 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative Judgement of Research Impact: Domain Taxonomy as a Fundamental Framework for Judgement of the Quality of Research
Apr 08, 2018
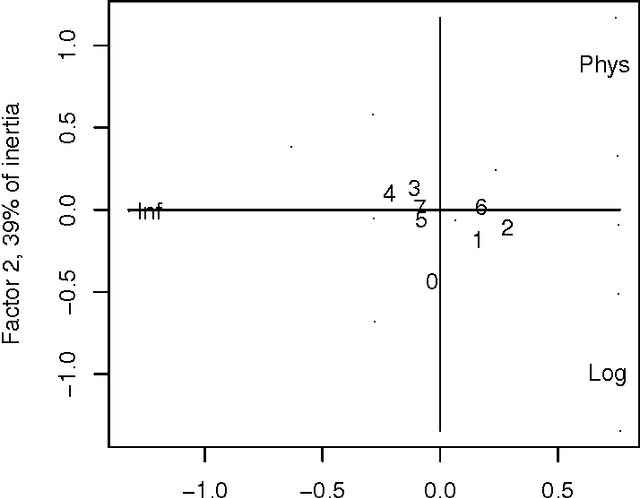
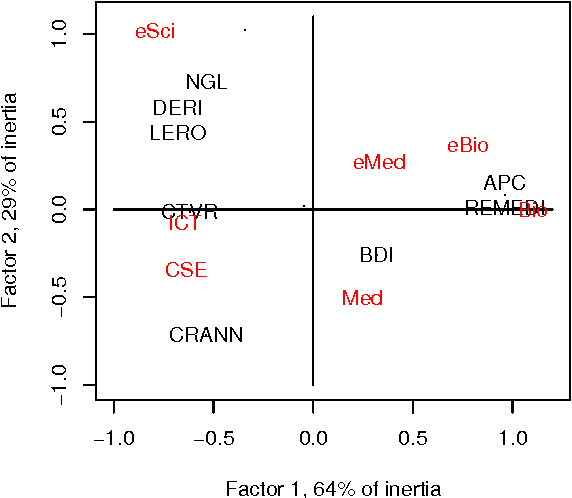
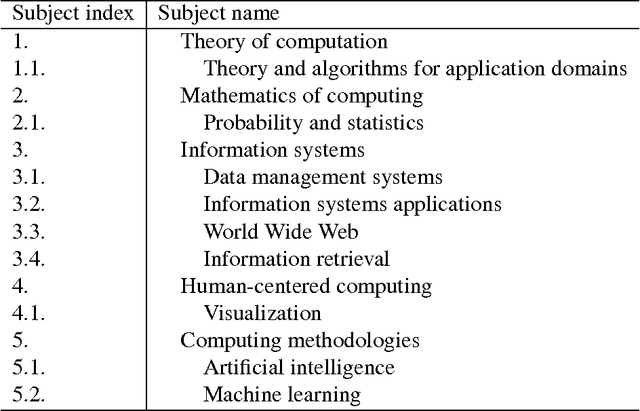
The appeal of metric evaluation of research impact has attracted considerable interest in recent times. Although the public at large and administrative bodies are much interested in the idea, scientists and other researchers are much more cautious, insisting that metrics are but an auxiliary instrument to the qualitative peer-based judgement. The goal of this article is to propose availing of such a well positioned construct as domain taxonomy as a tool for directly assessing the scope and quality of research. We first show how taxonomies can be used to analyse the scope and perspectives of a set of research projects or papers. Then we proceed to define a research team or researcher's rank by those nodes in the hierarchy that have been created or significantly transformed by the results of the researcher. An experimental test of the approach in the data analysis domain is described. Although the concept of taxonomy seems rather simplistic to describe all the richness of a research domain, its changes and use can be made transparent and subject to open discussions.
A-Ward_p\b{eta}: Effective hierarchical clustering using the Minkowski metric and a fast k -means initialisation
Nov 03, 2016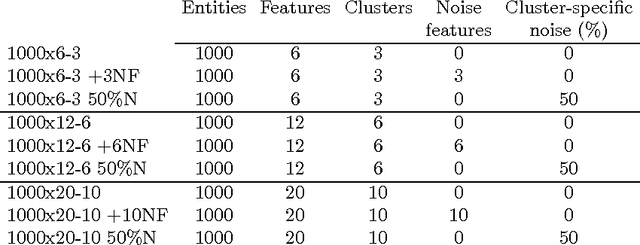
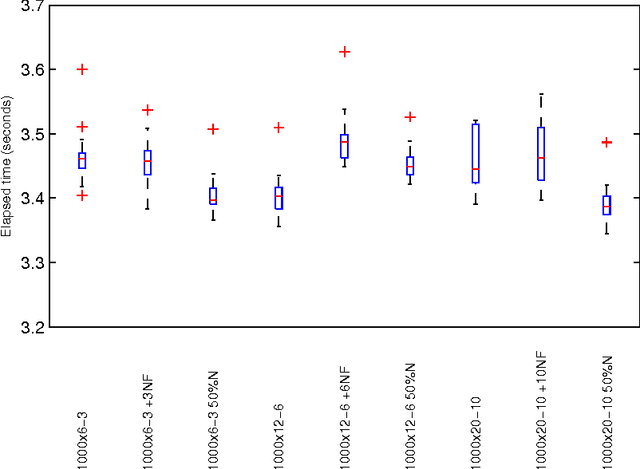
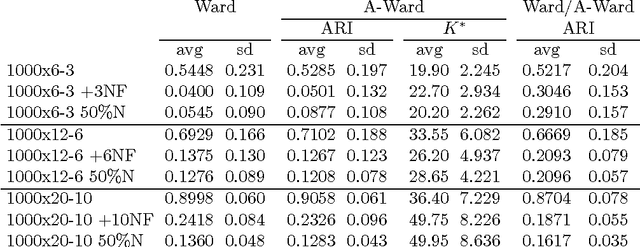
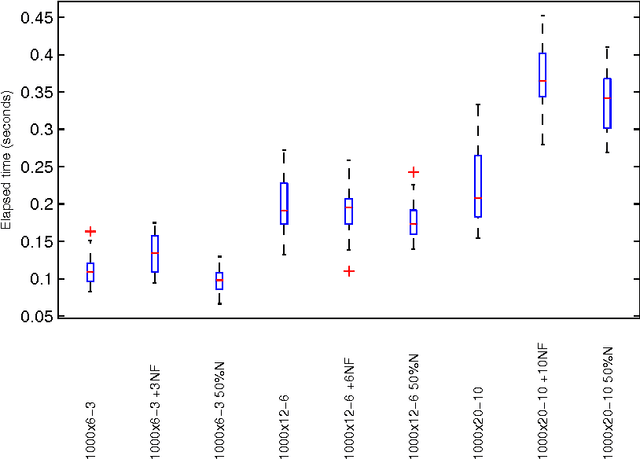
In this paper we make two novel contributions to hierarchical clustering. First, we introduce an anomalous pattern initialisation method for hierarchical clustering algorithms, called A-Ward, capable of substantially reducing the time they take to converge. This method generates an initial partition with a sufficiently large number of clusters. This allows the cluster merging process to start from this partition rather than from a trivial partition composed solely of singletons. Our second contribution is an extension of the Ward and Ward p algorithms to the situation where the feature weight exponent can differ from the exponent of the Minkowski distance. This new method, called A-Ward p\b{eta} , is able to generate a much wider variety of clustering solutions. We also demonstrate that its parameters can be estimated reasonably well by using a cluster validity index. We perform numerous experiments using data sets with two types of noise, insertion of noise features and blurring within-cluster values of some features. These experiments allow us to conclude: (i) our anomalous pattern initialisation method does indeed reduce the time a hierarchical clustering algorithm takes to complete, without negatively impacting its cluster recovery ability; (ii) A-Ward p\b{eta} provides better cluster recovery than both Ward and Ward p.
A Suffix Tree Approach to Email Filtering
Dec 06, 2005

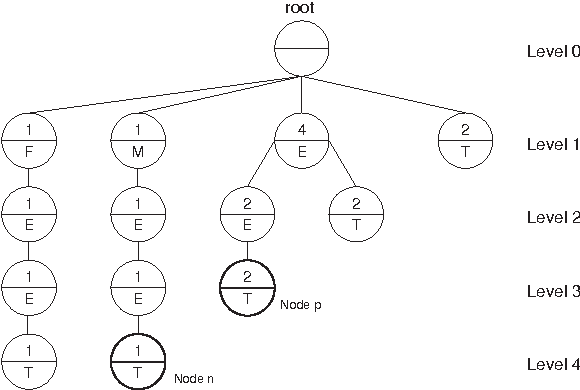

We present an approach to email filtering based on the suffix tree data structure. A method for the scoring of emails using the suffix tree is developed and a number of scoring and score normalisation functions are tested. Our results show that the character level representation of emails and classes facilitated by the suffix tree can significantly improve classification accuracy when compared with the currently popular methods, such as naive Bayes. We believe the method can be extended to the classification of documents in other domains.