 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Experimenting with Large Language Models and vector embeddings in NASA SciX
Dec 21, 2023Open-source Large Language Models enable projects such as NASA SciX (i.e., NASA ADS) to think out of the box and try alternative approaches for information retrieval and data augmentation, while respecting data copyright and users' privacy. However, when large language models are directly prompted with questions without any context, they are prone to hallucination. At NASA SciX we have developed an experiment where we created semantic vectors for our large collection of abstracts and full-text content, and we designed a prompt system to ask questions using contextual chunks from our system. Based on a non-systematic human evaluation, the experiment shows a lower degree of hallucination and better responses when using Retrieval Augmented Generation. Further exploration is required to design new features and data augmentation processes at NASA SciX that leverages this technology while respecting the high level of trust and quality that the project holds.
Improving astroBERT using Semantic Textual Similarity
Nov 29, 2022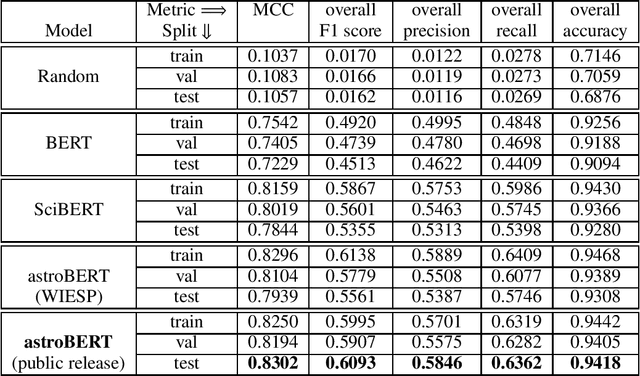
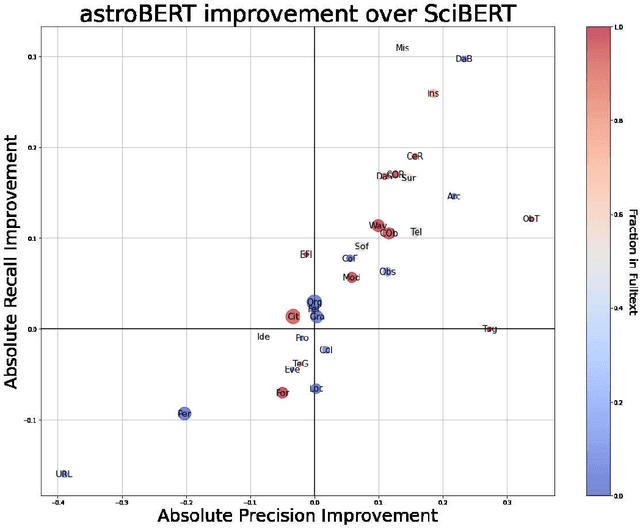
The NASA Astrophysics Data System (ADS) is an essential tool for researchers that allows them to explore the astronomy and astrophysics scientific literature, but it has yet to exploit recent advances in natural language processing. At ADASS 2021, we introduced astroBERT, a machine learning language model tailored to the text used in astronomy papers in ADS. In this work we: - announce the first public release of the astroBERT language model; - show how astroBERT improves over existing public language models on astrophysics specific tasks; - and detail how ADS plans to harness the unique structure of scientific papers, the citation graph and citation context, to further improve astroBERT.