 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrespondence Factor Analysis of Big Data Sets: A Case Study of 30 Million Words; and Contrasting Analytics using Apache Solr and Correspondence Analysis in R
Paper and Code
Jul 06, 2015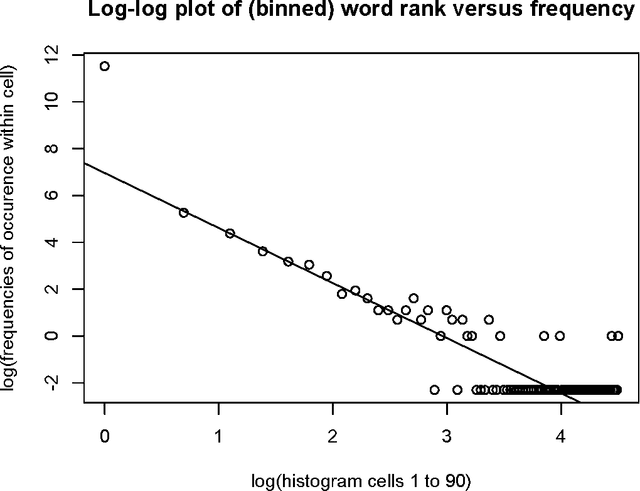
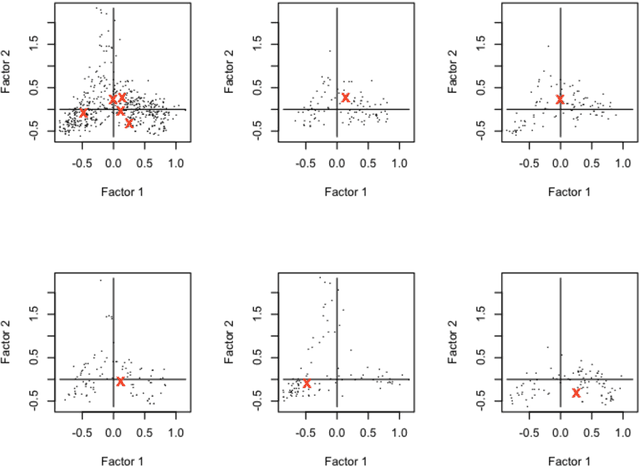
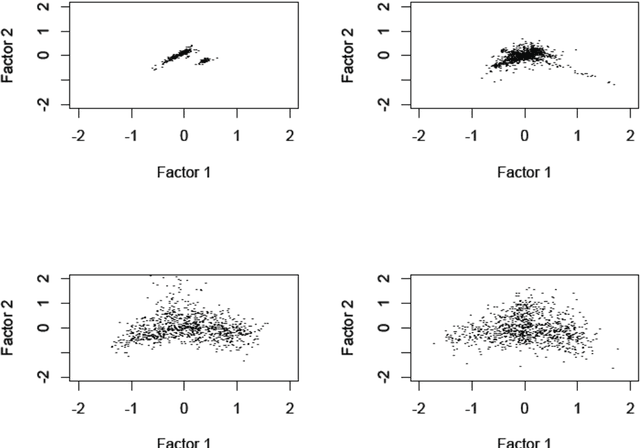
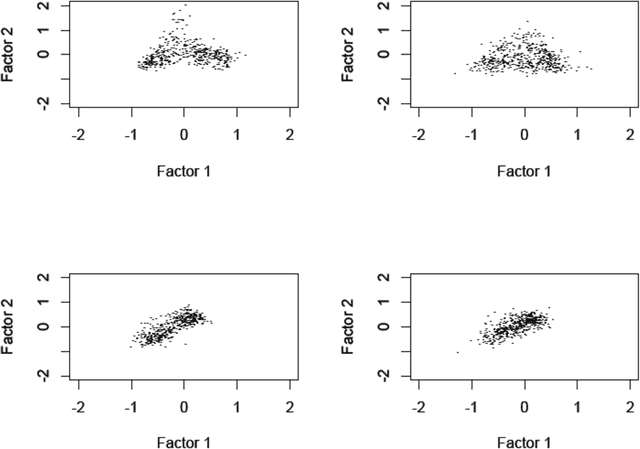
We consider a large number of text data sets. These are cooking recipes. Term distribution and other distributional properties of the data are investigated. Our aim is to look at various analytical approaches which allow for mining of information on both high and low detail scales. Metric space embedding is fundamental to our interest in the semantic properties of this data. We consider the projection of all data into analyses of aggregated versions of the data. We contrast that with projection of aggregated versions of the data into analyses of all the data. Analogously for the term set, we look at analysis of selected terms. We also look at inherent term associations such as between singular and plural. In addition to our use of Correspondence Analysis in R, for latent semantic space mapping, we also use Apache Solr. Setting up the Solr server and carrying out querying is described. A further novelty is that querying is supported in Solr based on the principal factor plane mapping of all the data. This uses a bounding box query, based on factor projections.