Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Data Clustering in Moderate Dimensions from the Dual Spaces of Observation and Attribute Data Clouds
Paper and Code
Apr 06, 2017
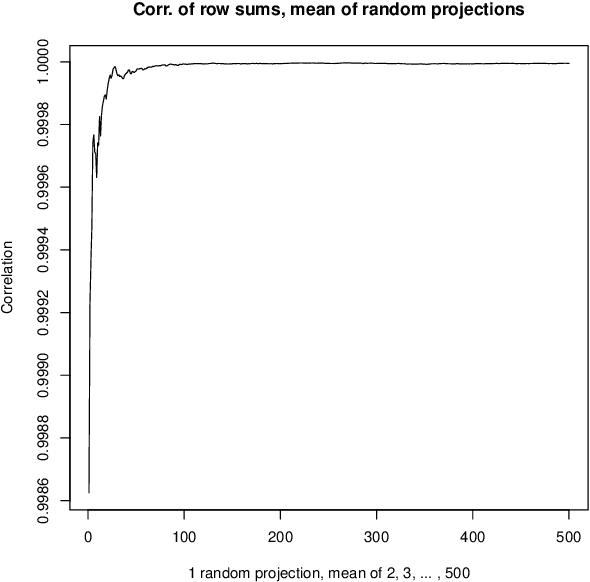
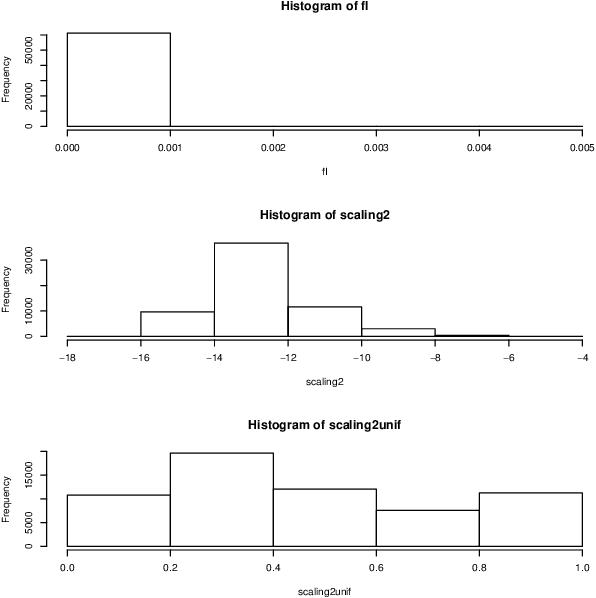
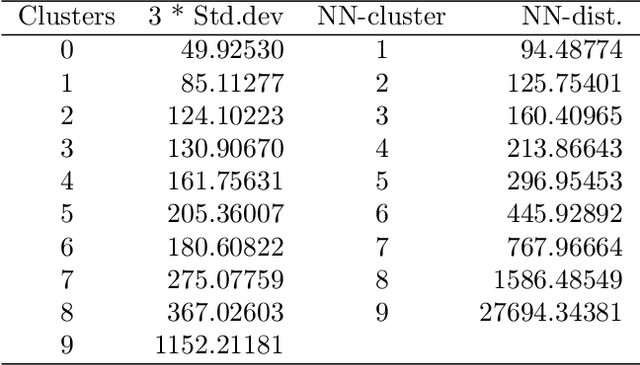
Cluster analysis of very high dimensional data can benefit from the properties of such high dimensionality. Informally expressed, in this work, our focus is on the analogous situation when the dimensionality is moderate to small, relative to a massively sized set of observations. Mathematically expressed, these are the dual spaces of observations and attributes. The point cloud of observations is in attribute space, and the point cloud of attributes is in observation space. In this paper, we begin by summarizing various perspectives related to methodologies that are used in multivariate analytics. We draw on these to establish an efficient clustering processing pipeline, both partitioning and hierarchical clustering.
* 17 pages, 2 figures
View paper on