 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Artificial Intelligence in the Context of Metrology
Jun 14, 2024We review research at the National Physical Laboratory (NPL) in the area of trustworthy artificial intelligence (TAI), and more specifically trustworthy machine learning (TML), in the context of metrology, the science of measurement. We describe three broad themes of TAI: technical, socio-technical and social, which play key roles in ensuring that the developed models are trustworthy and can be relied upon to make responsible decisions. From a metrology perspective we emphasise uncertainty quantification (UQ), and its importance within the framework of TAI to enhance transparency and trust in the outputs of AI systems. We then discuss three research areas within TAI that we are working on at NPL, and examine the certification of AI systems in terms of adherence to the characteristics of TAI.
Incorporating Dictionaries into a Neural Network Architecture to Extract COVID-19 Medical Concepts From Social Media
Sep 05, 2023We investigate the potential benefit of incorporating dictionary information into a neural network architecture for natural language processing. In particular, we make use of this architecture to extract several concepts related to COVID-19 from an on-line medical forum. We use a sample from the forum to manually curate one dictionary for each concept. In addition, we use MetaMap, which is a tool for extracting biomedical concepts, to identify a small number of semantic concepts. For a supervised concept extraction task on the forum data, our best model achieved a macro $F_1$ score of 90\%. A major difficulty in medical concept extraction is obtaining labelled data from which to build supervised models. We investigate the utility of our models to transfer to data derived from a different source in two ways. First for producing labels via weak learning and second to perform concept extraction. The dataset we use in this case comprises COVID-19 related tweets and we achieve an $F_1$ score 81\% for symptom concept extraction trained on weakly labelled data. The utility of our dictionaries is compared with a COVID-19 symptom dictionary that was constructed directly from Twitter. Further experiments that incorporate BERT and a COVID-19 version of BERTweet demonstrate that the dictionaries provide a commensurate result. Our results show that incorporating small domain dictionaries to deep learning models can improve concept extraction tasks. Moreover, models built using dictionaries generalize well and are transferable to different datasets on a similar task.
Triage and diagnosis of COVID-19 from medical social media
Mar 22, 2021

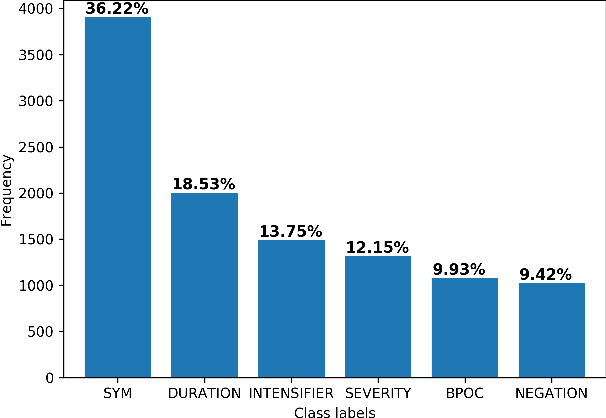
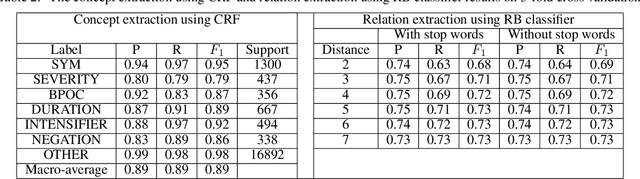
Objective: This study aims to develop an end-to-end natural language processing pipeline for triage and diagnosis of COVID-19 from patient-authored social media posts. Materials and Methods: The text processing pipeline first extracts COVID-19 symptoms and related concepts such as severity, duration, negations, and body parts from patients posts using conditional random fields. An unsupervised rule-based algorithm is then applied to establish relations between concepts in the next step of the pipeline. The extracted concepts and relations are subsequently used to construct two different vector representations of each post. These vectors are applied separately to build support vector machine learning models to triage patients into three categories and diagnose them for COVID-19. Results: We report that Macro- and Micro-averaged F_1 scores in the range of 71-96% and 61-87%, respectively, for the triage and diagnosis of COVID-19, when the models are trained on ground truth labelled data. Our experimental results indicate that similar performance can be achieved when the models are trained using predicted labels from concept extraction and rule-based classifiers, thus yielding end-to-end machine learning. Discussion: We highlight important features uncovered by our diagnostic machine learning models and compare them with the most frequent symptoms revealed in another COVID-19 dataset. In particular, we found that the most important features are not always the most frequent ones. Conclusions: Our preliminary results show that it is possible to automatically triage and diagnose patients for COVID-19 from natural language narratives using a machine learning pipeline.
Supervised Phrase-boundary Embeddings
Feb 15, 2020
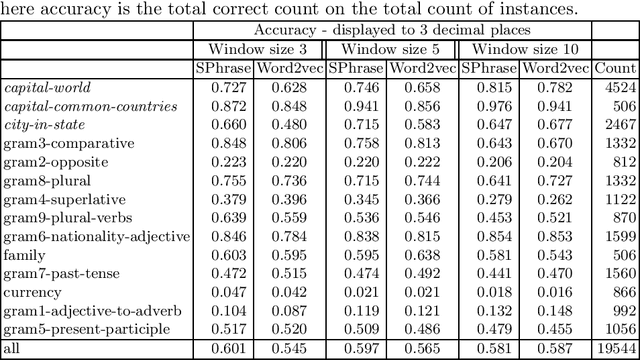

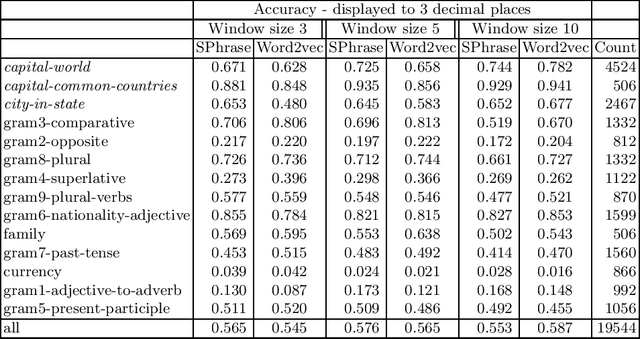
We propose a new word embedding model, called SPhrase, that incorporates supervised phrase information. Our method modifies traditional word embeddings by ensuring that all target words in a phrase have exactly the same context. We demonstrate that including this information within a context window produces superior embeddings for both intrinsic evaluation tasks and downstream extrinsic tasks.
Market Trend Prediction using Sentiment Analysis: Lessons Learned and Paths Forward
Mar 13, 2019
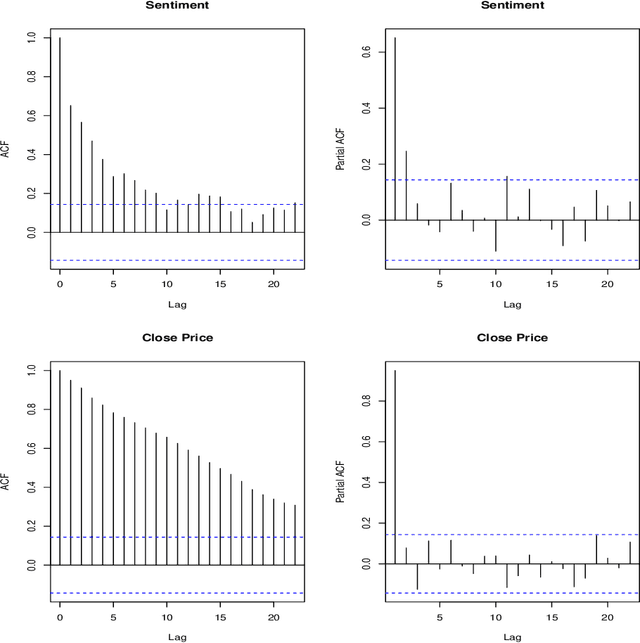
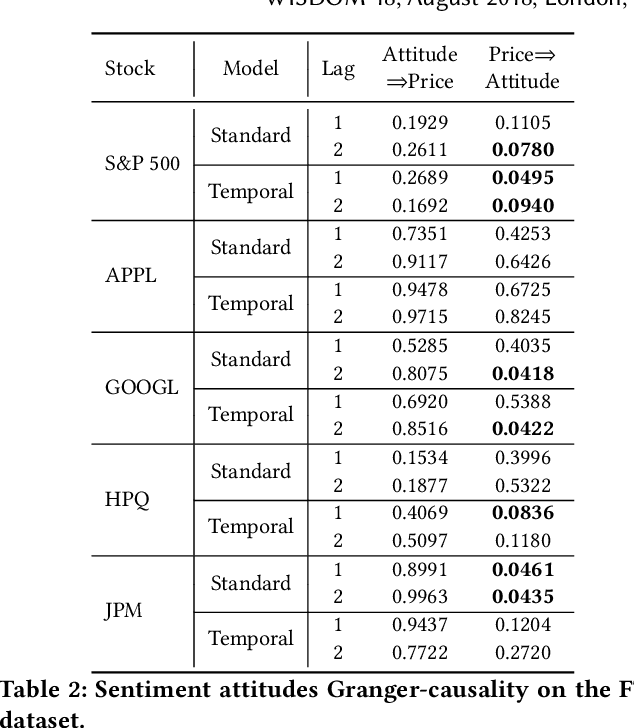

Financial market forecasting is one of the most attractive practical applications of sentiment analysis. In this paper, we investigate the potential of using sentiment \emph{attitudes} (positive vs negative) and also sentiment \emph{emotions} (joy, sadness, etc.) extracted from financial news or tweets to help predict stock price movements. Our extensive experiments using the \emph{Granger-causality} test have revealed that (i) in general sentiment attitudes do not seem to Granger-cause stock price changes; and (ii) while on some specific occasions sentiment emotions do seem to Granger-cause stock price changes, the exhibited pattern is not universal and must be looked at on a case by case basis. Furthermore, it has been observed that at least for certain stocks, integrating sentiment emotions as additional features into the machine learning based market trend prediction model could improve its accuracy.
The Anatomy of a Search and Mining System for Digital Archives
Mar 23, 2016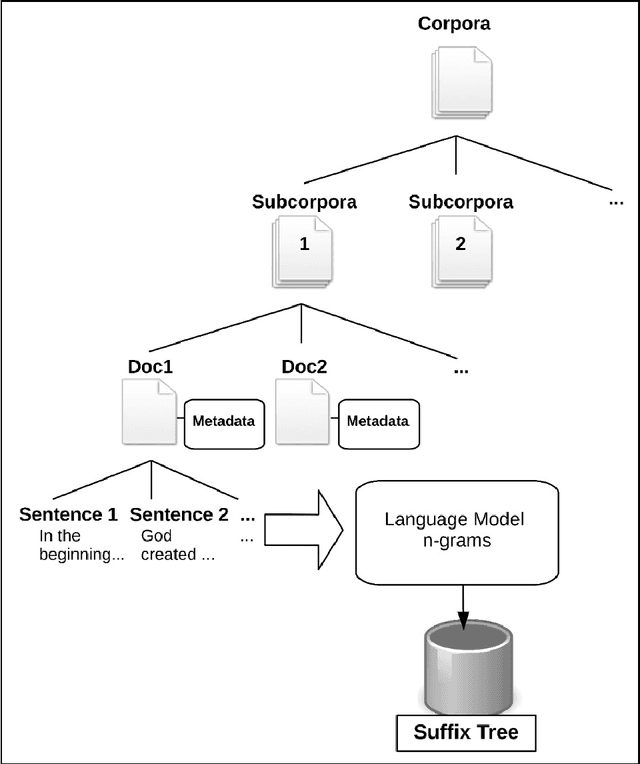

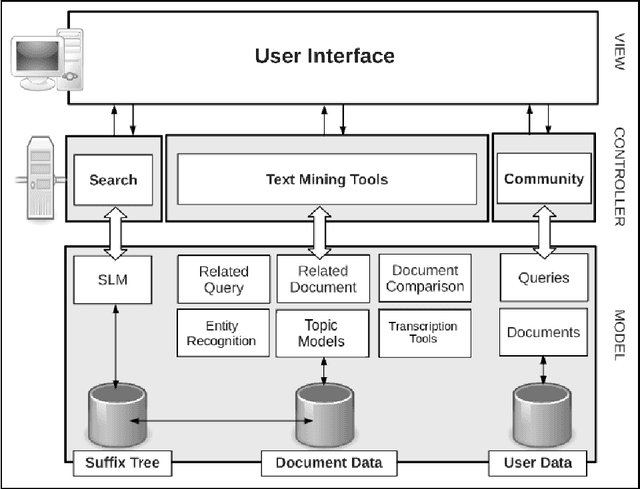
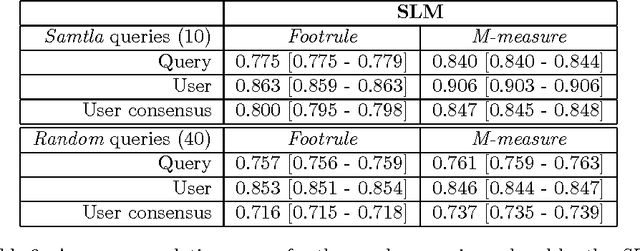
Samtla (Search And Mining Tools with Linguistic Analysis) is a digital humanities system designed in collaboration with historians and linguists to assist them with their research work in quantifying the content of any textual corpora through approximate phrase search and document comparison. The retrieval engine uses a character-based n-gram language model rather than the conventional word-based one so as to achieve great flexibility in language agnostic query processing. The index is implemented as a space-optimised character-based suffix tree with an accompanying database of document content and metadata. A number of text mining tools are integrated into the system to allow researchers to discover textual patterns, perform comparative analysis, and find out what is currently popular in the research community. Herein we describe the system architecture, user interface, models and algorithms, and data storage of the Samtla system. We also present several case studies of its usage in practice together with an evaluation of the systems' ranking performance through crowdsourcing.
A Discrete Evolutionary Model for Chess Players' Ratings
Mar 30, 2011

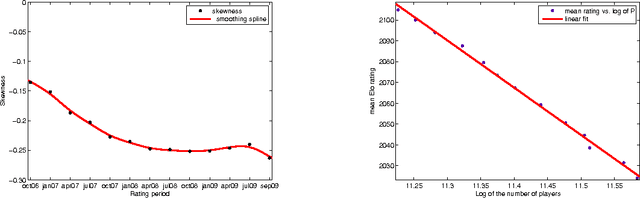
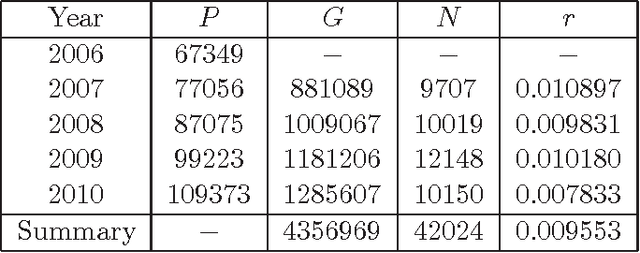
The Elo system for rating chess players, also used in other games and sports, was adopted by the World Chess Federation over four decades ago. Although not without controversy, it is accepted as generally reliable and provides a method for assessing players' strengths and ranking them in official tournaments. It is generally accepted that the distribution of players' rating data is approximately normal but, to date, no stochastic model of how the distribution might have arisen has been proposed. We propose such an evolutionary stochastic model, which models the arrival of players into the rating pool, the games they play against each other, and how the results of these games affect their ratings. Using a continuous approximation to the discrete model, we derive the distribution for players' ratings at time $t$ as a normal distribution, where the variance increases in time as a logarithmic function of $t$. We validate the model using published rating data from 2007 to 2010, showing that the parameters obtained from the data can be recovered through simulations of the stochastic model. The distribution of players' ratings is only approximately normal and has been shown to have a small negative skew. We show how to modify our evolutionary stochastic model to take this skewness into account, and we validate the modified model using the published official rating data.
A Methodology for Learning Players' Styles from Game Records
Apr 16, 2009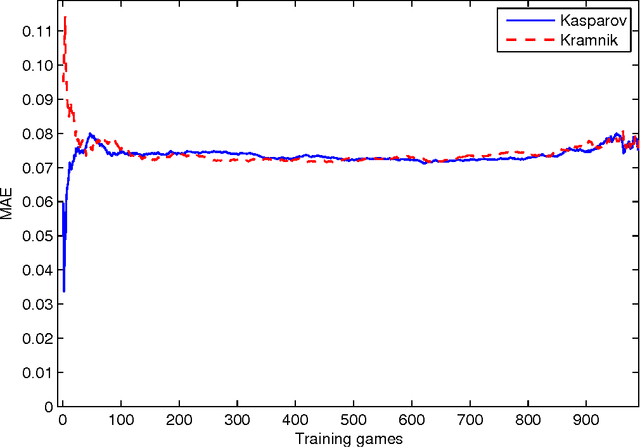
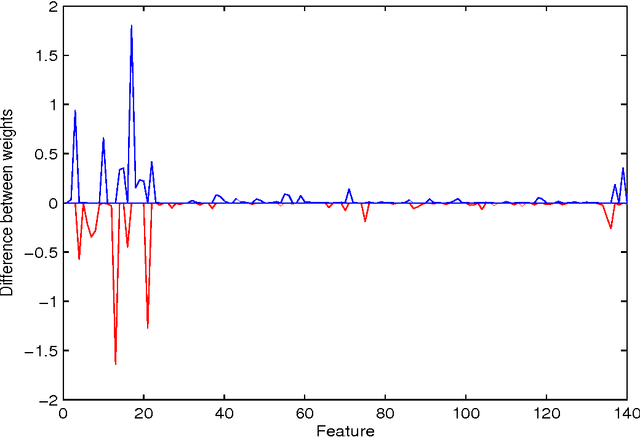
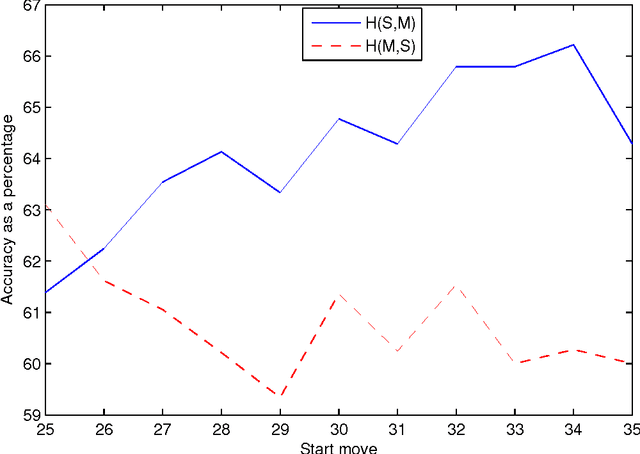
We describe a preliminary investigation into learning a Chess player's style from game records. The method is based on attempting to learn features of a player's individual evaluation function using the method of temporal differences, with the aid of a conventional Chess engine architecture. Some encouraging results were obtained in learning the styles of two recent Chess world champions, and we report on our attempt to use the learnt styles to discriminate between the players from game records by trying to detect who was playing white and who was playing black. We also discuss some limitations of our approach and propose possible directions for future research. The method we have presented may also be applicable to other strategic games, and may even be generalisable to other domains where sequences of agents' actions are recorded.
Comparing Typical Opening Move Choices Made by Humans and Chess Engines
Oct 11, 2006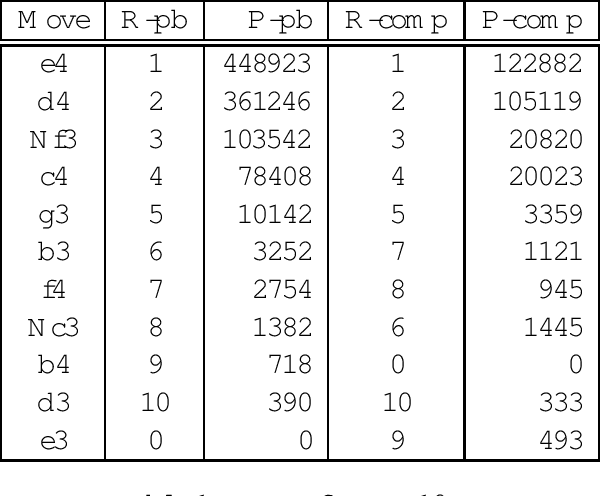
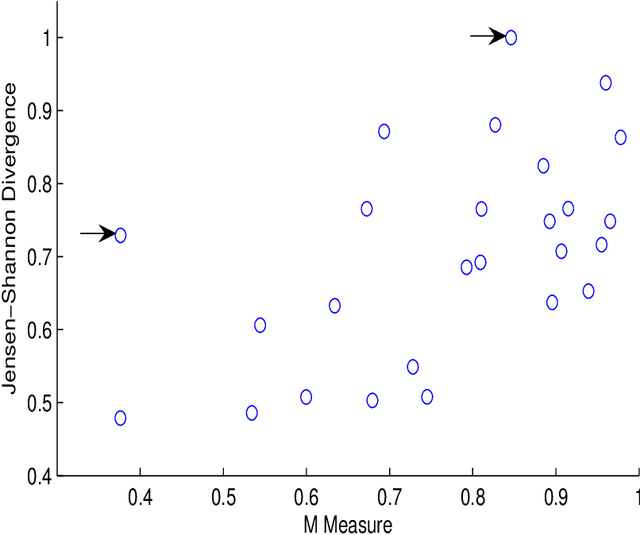
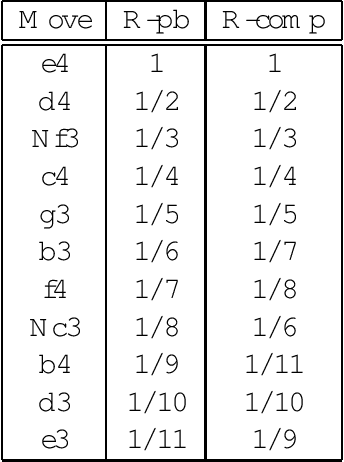
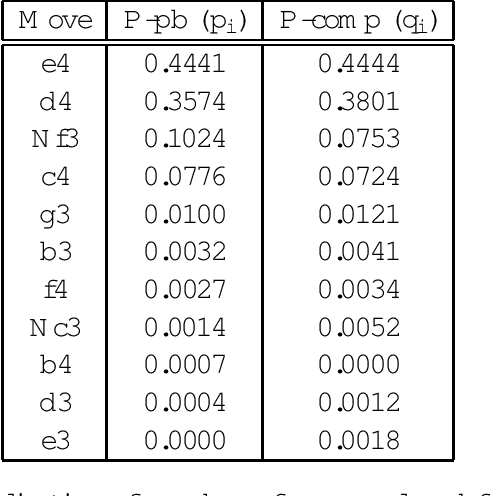
The opening book is an important component of a chess engine, and thus computer chess programmers have been developing automated methods to improve the quality of their books. For chess, which has a very rich opening theory, large databases of high-quality games can be used as the basis of an opening book, from which statistics relating to move choices from given positions can be collected. In order to find out whether the opening books used by modern chess engines in machine versus machine competitions are ``comparable'' to those used by chess players in human versus human competitions, we carried out analysis on 26 test positions using statistics from two opening books one compiled from humans' games and the other from machines' games. Our analysis using several nonparametric measures, shows that, overall, there is a strong association between humans' and machines' choices of opening moves when using a book to guide their choices.
Evaluating Variable Length Markov Chain Models for Analysis of User Web Navigation Sessions
Jun 28, 2006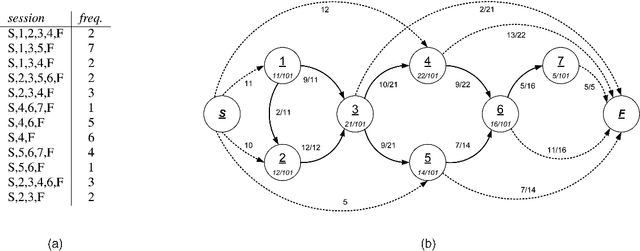
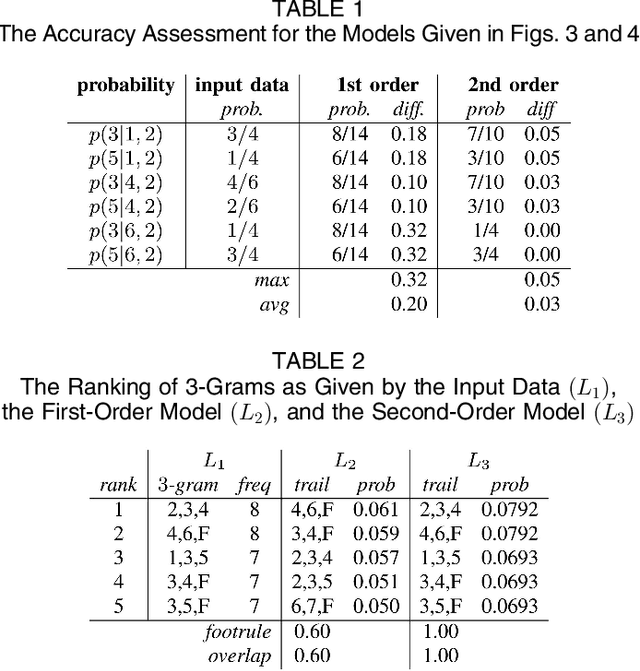
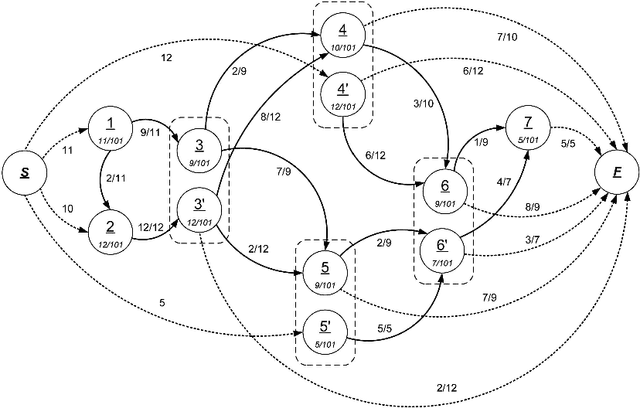
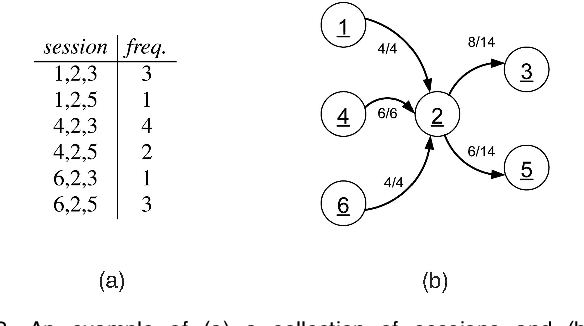
Markov models have been widely used to represent and analyse user web navigation data. In previous work we have proposed a method to dynamically extend the order of a Markov chain model and a complimentary method for assessing the predictive power of such a variable length Markov chain. Herein, we review these two methods and propose a novel method for measuring the ability of a variable length Markov model to summarise user web navigation sessions up to a given length. While the summarisation ability of a model is important to enable the identification of user navigation patterns, the ability to make predictions is important in order to foresee the next link choice of a user after following a given trail so as, for example, to personalise a web site. We present an extensive experimental evaluation providing strong evidence that prediction accuracy increases linearly with summarisation ability.