 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstroMLab 4: Benchmark-Topping Performance in Astronomy Q&A with a 70B-Parameter Domain-Specialized Reasoning Model
May 23, 2025General-purpose large language models, despite their broad capabilities, often struggle with specialized domain knowledge, a limitation particularly pronounced in more accessible, lower-parameter versions. This gap hinders their deployment as effective agents in demanding fields such as astronomy. Building on our prior work with AstroSage-8B, this study introduces AstroSage-70B, a significantly larger and more advanced domain-specialized natural-language AI assistant. It is designed for research and education across astronomy, astrophysics, space science, astroparticle physics, cosmology, and astronomical instrumentation. Developed from the Llama-3.1-70B foundation, AstroSage-70B underwent extensive continued pre-training on a vast corpus of astronomical literature, followed by supervised fine-tuning and model merging. Beyond its 70-billion parameter scale, this model incorporates refined datasets, judiciously chosen learning hyperparameters, and improved training procedures, achieving state-of-the-art performance on complex astronomical tasks. Notably, we integrated reasoning chains into the SFT dataset, enabling AstroSage-70B to either answer the user query immediately, or first emit a human-readable thought process. Evaluated on the AstroMLab-1 benchmark -- comprising 4,425 questions from literature withheld during training -- AstroSage-70B achieves state-of-the-art performance. It surpasses all other tested open-weight and proprietary models, including leading systems like o3, Gemini-2.5-Pro, Claude-3.7-Sonnet, Deepseek-R1, and Qwen-3-235B, even those with API costs two orders of magnitude higher. This work demonstrates that domain specialization, when applied to large-scale models, can enable them to outperform generalist counterparts in specialized knowledge areas like astronomy, thereby advancing the frontier of AI capabilities in the field.
AstroMLab 2: AstroLLaMA-2-70B Model and Benchmarking Specialised LLMs for Astronomy
Sep 29, 2024Continual pretraining of large language models on domain-specific data has been proposed to enhance performance on downstream tasks. In astronomy, the previous absence of astronomy-focused benchmarks has hindered objective evaluation of these specialized LLM models. Leveraging a recent initiative to curate high-quality astronomical MCQs, this study aims to quantitatively assess specialized LLMs in astronomy. We find that the previously released AstroLLaMA series, based on LLaMA-2-7B, underperforms compared to the base model. We demonstrate that this performance degradation can be partially mitigated by utilizing high-quality data for continual pretraining, such as summarized text from arXiv. Despite the observed catastrophic forgetting in smaller models, our results indicate that continual pretraining on the 70B model can yield significant improvements. However, the current supervised fine-tuning dataset still constrains the performance of instruct models. In conjunction with this study, we introduce a new set of models, AstroLLaMA-3-8B and AstroLLaMA-2-70B, building upon the previous AstroLLaMA series.
pathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.
AstroMLab 1: Who Wins Astronomy Jeopardy!?
Jul 15, 2024We present a comprehensive evaluation of proprietary and open-weights large language models using the first astronomy-specific benchmarking dataset. This dataset comprises 4,425 multiple-choice questions curated from the Annual Review of Astronomy and Astrophysics, covering a broad range of astrophysical topics. Our analysis examines model performance across various astronomical subfields and assesses response calibration, crucial for potential deployment in research environments. Claude-3.5-Sonnet outperforms competitors by up to 4.6 percentage points, achieving 85.0% accuracy. For proprietary models, we observed a universal reduction in cost every 3-to-12 months to achieve similar score in this particular astronomy benchmark. Open-source models have rapidly improved, with LLaMA-3-70b (80.6%) and Qwen-2-72b (77.7%) now competing with some of the best proprietary models. We identify performance variations across topics, with non-English-focused models generally struggling more in exoplanet-related fields, stellar astrophysics, and instrumentation related questions. These challenges likely stem from less abundant training data, limited historical context, and rapid recent developments in these areas. This pattern is observed across both open-weights and proprietary models, with regional dependencies evident, highlighting the impact of training data diversity on model performance in specialized scientific domains. Top-performing models demonstrate well-calibrated confidence, with correlations above 0.9 between confidence and correctness, though they tend to be slightly underconfident. The development for fast, low-cost inference of open-weights models presents new opportunities for affordable deployment in astronomy. The rapid progress observed suggests that LLM-driven research in astronomy may become feasible in the near future.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
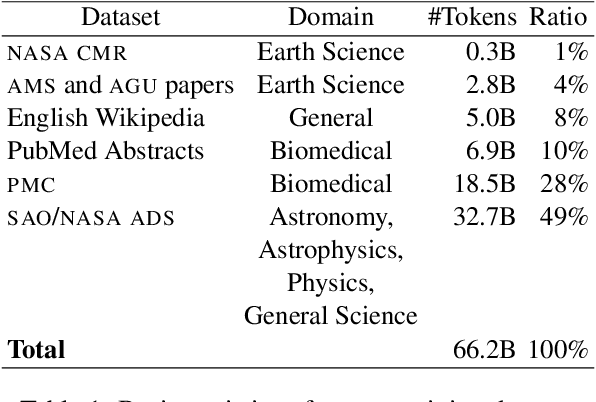
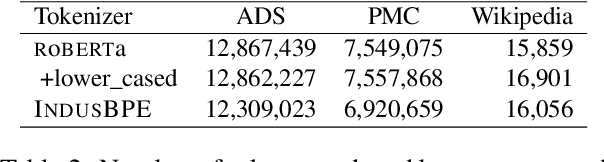

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Experimenting with Large Language Models and vector embeddings in NASA SciX
Dec 21, 2023Open-source Large Language Models enable projects such as NASA SciX (i.e., NASA ADS) to think out of the box and try alternative approaches for information retrieval and data augmentation, while respecting data copyright and users' privacy. However, when large language models are directly prompted with questions without any context, they are prone to hallucination. At NASA SciX we have developed an experiment where we created semantic vectors for our large collection of abstracts and full-text content, and we designed a prompt system to ask questions using contextual chunks from our system. Based on a non-systematic human evaluation, the experiment shows a lower degree of hallucination and better responses when using Retrieval Augmented Generation. Further exploration is required to design new features and data augmentation processes at NASA SciX that leverages this technology while respecting the high level of trust and quality that the project holds.
Identifying Planetary Names in Astronomy Papers: A Multi-Step Approach
Dec 17, 2023The automatic identification of planetary feature names in astronomy publications presents numerous challenges. These features include craters, defined as roughly circular depressions resulting from impact or volcanic activity; dorsas, which are elongate raised structures or wrinkle ridges; and lacus, small irregular patches of dark, smooth material on the Moon, referred to as "lake" (Planetary Names Working Group, n.d.). Many feature names overlap with places or people's names that they are named after, for example, Syria, Tempe, Einstein, and Sagan, to name a few (U.S. Geological Survey, n.d.). Some feature names have been used in many contexts, for instance, Apollo, which can refer to mission, program, sample, astronaut, seismic, seismometers, core, era, data, collection, instrument, and station, in addition to the crater on the Moon. Some feature names can appear in the text as adjectives, like the lunar craters Black, Green, and White. Some feature names in other contexts serve as directions, like craters West and South on the Moon. Additionally, some features share identical names across different celestial bodies, requiring disambiguation, such as the Adams crater, which exists on both the Moon and Mars. We present a multi-step pipeline combining rule-based filtering, statistical relevance analysis, part-of-speech (POS) tagging, named entity recognition (NER) model, hybrid keyword harvesting, knowledge graph (KG) matching, and inference with a locally installed large language model (LLM) to reliably identify planetary names despite these challenges. When evaluated on a dataset of astronomy papers from the Astrophysics Data System (ADS), this methodology achieves an F1-score over 0.97 in disambiguating planetary feature names.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023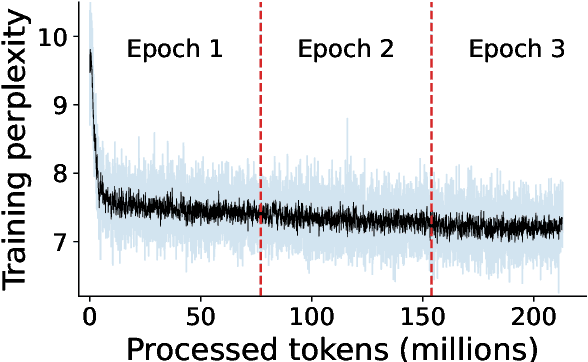

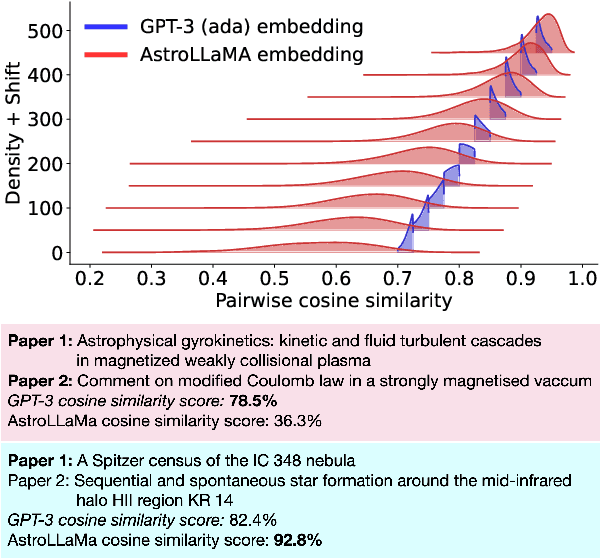
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
Improving astroBERT using Semantic Textual Similarity
Nov 29, 2022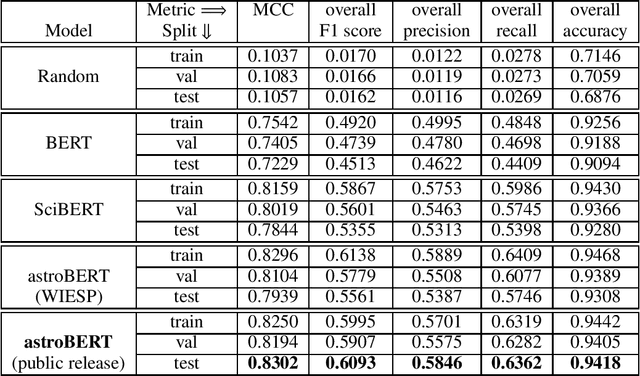
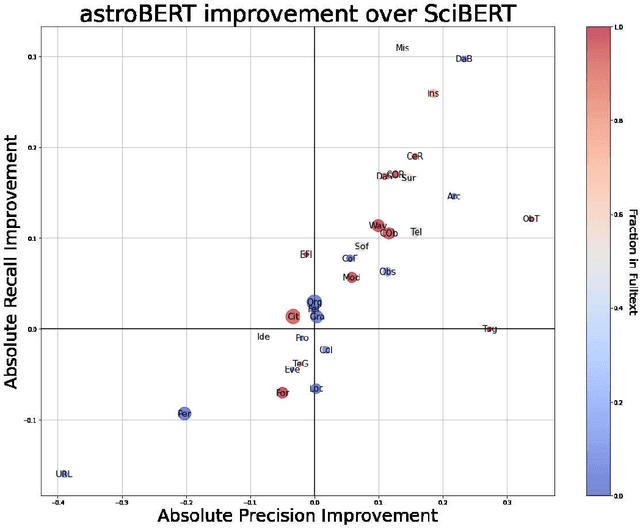
The NASA Astrophysics Data System (ADS) is an essential tool for researchers that allows them to explore the astronomy and astrophysics scientific literature, but it has yet to exploit recent advances in natural language processing. At ADASS 2021, we introduced astroBERT, a machine learning language model tailored to the text used in astronomy papers in ADS. In this work we: - announce the first public release of the astroBERT language model; - show how astroBERT improves over existing public language models on astrophysics specific tasks; - and detail how ADS plans to harness the unique structure of scientific papers, the citation graph and citation context, to further improve astroBERT.
Building astroBERT, a language model for Astronomy & Astrophysics
Dec 01, 2021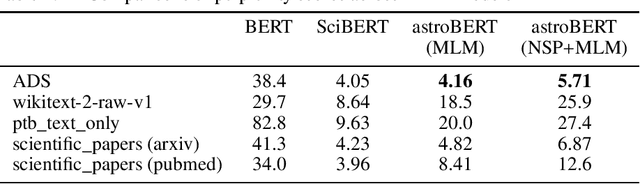
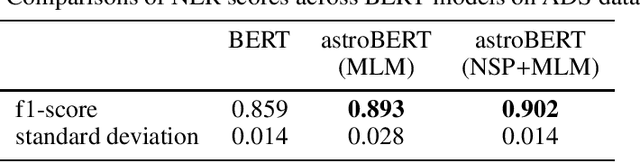
The existing search tools for exploring the NASA Astrophysics Data System (ADS) can be quite rich and empowering (e.g., similar and trending operators), but researchers are not yet allowed to fully leverage semantic search. For example, a query for "results from the Planck mission" should be able to distinguish between all the various meanings of Planck (person, mission, constant, institutions and more) without further clarification from the user. At ADS, we are applying modern machine learning and natural language processing techniques to our dataset of recent astronomy publications to train astroBERT, a deeply contextual language model based on research at Google. Using astroBERT, we aim to enrich the ADS dataset and improve its discoverability, and in particular we are developing our own named entity recognition tool. We present here our preliminary results and lessons learned.