 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparks of Science: Hypothesis Generation Using Structured Paper Data
Apr 17, 2025



Generating novel and creative scientific hypotheses is a cornerstone in achieving Artificial General Intelligence. Large language and reasoning models have the potential to aid in the systematic creation, selection, and validation of scientifically informed hypotheses. However, current foundation models often struggle to produce scientific ideas that are both novel and feasible. One reason is the lack of a dedicated dataset that frames Scientific Hypothesis Generation (SHG) as a Natural Language Generation (NLG) task. In this paper, we introduce HypoGen, the first dataset of approximately 5500 structured problem-hypothesis pairs extracted from top-tier computer science conferences structured with a Bit-Flip-Spark schema, where the Bit is the conventional assumption, the Spark is the key insight or conceptual leap, and the Flip is the resulting counterproposal. HypoGen uniquely integrates an explicit Chain-of-Reasoning component that reflects the intellectual process from Bit to Flip. We demonstrate that framing hypothesis generation as conditional language modelling, with the model fine-tuned on Bit-Flip-Spark and the Chain-of-Reasoning (and where, at inference, we only provide the Bit), leads to improvements in the overall quality of the hypotheses. Our evaluation employs automated metrics and LLM judge rankings for overall quality assessment. We show that by fine-tuning on our HypoGen dataset we improve the novelty, feasibility, and overall quality of the generated hypotheses. The HypoGen dataset is publicly available at huggingface.co/datasets/UniverseTBD/hypogen-dr1.
A Survey on Hypothesis Generation for Scientific Discovery in the Era of Large Language Models
Apr 07, 2025Hypothesis generation is a fundamental step in scientific discovery, yet it is increasingly challenged by information overload and disciplinary fragmentation. Recent advances in Large Language Models (LLMs) have sparked growing interest in their potential to enhance and automate this process. This paper presents a comprehensive survey of hypothesis generation with LLMs by (i) reviewing existing methods, from simple prompting techniques to more complex frameworks, and proposing a taxonomy that categorizes these approaches; (ii) analyzing techniques for improving hypothesis quality, such as novelty boosting and structured reasoning; (iii) providing an overview of evaluation strategies; and (iv) discussing key challenges and future directions, including multimodal integration and human-AI collaboration. Our survey aims to serve as a reference for researchers exploring LLMs for hypothesis generation.
Automatic Machine Learning Framework to Study Morphological Parameters of AGN Host Galaxies within $z < 1.4$ in the Hyper Supreme-Cam Wide Survey
Jan 27, 2025We present a composite machine learning framework to estimate posterior probability distributions of bulge-to-total light ratio, half-light radius, and flux for Active Galactic Nucleus (AGN) host galaxies within $z<1.4$ and $m<23$ in the Hyper Supreme-Cam Wide survey. We divide the data into five redshift bins: low ($0<z<0.25$), mid ($0.25<z<0.5$), high ($0.5<z<0.9$), extra ($0.9<z<1.1$) and extreme ($1.1<z<1.4$), and train our models independently in each bin. We use PSFGAN to decompose the AGN point source light from its host galaxy, and invoke the Galaxy Morphology Posterior Estimation Network (GaMPEN) to estimate morphological parameters of the recovered host galaxy. We first trained our models on simulated data, and then fine-tuned our algorithm via transfer learning using labeled real data. To create training labels for transfer learning, we used GALFIT to fit $\sim 20,000$ real HSC galaxies in each redshift bin. We comprehensively examined that the predicted values from our final models agree well with the GALFIT values for the vast majority of cases. Our PSFGAN + GaMPEN framework runs at least three orders of magnitude faster than traditional light-profile fitting methods, and can be easily retrained for other morphological parameters or on other datasets with diverse ranges of resolutions, seeing conditions, and signal-to-noise ratios, making it an ideal tool for analyzing AGN host galaxies from large surveys coming soon from the Rubin-LSST, Euclid, and Roman telescopes.
pathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.
AstroLLaMA-Chat: Scaling AstroLLaMA with Conversational and Diverse Datasets
Jan 05, 2024We explore the potential of enhancing LLM performance in astronomy-focused question-answering through targeted, continual pre-training. By employing a compact 7B-parameter LLaMA-2 model and focusing exclusively on a curated set of astronomy corpora -- comprising abstracts, introductions, and conclusions -- we achieve notable improvements in specialized topic comprehension. While general LLMs like GPT-4 excel in broader question-answering scenarios due to superior reasoning capabilities, our findings suggest that continual pre-training with limited resources can still enhance model performance on specialized topics. Additionally, we present an extension of AstroLLaMA: the fine-tuning of the 7B LLaMA model on a domain-specific conversational dataset, culminating in the release of the chat-enabled AstroLLaMA for community use. Comprehensive quantitative benchmarking is currently in progress and will be detailed in an upcoming full paper. The model, AstroLLaMA-Chat, is now available at https://huggingface.co/universeTBD, providing the first open-source conversational AI tool tailored for the astronomy community.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023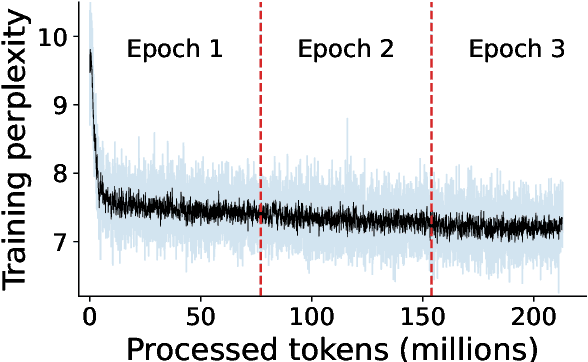

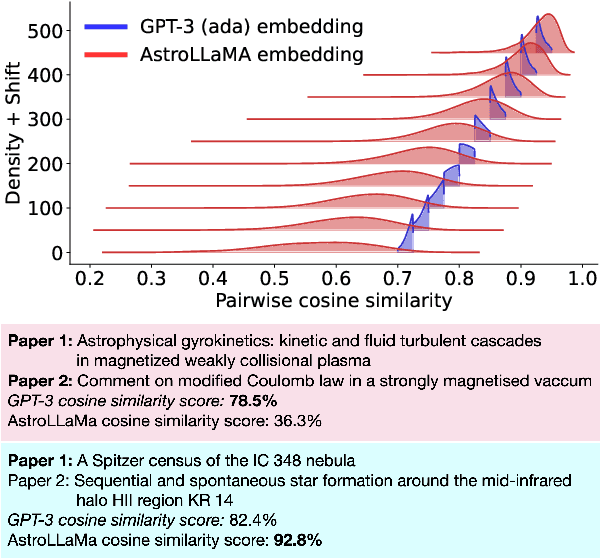
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
Using Machine Learning to Determine Morphologies of $z<1$ AGN Host Galaxies in the Hyper Suprime-Cam Wide Survey
Dec 20, 2022We present a machine-learning framework to accurately characterize morphologies of Active Galactic Nucleus (AGN) host galaxies within $z<1$. We first use PSFGAN to decouple host galaxy light from the central point source, then we invoke the Galaxy Morphology Network (GaMorNet) to estimate whether the host galaxy is disk-dominated, bulge-dominated, or indeterminate. Using optical images from five bands of the HSC Wide Survey, we build models independently in three redshift bins: low $(0<z<0.25)$, medium $(0.25<z<0.5)$, and high $(0.5<z<1.0)$. By first training on a large number of simulated galaxies, then fine-tuning using far fewer classified real galaxies, our framework predicts the actual morphology for $\sim$ $60\%-70\%$ host galaxies from test sets, with a classification precision of $\sim$ $80\%-95\%$, depending on redshift bin. Specifically, our models achieve disk precision of $96\%/82\%/79\%$ and bulge precision of $90\%/90\%/80\%$ (for the 3 redshift bins), at thresholds corresponding to indeterminate fractions of $30\%/43\%/42\%$. The classification precision of our models has a noticeable dependency on host galaxy radius and magnitude. No strong dependency is observed on contrast ratio. Comparing classifications of real AGNs, our models agree well with traditional 2D fitting with GALFIT. The PSFGAN+GaMorNet framework does not depend on the choice of fitting functions or galaxy-related input parameters, runs orders of magnitude faster than GALFIT, and is easily generalizable via transfer learning, making it an ideal tool for studying AGN host galaxy morphology in forthcoming large imaging survey.
Continuous Integration of Machine Learning Models with ease.ml/ci: Towards a Rigorous Yet Practical Treatment
Mar 01, 2019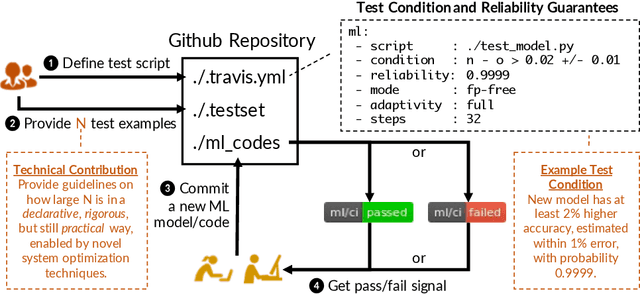
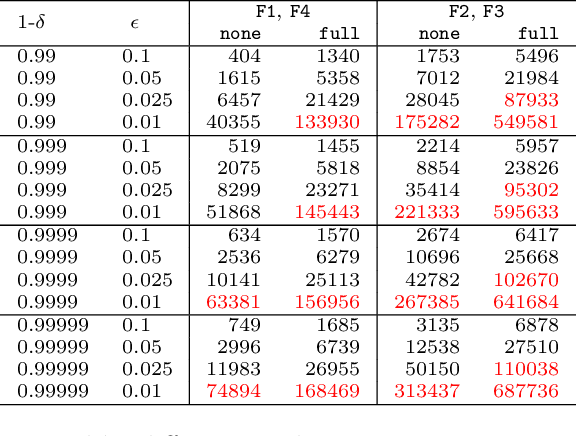
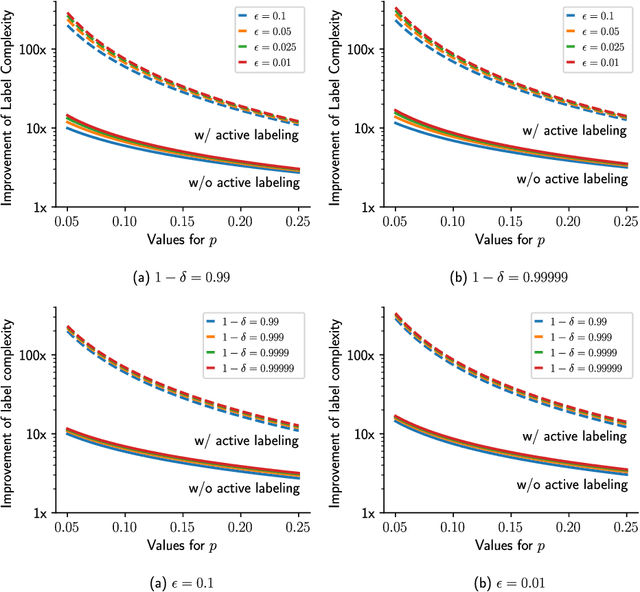
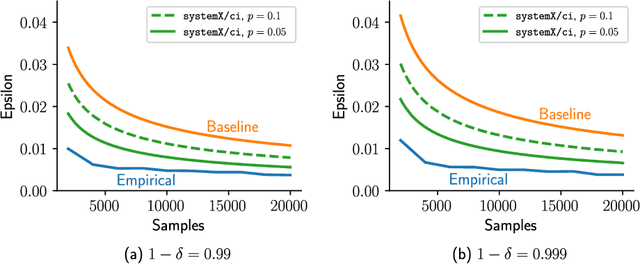
Continuous integration is an indispensable step of modern software engineering practices to systematically manage the life cycles of system development. Developing a machine learning model is no difference - it is an engineering process with a life cycle, including design, implementation, tuning, testing, and deployment. However, most, if not all, existing continuous integration engines do not support machine learning as first-class citizens. In this paper, we present ease.ml/ci, to our best knowledge, the first continuous integration system for machine learning. The challenge of building ease.ml/ci is to provide rigorous guarantees, e.g., single accuracy point error tolerance with 0.999 reliability, with a practical amount of labeling effort, e.g., 2K labels per test. We design a domain specific language that allows users to specify integration conditions with reliability constraints, and develop simple novel optimizations that can lower the number of labels required by up to two orders of magnitude for test conditions popularly used in real production systems.
Exploring galaxy evolution with generative models
Dec 05, 2018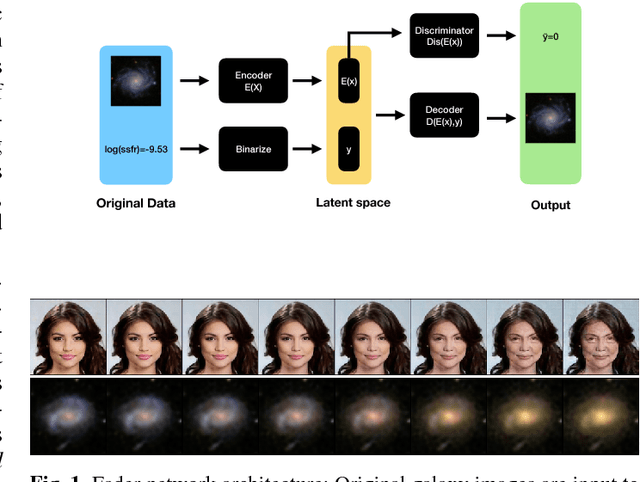
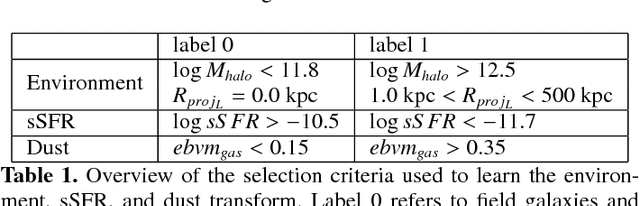
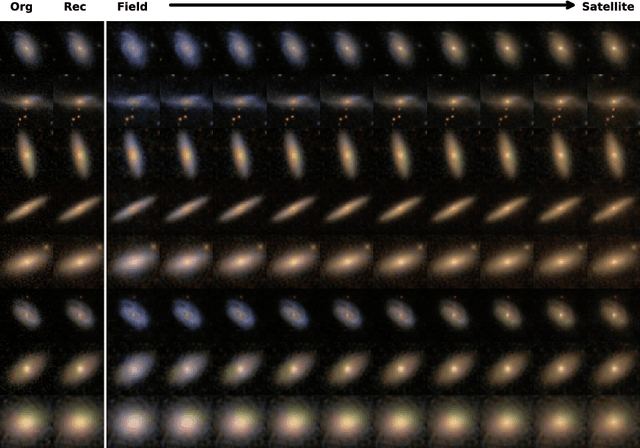
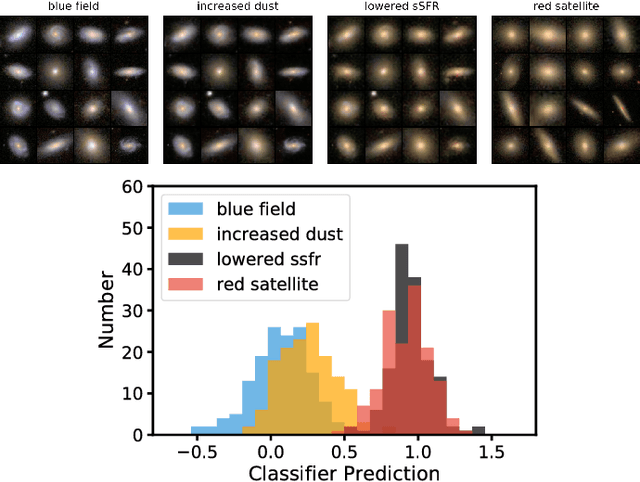
Context. Generative models open up the possibility to interrogate scientific data in a more data-driven way. Aims: We propose a method that uses generative models to explore hypotheses in astrophysics and other areas. We use a neural network to show how we can independently manipulate physical attributes by encoding objects in latent space. Methods: By learning a latent space representation of the data, we can use this network to forward model and explore hypotheses in a data-driven way. We train a neural network to generate artificial data to test hypotheses for the underlying physical processes. Results: We demonstrate this process using a well-studied process in astrophysics, the quenching of star formation in galaxies as they move from low-to high-density environments. This approach can help explore astrophysical and other phenomena in a way that is different from current methods based on simulations and observations.
Using transfer learning to detect galaxy mergers
May 29, 2018
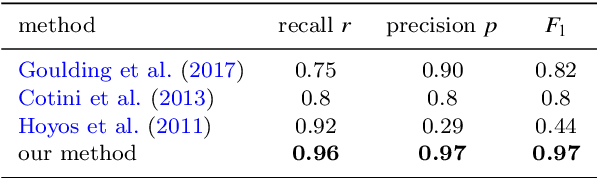
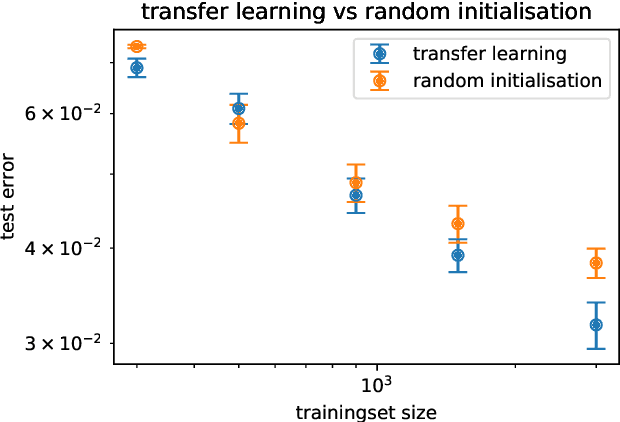
We investigate the use of deep convolutional neural networks (deep CNNs) for automatic visual detection of galaxy mergers. Moreover, we investigate the use of transfer learning in conjunction with CNNs, by retraining networks first trained on pictures of everyday objects. We test the hypothesis that transfer learning is useful for improving classification performance for small training sets. This would make transfer learning useful for finding rare objects in astronomical imaging datasets. We find that these deep learning methods perform significantly better than current state-of-the-art merger detection methods based on nonparametric systems like CAS and GM$_{20}$. Our method is end-to-end and robust to image noise and distortions; it can be applied directly without image preprocessing. We also find that transfer learning can act as a regulariser in some cases, leading to better overall classification accuracy ($p = 0.02$). Transfer learning on our full training set leads to a lowered error rate from 0.038 $\pm$ 1 down to 0.032 $\pm$ 1, a relative improvement of 15%. Finally, we perform a basic sanity-check by creating a merger sample with our method, and comparing with an already existing, manually created merger catalogue in terms of colour-mass distribution and stellar mass function.