 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning Framework for Self-Tuning Histograms
Paper and Code
Dec 02, 2011

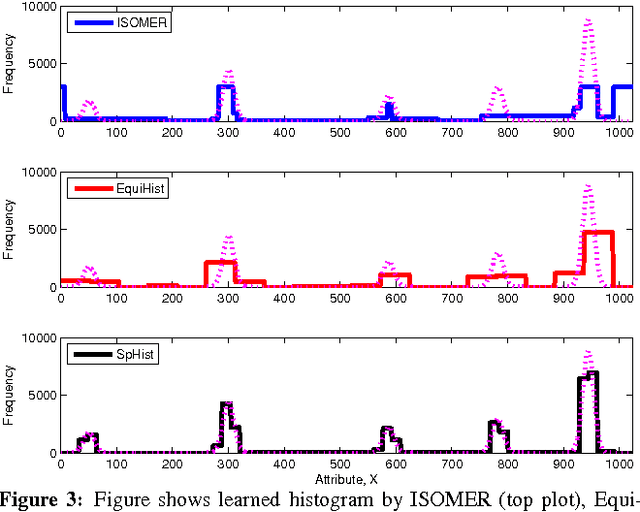
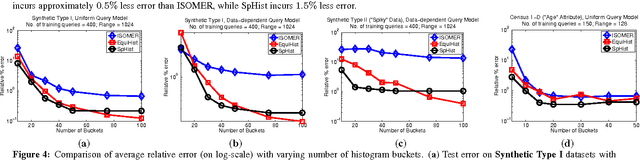
In this paper, we consider the problem of estimating self-tuning histograms using query workloads. To this end, we propose a general learning theoretic formulation. Specifically, we use query feedback from a workload as training data to estimate a histogram with a small memory footprint that minimizes the expected error on future queries. Our formulation provides a framework in which different approaches can be studied and developed. We first study the simple class of equi-width histograms and present a learning algorithm, EquiHist, that is competitive in many settings. We also provide formal guarantees for equi-width histograms that highlight scenarios in which equi-width histograms can be expected to succeed or fail. We then go beyond equi-width histograms and present a novel learning algorithm, SpHist, for estimating general histograms. Here we use Haar wavelets to reduce the problem of learning histograms to that of learning a sparse vector. Both algorithms have multiple advantages over existing methods: 1) simple and scalable extensions to multi-dimensional data, 2) scalability with number of histogram buckets and size of query feedback, 3) natural extensions to incorporate new feedback and handle database updates. We demonstrate these advantages over the current state-of-the-art, ISOMER, through detailed experiments on real and synthetic data. In particular, we show that SpHist obtains up to 50% less error than ISOMER on real-world multi-dimensional datasets.