 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCore Conflictual Relationship: Text Mining to Discover What and When
May 28, 2018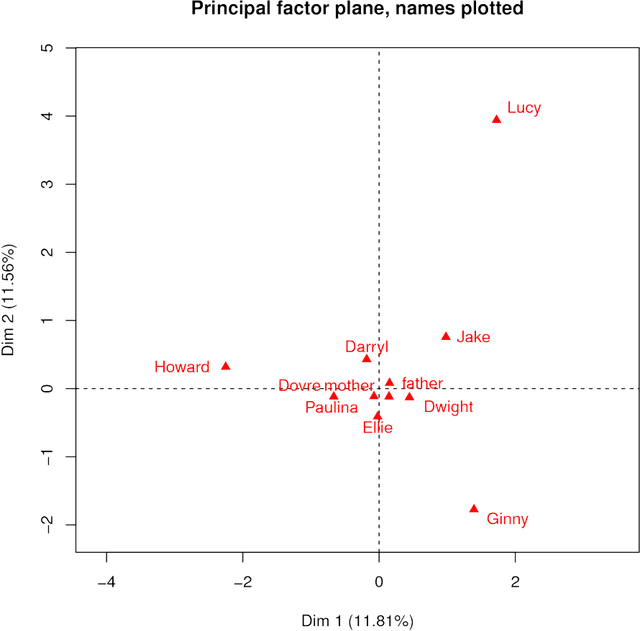
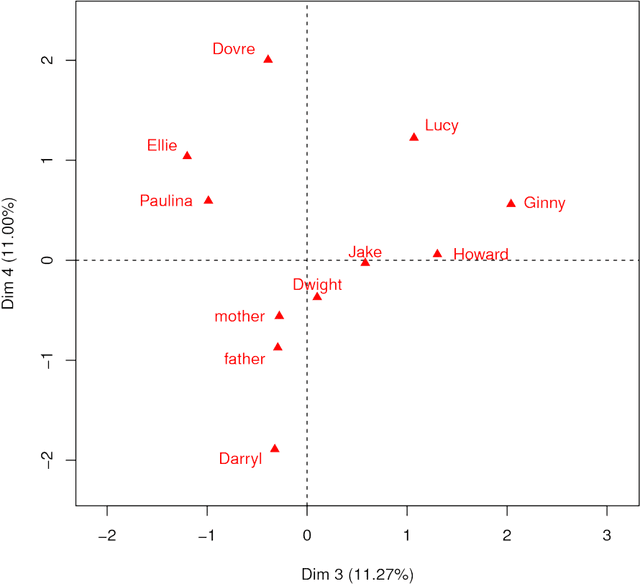
Following detailed presentation of the Core Conflictual Relationship Theme (CCRT), there is the objective of relevant methods for what has been described as verbalization and visualization of data. Such is also termed data mining and text mining, and knowledge discovery in data. The Correspondence Analysis methodology, also termed Geometric Data Analysis, is shown in a case study to be comprehensive and revealing. Computational efficiency depends on how the analysis process is structured. For both illustrative and revealing aspects of the case study here, relatively extensive dream reports are used. This Geometric Data Analysis confirms the validity of CCRT method.
Qualitative Judgement of Research Impact: Domain Taxonomy as a Fundamental Framework for Judgement of the Quality of Research
Apr 08, 2018
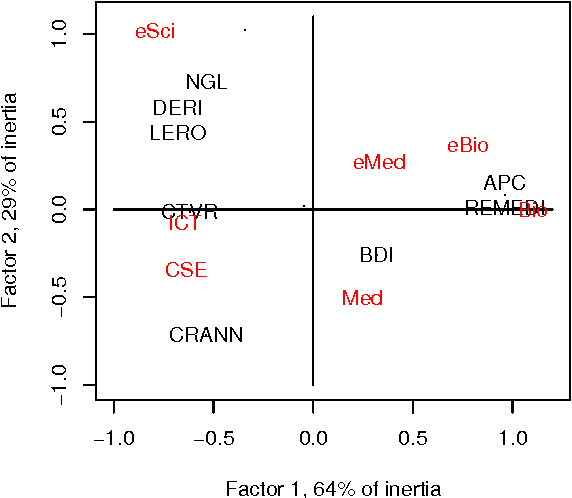
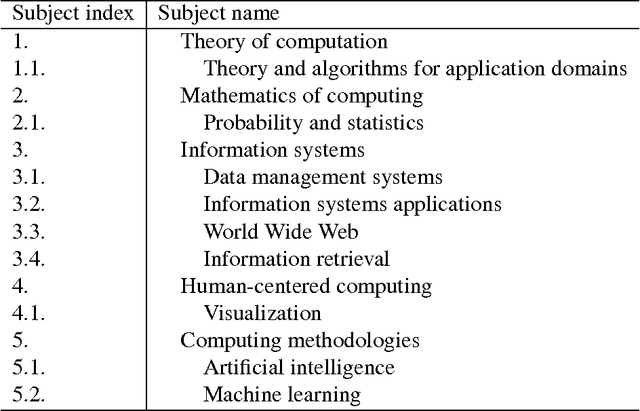
The appeal of metric evaluation of research impact has attracted considerable interest in recent times. Although the public at large and administrative bodies are much interested in the idea, scientists and other researchers are much more cautious, insisting that metrics are but an auxiliary instrument to the qualitative peer-based judgement. The goal of this article is to propose availing of such a well positioned construct as domain taxonomy as a tool for directly assessing the scope and quality of research. We first show how taxonomies can be used to analyse the scope and perspectives of a set of research projects or papers. Then we proceed to define a research team or researcher's rank by those nodes in the hierarchy that have been created or significantly transformed by the results of the researcher. An experimental test of the approach in the data analysis domain is described. Although the concept of taxonomy seems rather simplistic to describe all the richness of a research domain, its changes and use can be made transparent and subject to open discussions.
Contextualizing Geometric Data Analysis and Related Data Analytics: A Virtual Microscope for Big Data Analytics
Sep 15, 2017
The relevance and importance of contextualizing data analytics is described. Qualitative characteristics might form the context of quantitative analysis. Topics that are at issue include: contrast, baselining, secondary data sources, supplementary data sources, dynamic and heterogeneous data. In geometric data analysis, especially with the Correspondence Analysis platform, various case studies are both experimented with, and are reviewed. In such aspects as paradigms followed, and technical implementation, implicitly and explicitly, an important point made is the major relevance of such work for both burgeoning analytical needs and for new analytical areas including Big Data analytics, and so on. For the general reader, it is aimed to display and describe, first of all, the analytical outcomes that are subject to analysis here, and then proceed to detail the more quantitative outcomes that fully support the analytics carried out.
* 19 pages, 8 figures, 2 tables, Journal of Interdisciplinary Methodologies and Issues in Science, vol. 3, 2017. This version contains DOI, ISSN
Massive Data Clustering in Moderate Dimensions from the Dual Spaces of Observation and Attribute Data Clouds
Apr 06, 2017
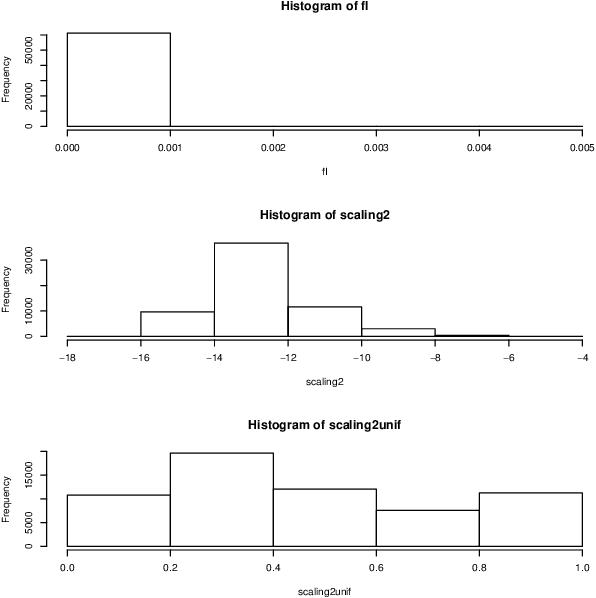
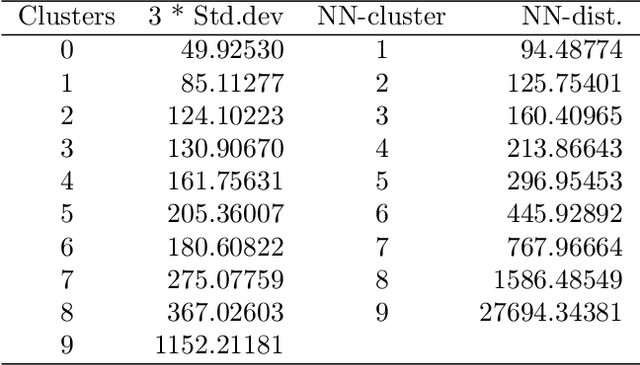
Cluster analysis of very high dimensional data can benefit from the properties of such high dimensionality. Informally expressed, in this work, our focus is on the analogous situation when the dimensionality is moderate to small, relative to a massively sized set of observations. Mathematically expressed, these are the dual spaces of observations and attributes. The point cloud of observations is in attribute space, and the point cloud of attributes is in observation space. In this paper, we begin by summarizing various perspectives related to methodologies that are used in multivariate analytics. We draw on these to establish an efficient clustering processing pipeline, both partitioning and hierarchical clustering.
Visualization of Jacques Lacan's Registers of the Psychoanalytic Field, and Discovery of Metaphor and of Metonymy. Analytical Case Study of Edgar Allan Poe's "The Purloined Letter"
Jan 30, 2017
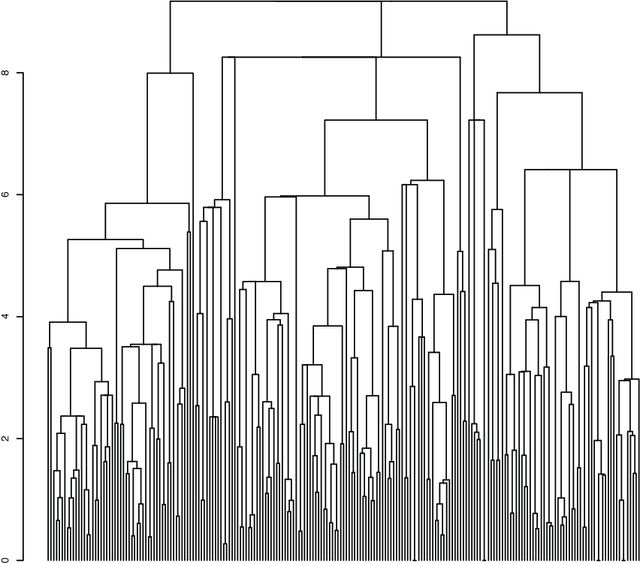
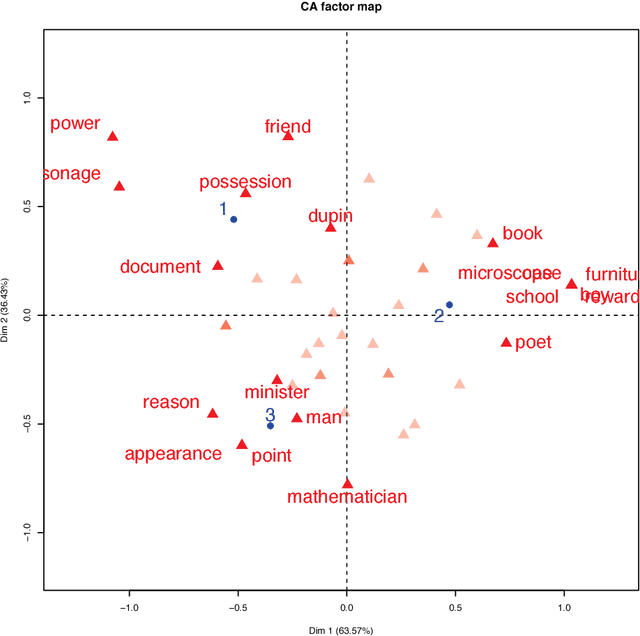

We start with a description of Lacan's work that we then take into our analytics methodology. In a first investigation, a Lacan-motivated template of the Poe story is fitted to the data. A segmentation of the storyline is used in order to map out the diachrony. Based on this, it will be shown how synchronous aspects, potentially related to Lacanian registers, can be sought. This demonstrates the effectiveness of an approach based on a model template of the storyline narrative. In a second and more comprehensive investigation, we develop an approach for revealing, that is, uncovering, Lacanian register relationships. Objectives of this work include the wide and general application of our methodology. This methodology is strongly based on the "letting the data speak" Correspondence Analysis analytics platform of Jean-Paul Benz\'ecri, that is also the geometric data analysis, both qualitative and quantitative analytics, developed by Pierre Bourdieu.
Big Data Scaling through Metric Mapping: Exploiting the Remarkable Simplicity of Very High Dimensional Spaces using Correspondence Analysis
Dec 13, 2015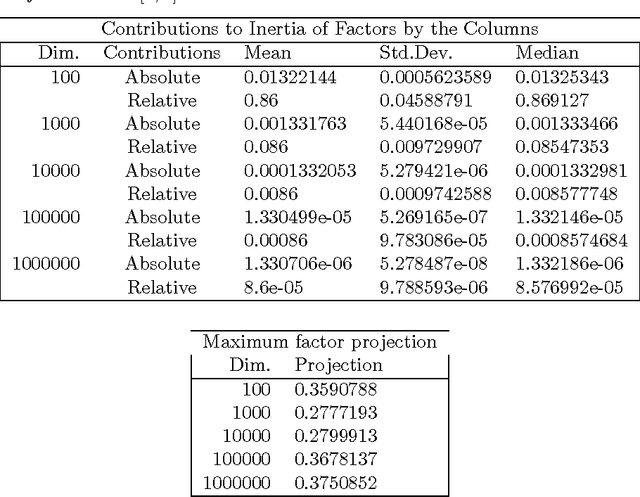
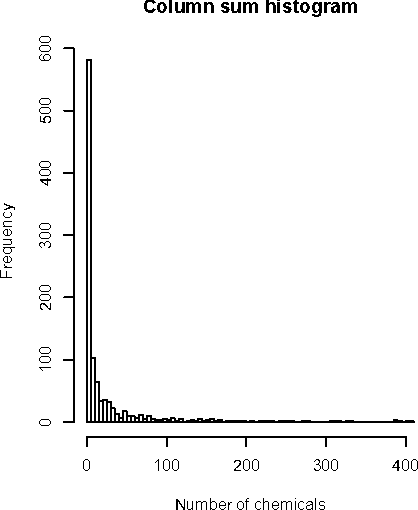
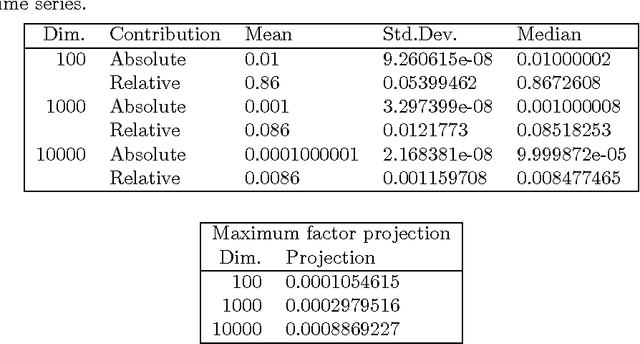
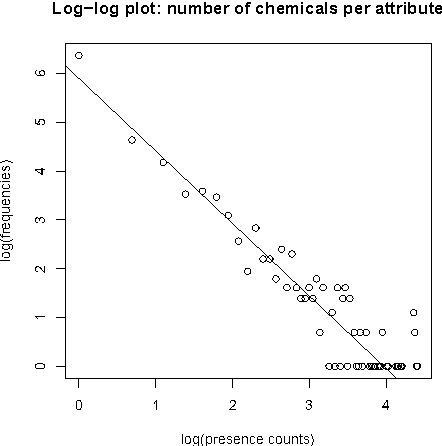
We present new findings in regard to data analysis in very high dimensional spaces. We use dimensionalities up to around one million. A particular benefit of Correspondence Analysis is its suitability for carrying out an orthonormal mapping, or scaling, of power law distributed data. Power law distributed data are found in many domains. Correspondence factor analysis provides a latent semantic or principal axes mapping. Our experiments use data from digital chemistry and finance, and other statistically generated data.
Correspondence Factor Analysis of Big Data Sets: A Case Study of 30 Million Words; and Contrasting Analytics using Apache Solr and Correspondence Analysis in R
Jul 06, 2015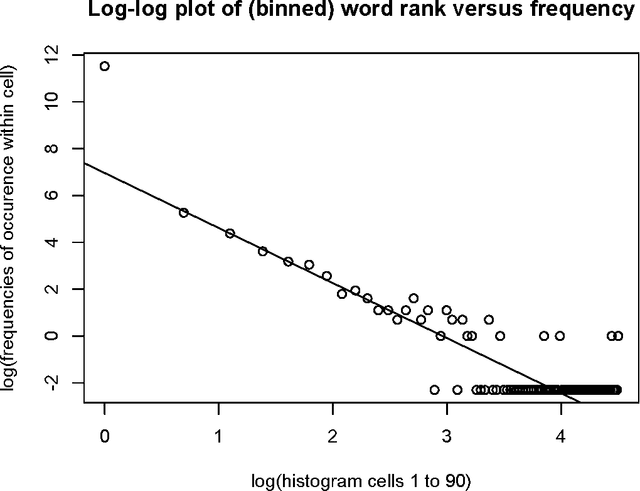
We consider a large number of text data sets. These are cooking recipes. Term distribution and other distributional properties of the data are investigated. Our aim is to look at various analytical approaches which allow for mining of information on both high and low detail scales. Metric space embedding is fundamental to our interest in the semantic properties of this data. We consider the projection of all data into analyses of aggregated versions of the data. We contrast that with projection of aggregated versions of the data into analyses of all the data. Analogously for the term set, we look at analysis of selected terms. We also look at inherent term associations such as between singular and plural. In addition to our use of Correspondence Analysis in R, for latent semantic space mapping, we also use Apache Solr. Setting up the Solr server and carrying out querying is described. A further novelty is that querying is supported in Solr based on the principal factor plane mapping of all the data. This uses a bounding box query, based on factor projections.
Pattern Recognition in Narrative: Tracking Emotional Expression in Context
May 04, 2015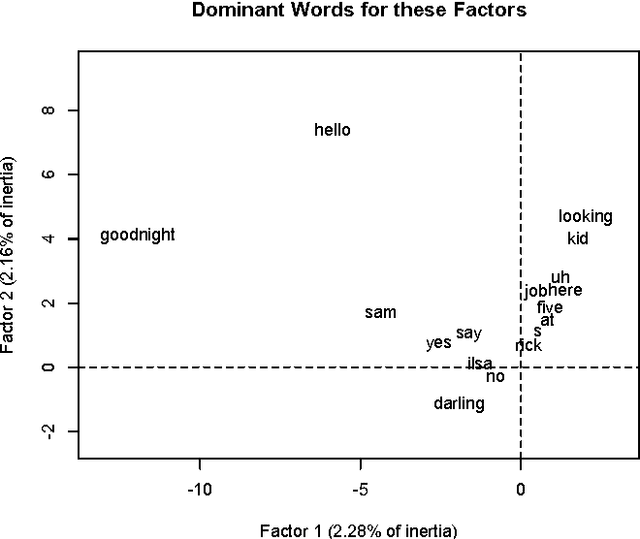
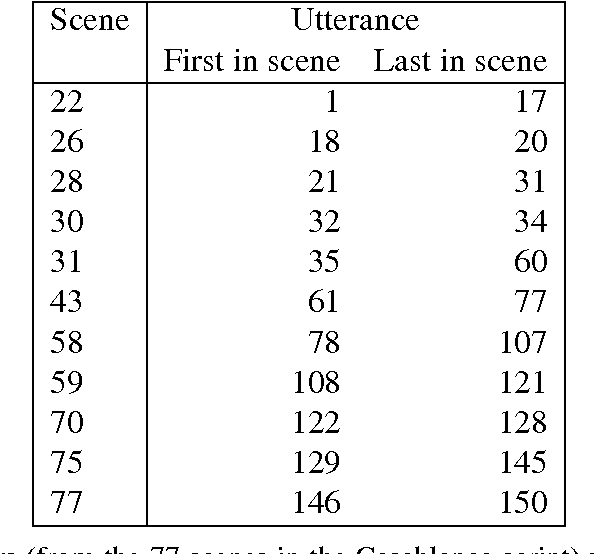
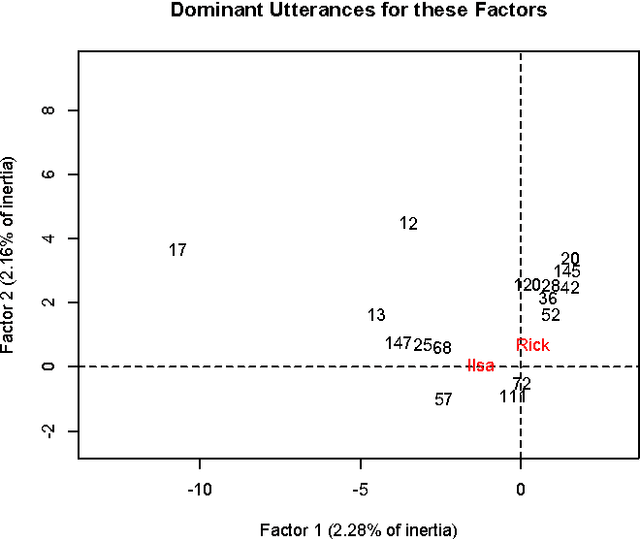
Using geometric data analysis, our objective is the analysis of narrative, with narrative of emotion being the focus in this work. The following two principles for analysis of emotion inform our work. Firstly, emotion is revealed not as a quality in its own right but rather through interaction. We study the 2-way relationship of Ilsa and Rick in the movie Casablanca, and the 3-way relationship of Emma, Charles and Rodolphe in the novel {\em Madame Bovary}. Secondly, emotion, that is expression of states of mind of subjects, is formed and evolves within the narrative that expresses external events and (personal, social, physical) context. In addition to the analysis methodology with key aspects that are innovative, the input data used is crucial. We use, firstly, dialogue, and secondly, broad and general description that incorporates dialogue. In a follow-on study, we apply our unsupervised narrative mapping to data streams with very low emotional expression. We map the narrative of Twitter streams. Thus we demonstrate map analysis of general narratives.
* 21 pages, 7 figures
Ultrametric Component Analysis with Application to Analysis of Text and of Emotion
Sep 14, 2013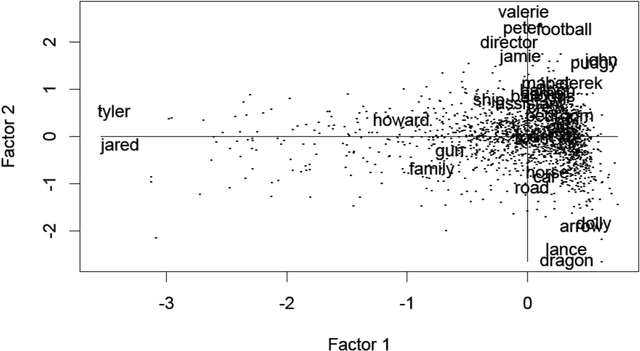
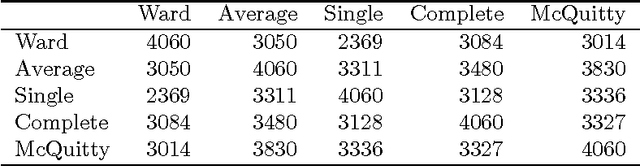
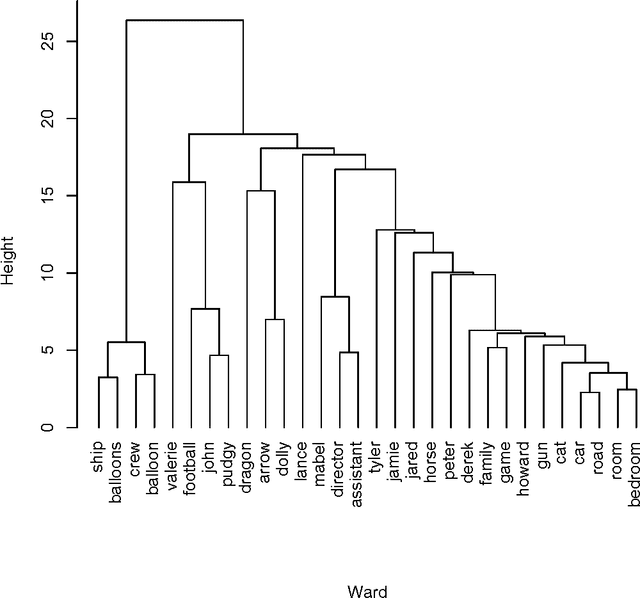
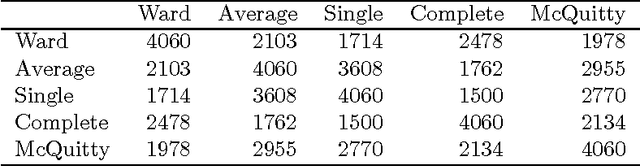
We review the theory and practice of determining what parts of a data set are ultrametric. It is assumed that the data set, to begin with, is endowed with a metric, and we include discussion of how this can be brought about if a dissimilarity, only, holds. The basis for part of the metric-endowed data set being ultrametric is to consider triplets of the observables (vectors). We develop a novel consensus of hierarchical clusterings. We do this in order to have a framework (including visualization and supporting interpretation) for the parts of the data that are determined to be ultrametric. Furthermore a major objective is to determine locally ultrametric relationships as opposed to non-local ultrametric relationships. As part of this work, we also study a particular property of our ultrametricity coefficient, namely, it being a function of the difference of angles of the base angles of the isosceles triangle. This work is completed by a review of related work, on consensus hierarchies, and of a major new application, namely quantifying and interpreting the emotional content of narrative.
A History of Cluster Analysis Using the Classification Society's Bibliography Over Four Decades
Aug 16, 2013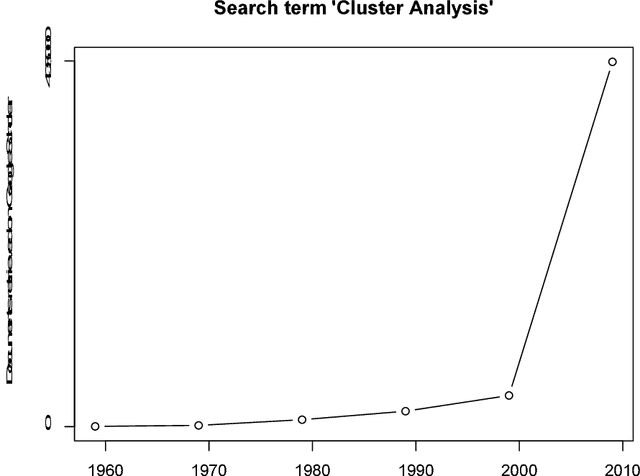
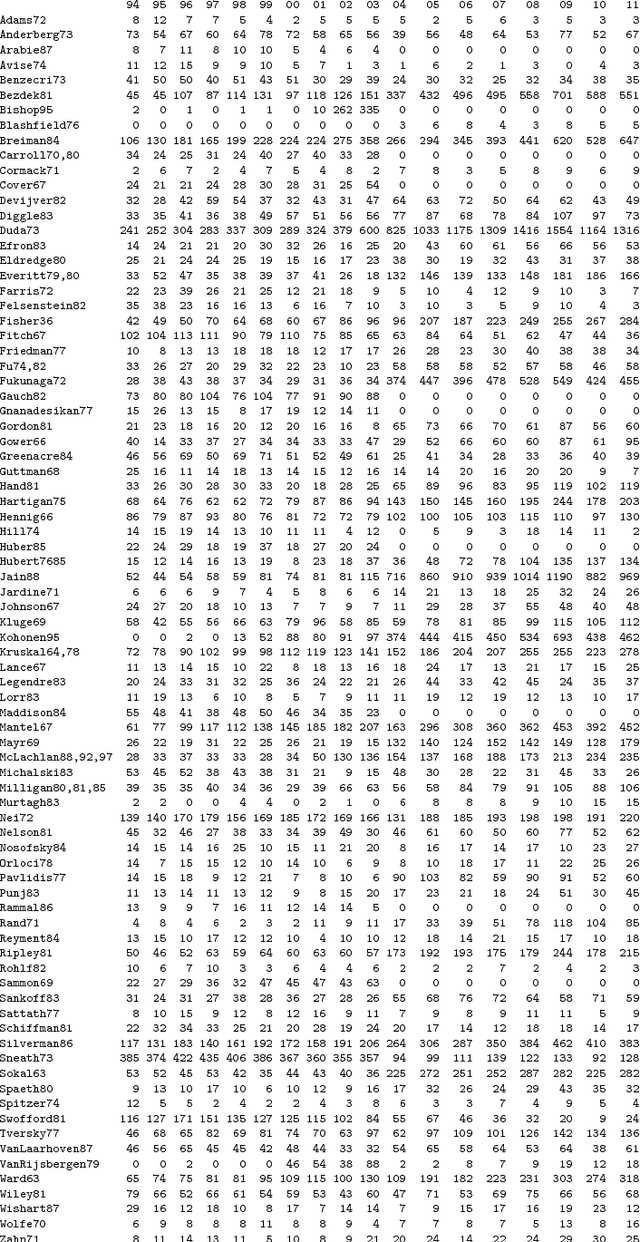
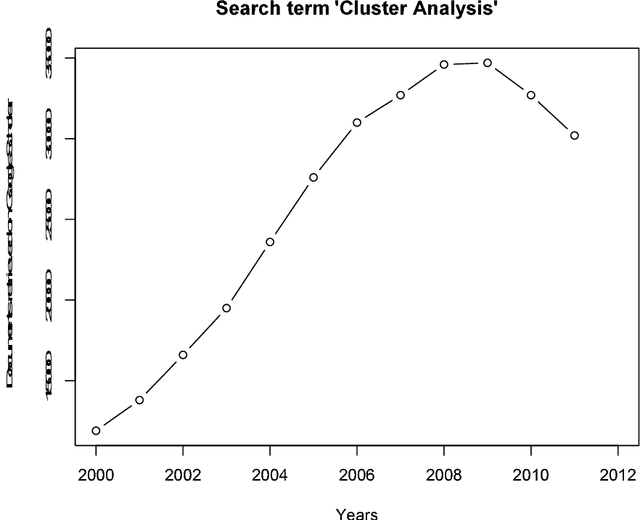

The Classification Literature Automated Search Service, an annual bibliography based on citation of one or more of a set of around 80 book or journal publications, ran from 1972 to 2012. We analyze here the years 1994 to 2011. The Classification Society's Service, as it was termed, has been produced by the Classification Society. In earlier decades it was distributed as a diskette or CD with the Journal of Classification. Among our findings are the following: an enormous increase in scholarly production post approximately 2000; a very major increase in quantity, coupled with work in different disciplines, from approximately 2004; and a major shift also from cluster analysis in earlier times having mathematics and psychology as disciplines of the journals published in, and affiliations of authors, contrasted with, in more recent times, a "centre of gravity" in management and engineering.