 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Inference in Capsule Networks Using Accumulated Routing Coefficients
Apr 15, 2019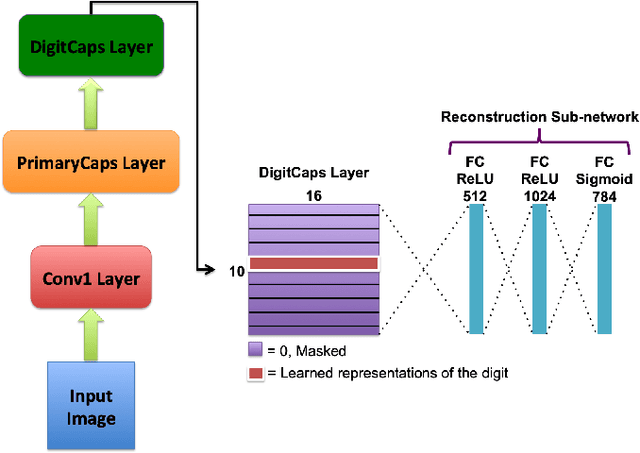

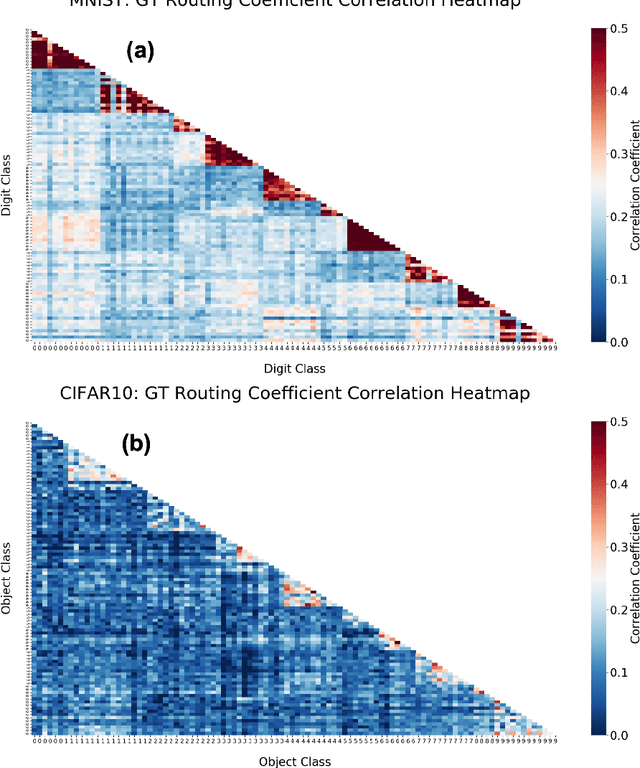
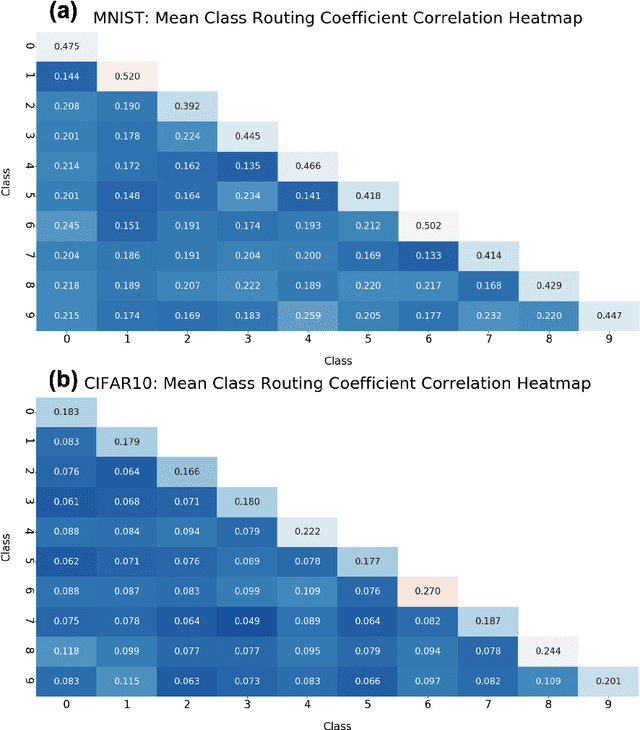
We present a method for fast inference in Capsule Networks (CapsNets) by taking advantage of a key insight regarding the routing coefficients that link capsules between adjacent network layers. Since the routing coefficients are responsible for assigning object parts to wholes, and an object whole generally contains similar intra-class and dissimilar inter-class parts, the routing coefficients tend to form a unique signature for each object class. For fast inference, a network is first trained in the usual manner using examples from the training dataset. Afterward, the routing coefficients associated with the training examples are accumulated offline and used to create a set of "master" routing coefficients. During inference, these master routing coefficients are used in place of the dynamically calculated routing coefficients. Our method effectively replaces the for-loop iterations in the dynamic routing procedure with a single matrix multiply operation, providing a significant boost in inference speed. Compared with the dynamic routing procedure, fast inference decreases the test accuracy for the MNIST, Background MNIST, Fashion MNIST, and Rotated MNIST datasets by less than 0.5% and by approximately 5% for CIFAR10.
Capsule Networks with Max-Min Normalization
Mar 22, 2019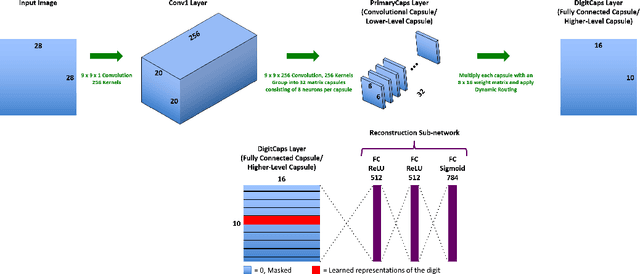
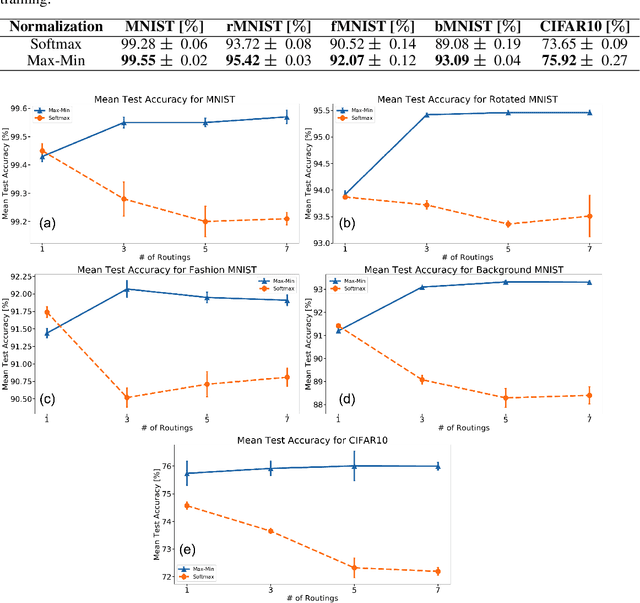
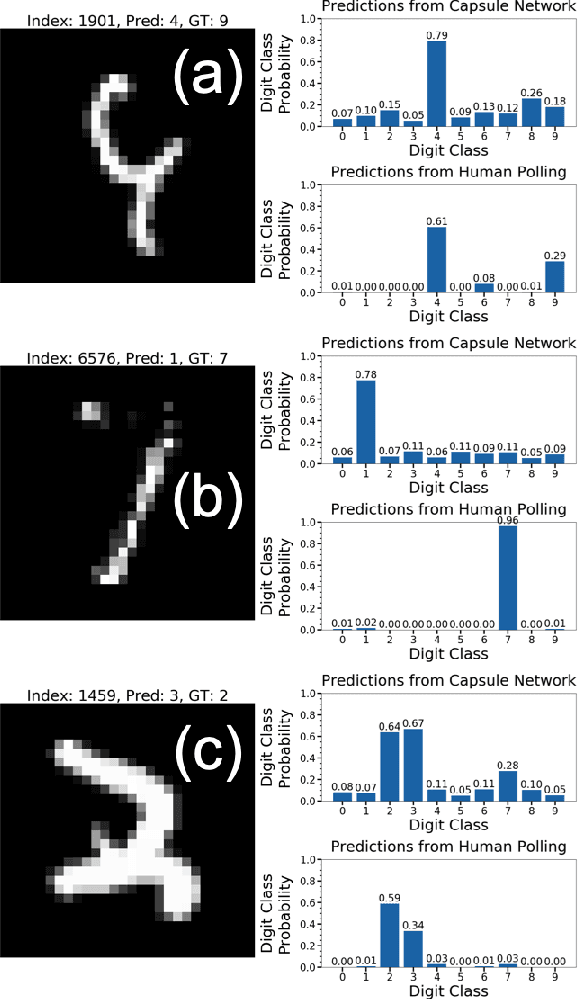
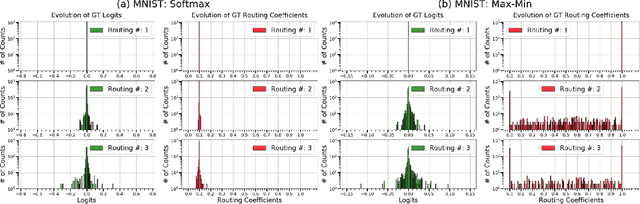
Capsule Networks (CapsNet) use the Softmax function to convert the logits of the routing coefficients into a set of normalized values that signify the assignment probabilities between capsules in adjacent layers. We show that the use of Softmax prevents capsule layers from forming optimal couplings between lower and higher-level capsules. Softmax constrains the dynamic range of the routing coefficients and leads to probabilities that remain mostly uniform after several routing iterations. Instead, we propose the use of Max-Min normalization. Max-Min performs a scale-invariant normalization of the logits that allows each lower-level capsule to take on an independent value, constrained only by the bounds of normalization. Max-Min provides consistent improvement in test accuracy across five datasets and allows more routing iterations without a decrease in network performance. A single CapsNet trained using Max-Min achieves an improved test error of 0.20% on the MNIST dataset. With a simple 3-model majority vote, we achieve a test error of 0.17% on MNIST.