 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimenting with Large Language Models and vector embeddings in NASA SciX
Dec 21, 2023Open-source Large Language Models enable projects such as NASA SciX (i.e., NASA ADS) to think out of the box and try alternative approaches for information retrieval and data augmentation, while respecting data copyright and users' privacy. However, when large language models are directly prompted with questions without any context, they are prone to hallucination. At NASA SciX we have developed an experiment where we created semantic vectors for our large collection of abstracts and full-text content, and we designed a prompt system to ask questions using contextual chunks from our system. Based on a non-systematic human evaluation, the experiment shows a lower degree of hallucination and better responses when using Retrieval Augmented Generation. Further exploration is required to design new features and data augmentation processes at NASA SciX that leverages this technology while respecting the high level of trust and quality that the project holds.
Identifying Planetary Names in Astronomy Papers: A Multi-Step Approach
Dec 17, 2023The automatic identification of planetary feature names in astronomy publications presents numerous challenges. These features include craters, defined as roughly circular depressions resulting from impact or volcanic activity; dorsas, which are elongate raised structures or wrinkle ridges; and lacus, small irregular patches of dark, smooth material on the Moon, referred to as "lake" (Planetary Names Working Group, n.d.). Many feature names overlap with places or people's names that they are named after, for example, Syria, Tempe, Einstein, and Sagan, to name a few (U.S. Geological Survey, n.d.). Some feature names have been used in many contexts, for instance, Apollo, which can refer to mission, program, sample, astronaut, seismic, seismometers, core, era, data, collection, instrument, and station, in addition to the crater on the Moon. Some feature names can appear in the text as adjectives, like the lunar craters Black, Green, and White. Some feature names in other contexts serve as directions, like craters West and South on the Moon. Additionally, some features share identical names across different celestial bodies, requiring disambiguation, such as the Adams crater, which exists on both the Moon and Mars. We present a multi-step pipeline combining rule-based filtering, statistical relevance analysis, part-of-speech (POS) tagging, named entity recognition (NER) model, hybrid keyword harvesting, knowledge graph (KG) matching, and inference with a locally installed large language model (LLM) to reliably identify planetary names despite these challenges. When evaluated on a dataset of astronomy papers from the Astrophysics Data System (ADS), this methodology achieves an F1-score over 0.97 in disambiguating planetary feature names.
Improving astroBERT using Semantic Textual Similarity
Nov 29, 2022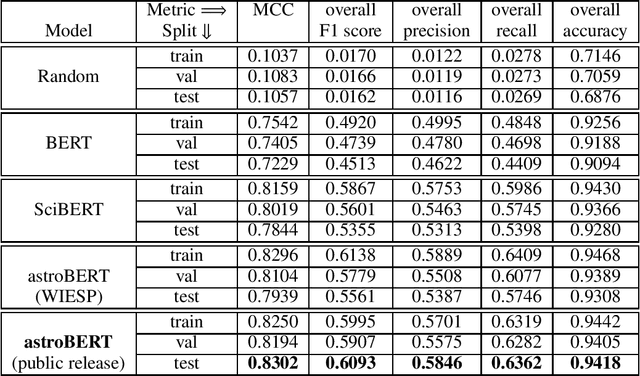
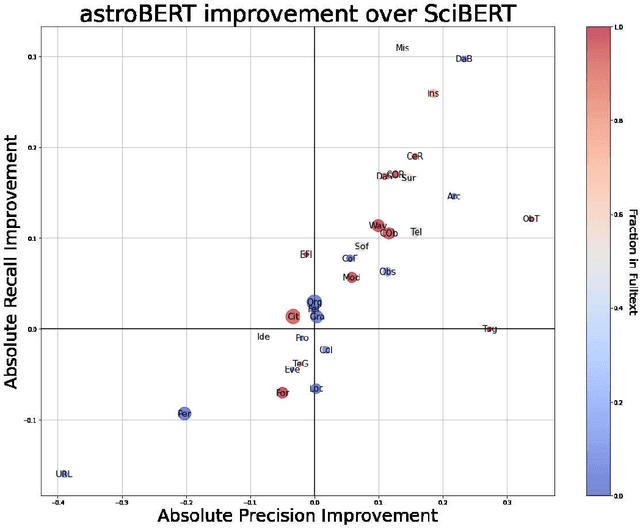
The NASA Astrophysics Data System (ADS) is an essential tool for researchers that allows them to explore the astronomy and astrophysics scientific literature, but it has yet to exploit recent advances in natural language processing. At ADASS 2021, we introduced astroBERT, a machine learning language model tailored to the text used in astronomy papers in ADS. In this work we: - announce the first public release of the astroBERT language model; - show how astroBERT improves over existing public language models on astrophysics specific tasks; - and detail how ADS plans to harness the unique structure of scientific papers, the citation graph and citation context, to further improve astroBERT.
Building astroBERT, a language model for Astronomy & Astrophysics
Dec 01, 2021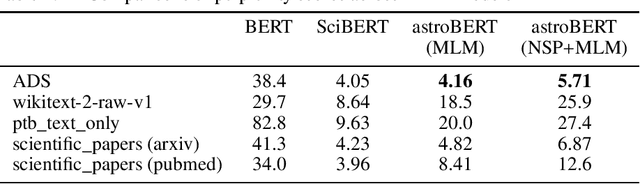
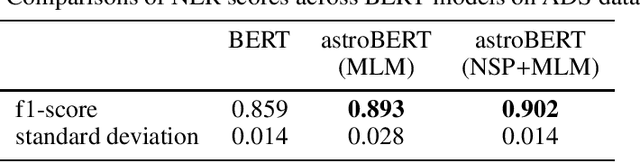
The existing search tools for exploring the NASA Astrophysics Data System (ADS) can be quite rich and empowering (e.g., similar and trending operators), but researchers are not yet allowed to fully leverage semantic search. For example, a query for "results from the Planck mission" should be able to distinguish between all the various meanings of Planck (person, mission, constant, institutions and more) without further clarification from the user. At ADS, we are applying modern machine learning and natural language processing techniques to our dataset of recent astronomy publications to train astroBERT, a deeply contextual language model based on research at Google. Using astroBERT, we aim to enrich the ADS dataset and improve its discoverability, and in particular we are developing our own named entity recognition tool. We present here our preliminary results and lessons learned.