 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimenting with Large Language Models and vector embeddings in NASA SciX
Dec 21, 2023Open-source Large Language Models enable projects such as NASA SciX (i.e., NASA ADS) to think out of the box and try alternative approaches for information retrieval and data augmentation, while respecting data copyright and users' privacy. However, when large language models are directly prompted with questions without any context, they are prone to hallucination. At NASA SciX we have developed an experiment where we created semantic vectors for our large collection of abstracts and full-text content, and we designed a prompt system to ask questions using contextual chunks from our system. Based on a non-systematic human evaluation, the experiment shows a lower degree of hallucination and better responses when using Retrieval Augmented Generation. Further exploration is required to design new features and data augmentation processes at NASA SciX that leverages this technology while respecting the high level of trust and quality that the project holds.
Improving astroBERT using Semantic Textual Similarity
Nov 29, 2022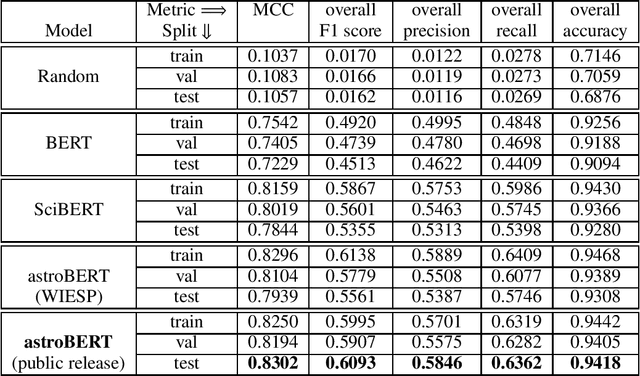
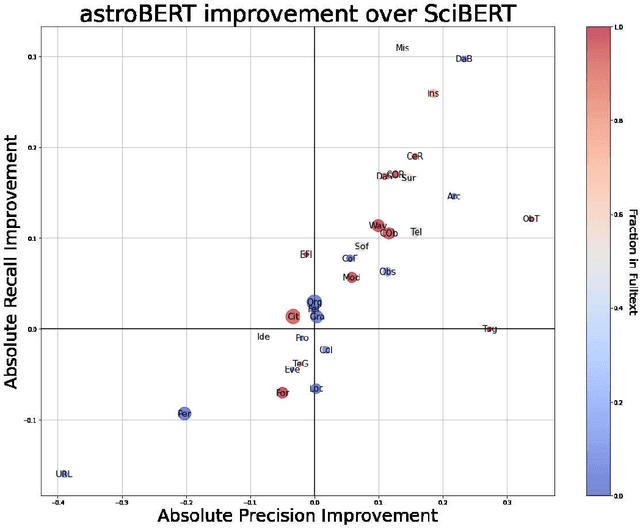
The NASA Astrophysics Data System (ADS) is an essential tool for researchers that allows them to explore the astronomy and astrophysics scientific literature, but it has yet to exploit recent advances in natural language processing. At ADASS 2021, we introduced astroBERT, a machine learning language model tailored to the text used in astronomy papers in ADS. In this work we: - announce the first public release of the astroBERT language model; - show how astroBERT improves over existing public language models on astrophysics specific tasks; - and detail how ADS plans to harness the unique structure of scientific papers, the citation graph and citation context, to further improve astroBERT.
Building astroBERT, a language model for Astronomy & Astrophysics
Dec 01, 2021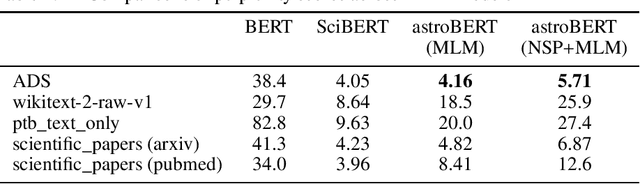
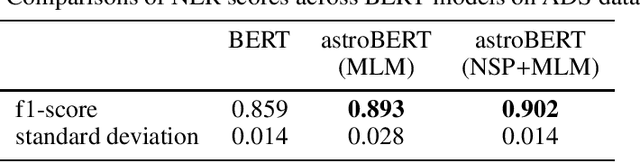
The existing search tools for exploring the NASA Astrophysics Data System (ADS) can be quite rich and empowering (e.g., similar and trending operators), but researchers are not yet allowed to fully leverage semantic search. For example, a query for "results from the Planck mission" should be able to distinguish between all the various meanings of Planck (person, mission, constant, institutions and more) without further clarification from the user. At ADS, we are applying modern machine learning and natural language processing techniques to our dataset of recent astronomy publications to train astroBERT, a deeply contextual language model based on research at Google. Using astroBERT, we aim to enrich the ADS dataset and improve its discoverability, and in particular we are developing our own named entity recognition tool. We present here our preliminary results and lessons learned.
Advice from the Oracle: Really Intelligent Information Retrieval
Jan 02, 2018What is "intelligent" information retrieval? Essentially this is asking what is intelligence, in this article I will attempt to show some of the aspects of human intelligence, as related to information retrieval. I will do this by the device of a semi-imaginary Oracle. Every Observatory has an oracle, someone who is a distinguished scientist, has great administrative responsibilities, acts as mentor to a number of less senior people, and as trusted advisor to even the most accomplished scientists, and knows essentially everyone in the field. In an appendix I will present a brief summary of the Statistical Factor Space method for text indexing and retrieval, and indicate how it will be used in the Astrophysics Data System Abstract Service. 2018 Keywords: Personal Digital Assistant; Supervised Topic Models
* Author copy; published 25 years ago at the beginning of the Astrophysics Data System; 2018 keywords added
Multilingual Topic Models
Dec 18, 2017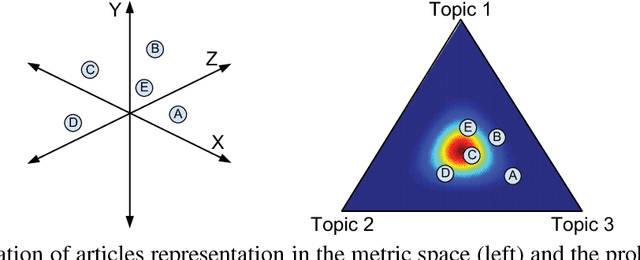
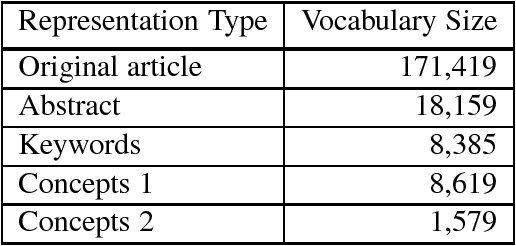
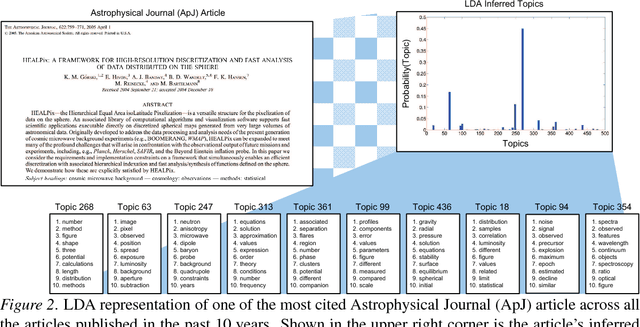
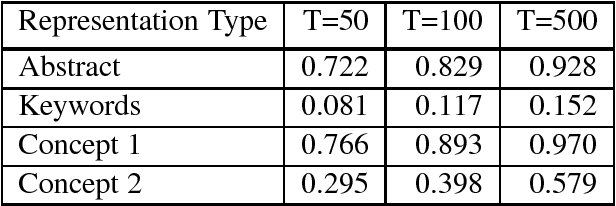
Scientific publications have evolved several features for mitigating vocabulary mismatch when indexing, retrieving, and computing similarity between articles. These mitigation strategies range from simply focusing on high-value article sections, such as titles and abstracts, to assigning keywords, often from controlled vocabularies, either manually or through automatic annotation. Various document representation schemes possess different cost-benefit tradeoffs. In this paper, we propose to model different representations of the same article as translations of each other, all generated from a common latent representation in a multilingual topic model. We start with a methodological overview on latent variable models for parallel document representations that could be used across many information science tasks. We then show how solving the inference problem of mapping diverse representations into a shared topic space allows us to evaluate representations based on how topically similar they are to the original article. In addition, our proposed approach provides means to discover where different concept vocabularies require improvement.
A History of Cluster Analysis Using the Classification Society's Bibliography Over Four Decades
Aug 16, 2013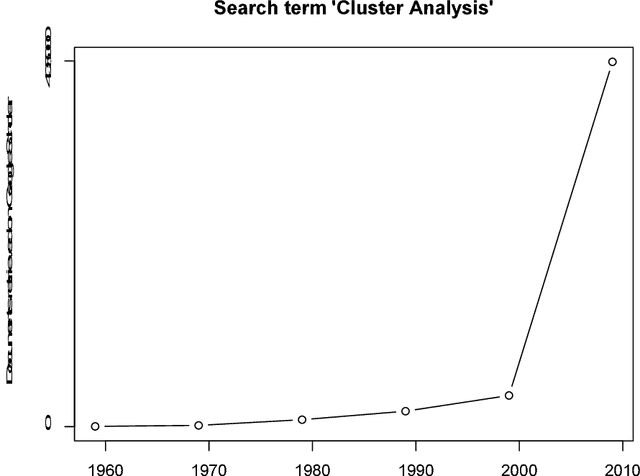
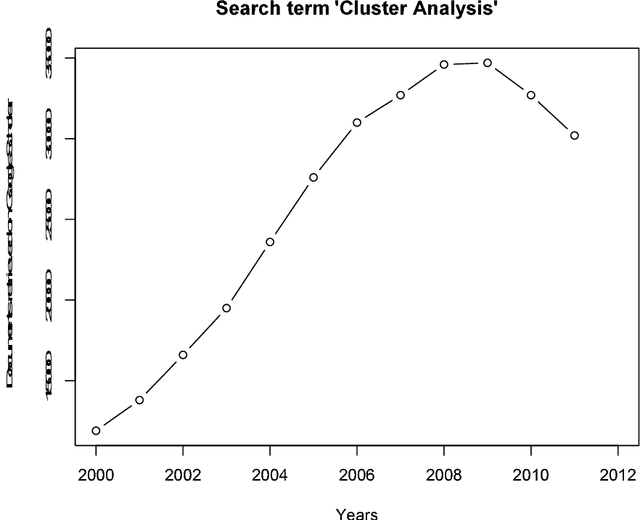

The Classification Literature Automated Search Service, an annual bibliography based on citation of one or more of a set of around 80 book or journal publications, ran from 1972 to 2012. We analyze here the years 1994 to 2011. The Classification Society's Service, as it was termed, has been produced by the Classification Society. In earlier decades it was distributed as a diskette or CD with the Journal of Classification. Among our findings are the following: an enormous increase in scholarly production post approximately 2000; a very major increase in quantity, coupled with work in different disciplines, from approximately 2004; and a major shift also from cluster analysis in earlier times having mathematics and psychology as disciplines of the journals published in, and affiliations of authors, contrasted with, in more recent times, a "centre of gravity" in management and engineering.