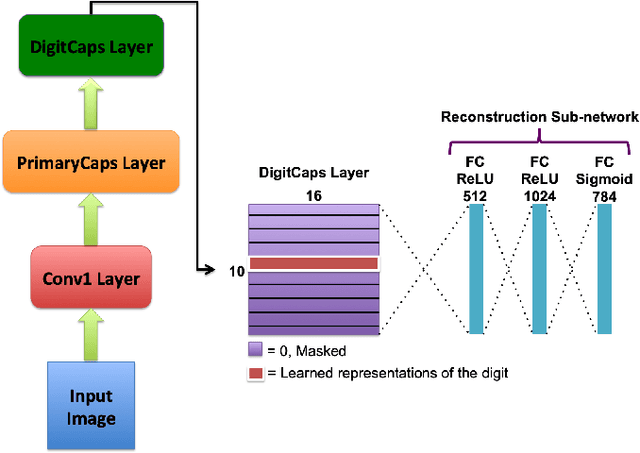

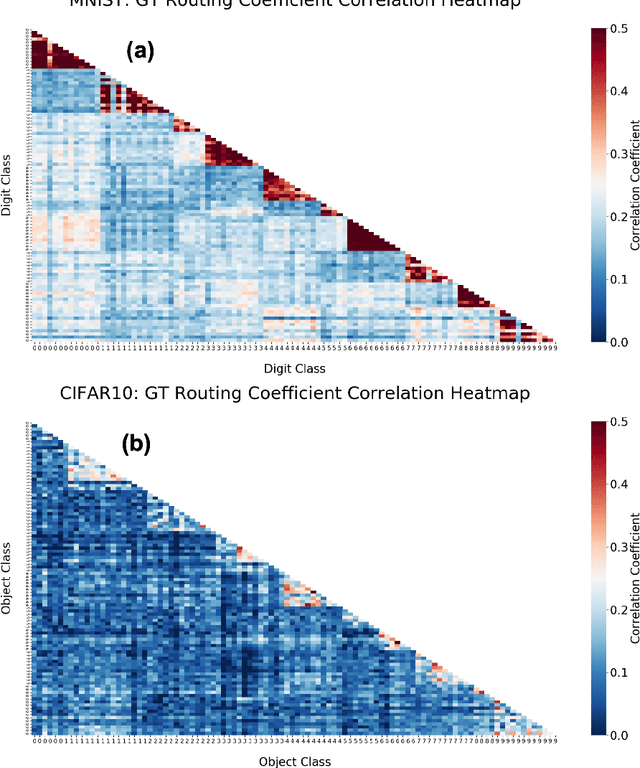
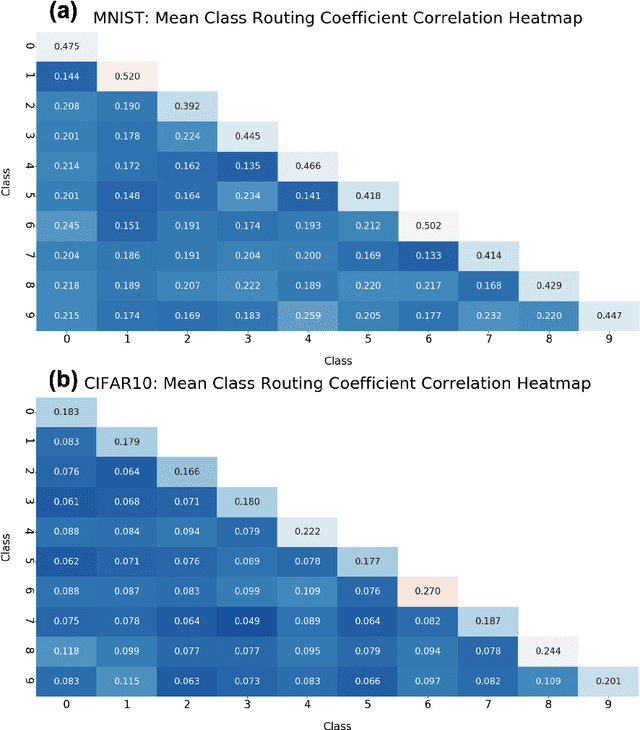
We present a method for fast inference in Capsule Networks (CapsNets) by taking advantage of a key insight regarding the routing coefficients that link capsules between adjacent network layers. Since the routing coefficients are responsible for assigning object parts to wholes, and an object whole generally contains similar intra-class and dissimilar inter-class parts, the routing coefficients tend to form a unique signature for each object class. For fast inference, a network is first trained in the usual manner using examples from the training dataset. Afterward, the routing coefficients associated with the training examples are accumulated offline and used to create a set of "master" routing coefficients. During inference, these master routing coefficients are used in place of the dynamically calculated routing coefficients. Our method effectively replaces the for-loop iterations in the dynamic routing procedure with a single matrix multiply operation, providing a significant boost in inference speed. Compared with the dynamic routing procedure, fast inference decreases the test accuracy for the MNIST, Background MNIST, Fashion MNIST, and Rotated MNIST datasets by less than 0.5% and by approximately 5% for CIFAR10.
Capsule Networks with Max-Min Normalization
Mar 22, 2019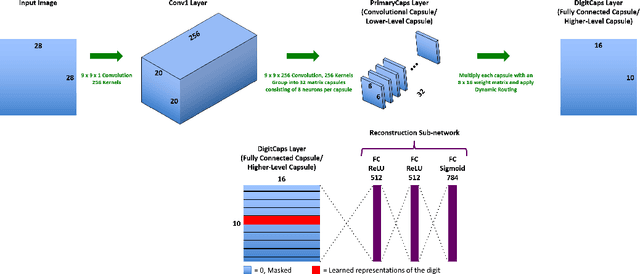
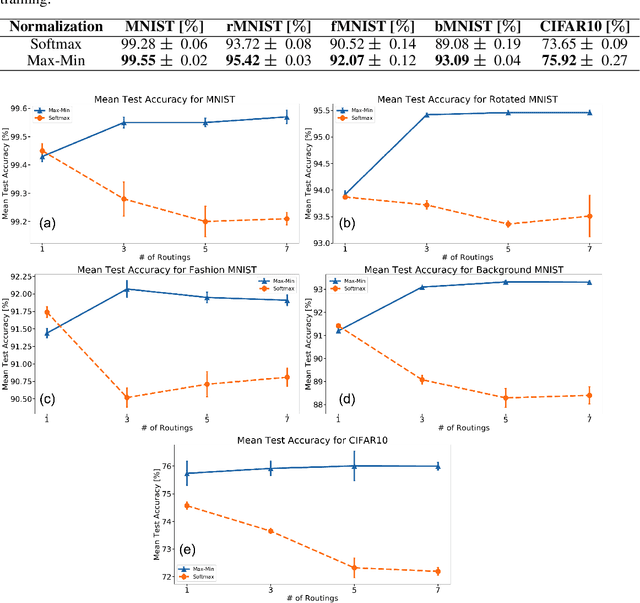
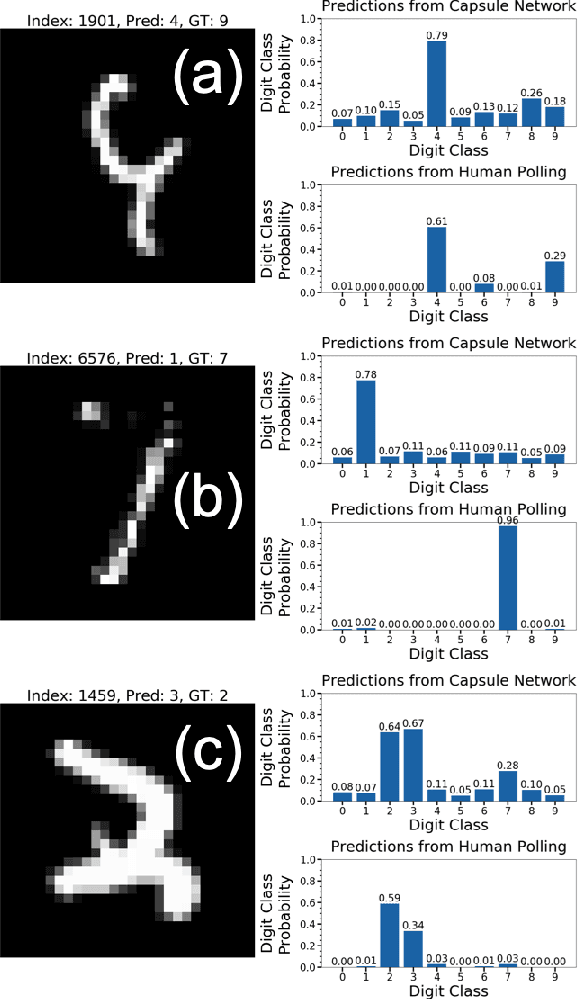
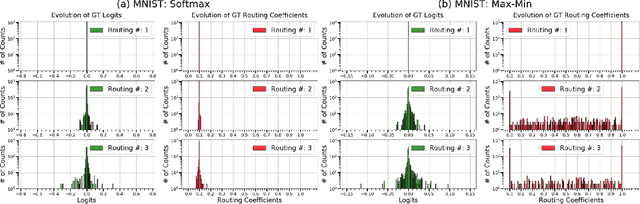
Capsule Networks (CapsNet) use the Softmax function to convert the logits of the routing coefficients into a set of normalized values that signify the assignment probabilities between capsules in adjacent layers. We show that the use of Softmax prevents capsule layers from forming optimal couplings between lower and higher-level capsules. Softmax constrains the dynamic range of the routing coefficients and leads to probabilities that remain mostly uniform after several routing iterations. Instead, we propose the use of Max-Min normalization. Max-Min performs a scale-invariant normalization of the logits that allows each lower-level capsule to take on an independent value, constrained only by the bounds of normalization. Max-Min provides consistent improvement in test accuracy across five datasets and allows more routing iterations without a decrease in network performance. A single CapsNet trained using Max-Min achieves an improved test error of 0.20% on the MNIST dataset. With a simple 3-model majority vote, we achieve a test error of 0.17% on MNIST.
Efficient Discovery of Large Synchronous Events in Neural Spike Streams
Jun 08, 2010



We address the problem of finding patterns from multi-neuronal spike trains that give us insights into the multi-neuronal codes used in the brain and help us design better brain computer interfaces. We focus on the synchronous firings of groups of neurons as these have been shown to play a major role in coding and communication. With large electrode arrays, it is now possible to simultaneously record the spiking activity of hundreds of neurons over large periods of time. Recently, techniques have been developed to efficiently count the frequency of synchronous firing patterns. However, when the number of neurons being observed grows they suffer from the combinatorial explosion in the number of possible patterns and do not scale well. In this paper, we present a temporal data mining scheme that overcomes many of these problems. It generates a set of candidate patterns from frequent patterns of smaller size; all possible patterns are not counted. Also we count only a certain well defined subset of occurrences and this makes the process more efficient. We highlight the computational advantage that this approach offers over the existing methods through simulations. We also propose methods for assessing the statistical significance of the discovered patterns. We detect only those patterns that repeat often enough to be significant and thus be able to automatically fix the threshold for the data-mining application. Finally we discuss the usefulness of these methods for brain computer interfaces.
Temporal data mining for root-cause analysis of machine faults in automotive assembly lines
Apr 30, 2009

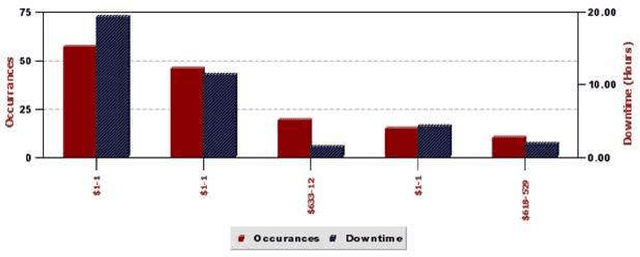
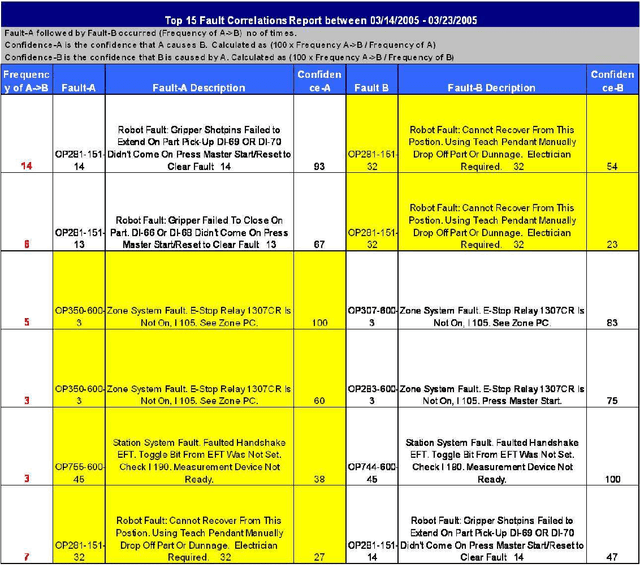
Engine assembly is a complex and heavily automated distributed-control process, with large amounts of faults data logged everyday. We describe an application of temporal data mining for analyzing fault logs in an engine assembly plant. Frequent episode discovery framework is a model-free method that can be used to deduce (temporal) correlations among events from the logs in an efficient manner. In addition to being theoretically elegant and computationally efficient, frequent episodes are also easy to interpret in the form actionable recommendations. Incorporation of domain-specific information is critical to successful application of the method for analyzing fault logs in the manufacturing domain. We show how domain-specific knowledge can be incorporated using heuristic rules that act as pre-filters and post-filters to frequent episode discovery. The system described here is currently being used in one of the engine assembly plants of General Motors and is planned for adaptation in other plants. To the best of our knowledge, this paper presents the first real, large-scale application of temporal data mining in the manufacturing domain. We believe that the ideas presented in this paper can help practitioners engineer tools for analysis in other similar or related application domains as well.