 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Artificial Intelligence in the Context of Metrology
Jun 14, 2024We review research at the National Physical Laboratory (NPL) in the area of trustworthy artificial intelligence (TAI), and more specifically trustworthy machine learning (TML), in the context of metrology, the science of measurement. We describe three broad themes of TAI: technical, socio-technical and social, which play key roles in ensuring that the developed models are trustworthy and can be relied upon to make responsible decisions. From a metrology perspective we emphasise uncertainty quantification (UQ), and its importance within the framework of TAI to enhance transparency and trust in the outputs of AI systems. We then discuss three research areas within TAI that we are working on at NPL, and examine the certification of AI systems in terms of adherence to the characteristics of TAI.
Getting a CLUE: A Method for Explaining Uncertainty Estimates
Jun 11, 2020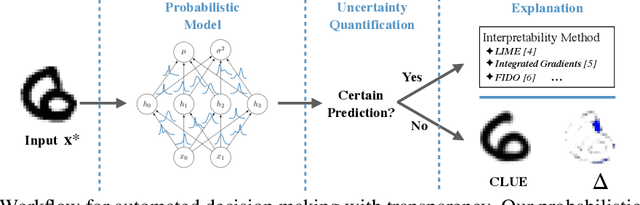
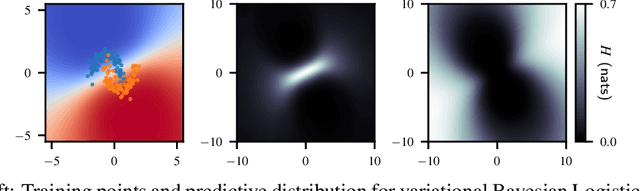


Both uncertainty estimation and interpretability are important factors for trustworthy machine learning systems. However, there is little work at the intersection of these two areas. We address this gap by proposing a novel method for interpreting uncertainty estimates from differentiable probabilistic models, like Bayesian Neural Networks (BNNs). Our method, Counterfactual Latent Uncertainty Explanations (CLUE), indicates how to change an input, while keeping it on the data manifold, such that a BNN becomes more confident about the input's prediction. We validate CLUE through 1) a novel framework for evaluating counterfactual explanations of uncertainty, 2) a series of ablation experiments, and 3) a user study. Our experiments show that CLUE outperforms baselines and enables practitioners to better understand which input patterns are responsible for predictive uncertainty.
Continual Learning with Adaptive Weights (CLAW)
Nov 21, 2019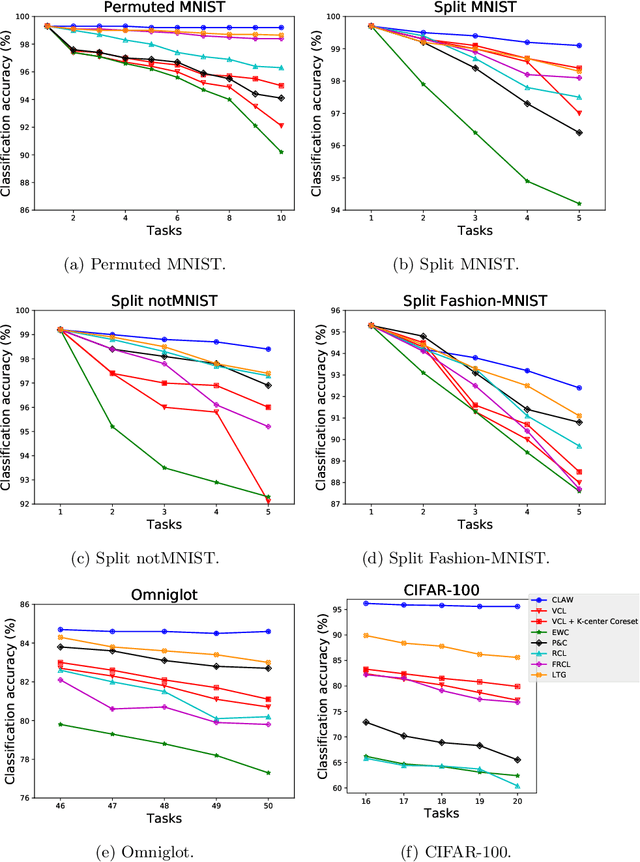
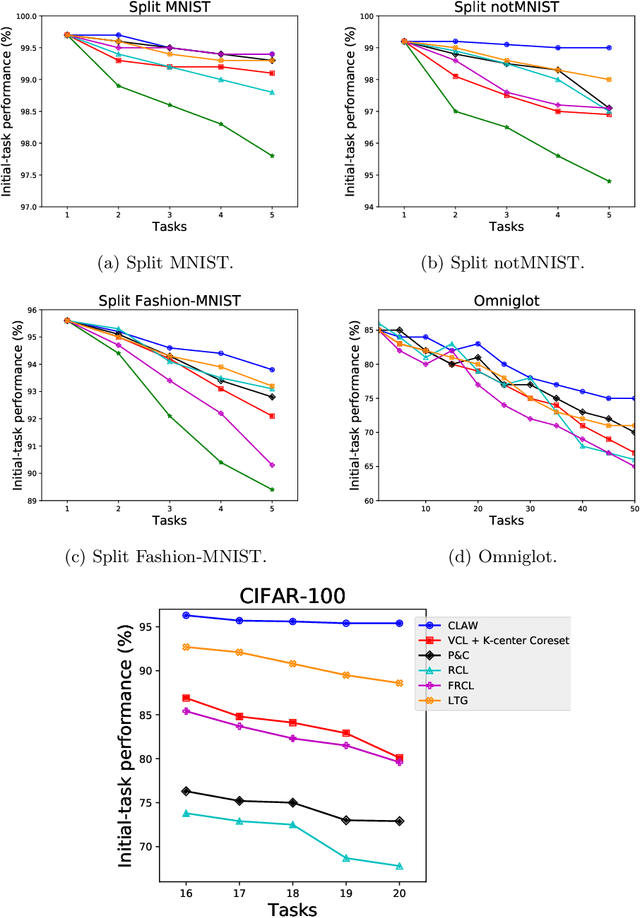
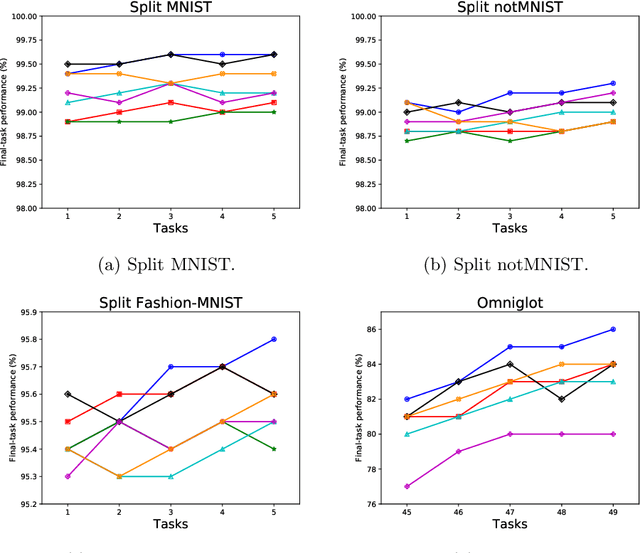
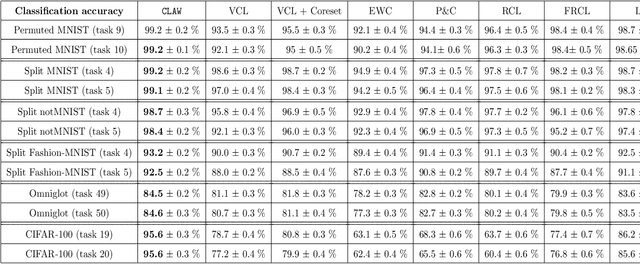
Approaches to continual learning aim to successfully learn a set of related tasks that arrive in an online manner. Recently, several frameworks have been developed which enable deep learning to be deployed in this learning scenario. A key modelling decision is to what extent the architecture should be shared across tasks. On the one hand, separately modelling each task avoids catastrophic forgetting but it does not support transfer learning and leads to large models. On the other hand, rigidly specifying a shared component and a task-specific part enables task transfer and limits the model size, but it is vulnerable to catastrophic forgetting and restricts the form of task-transfer that can occur. Ideally, the network should adaptively identify which parts of the network to share in a data driven way. Here we introduce such an approach called Continual Learning with Adaptive Weights (CLAW), which is based on probabilistic modelling and variational inference. Experiments show that CLAW achieves state-of-the-art performance on six benchmarks in terms of overall continual learning performance, as measured by classification accuracy, and in terms of addressing catastrophic forgetting.
Conditional Learning of Fair Representations
Oct 16, 2019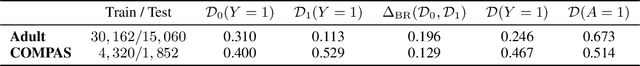

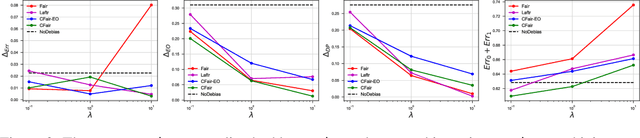

We propose a novel algorithm for learning fair representations that can simultaneously mitigate two notions of disparity among different demographic subgroups. Two key components underpinning the design of our algorithm are balanced error rate and conditional alignment of representations. We show how these two components contribute to ensuring accuracy parity and equalized false-positive and false-negative rates across groups without impacting demographic parity. Furthermore, we also demonstrate both in theory and on two real-world experiments that the proposed algorithm leads to a better utility-fairness trade-off on balanced datasets compared with existing algorithms on learning fair representations.
Visualizing Deep Neural Network Decisions: Prediction Difference Analysis
Feb 15, 2017


This article presents the prediction difference analysis method for visualizing the response of a deep neural network to a specific input. When classifying images, the method highlights areas in a given input image that provide evidence for or against a certain class. It overcomes several shortcoming of previous methods and provides great additional insight into the decision making process of classifiers. Making neural network decisions interpretable through visualization is important both to improve models and to accelerate the adoption of black-box classifiers in application areas such as medicine. We illustrate the method in experiments on natural images (ImageNet data), as well as medical images (MRI brain scans).
Learning Bayesian Networks with Incomplete Data by Augmentation
Oct 09, 2016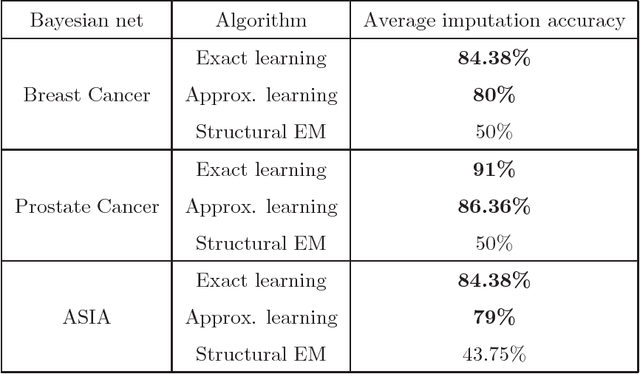
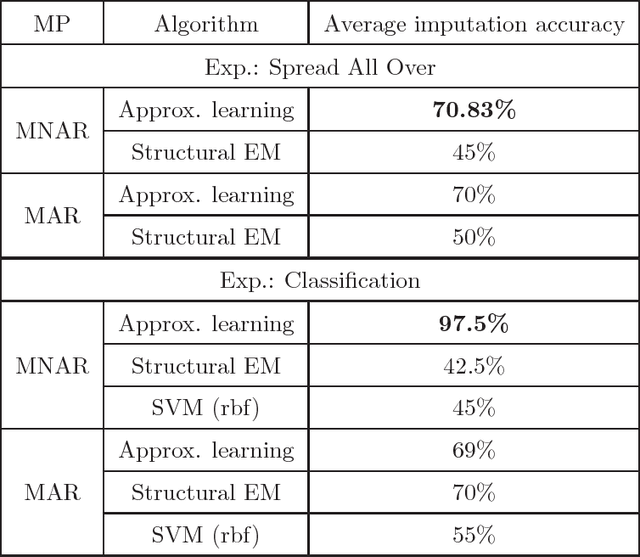
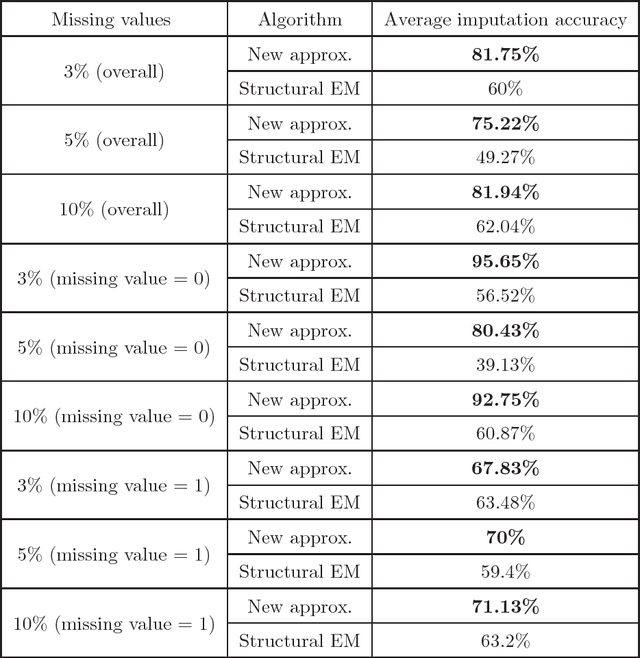
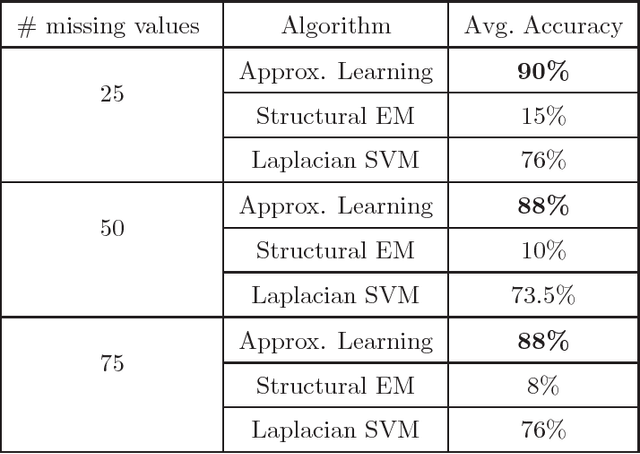
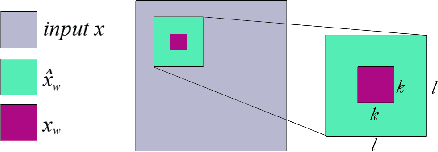
We present new algorithms for learning Bayesian networks from data with missing values using a data augmentation approach. An exact Bayesian network learning algorithm is obtained by recasting the problem into a standard Bayesian network learning problem without missing data. To the best of our knowledge, this is the first exact algorithm for this problem. As expected, the exact algorithm does not scale to large domains. We build on the exact method to create an approximate algorithm using a hill-climbing technique. This algorithm scales to large domains so long as a suitable standard structure learning method for complete data is available. We perform a wide range of experiments to demonstrate the benefits of learning Bayesian networks with such new approach.
Automatic Variational ABC
Jun 28, 2016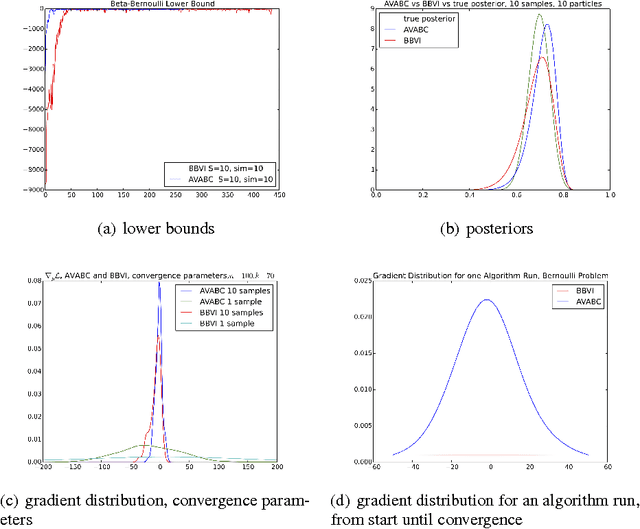
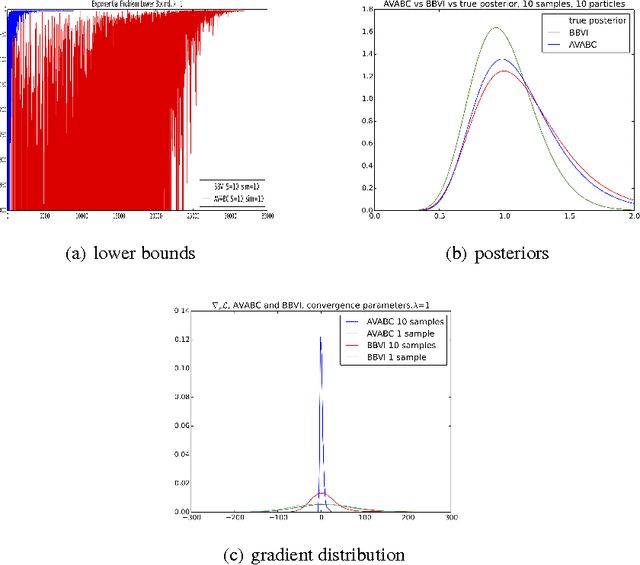
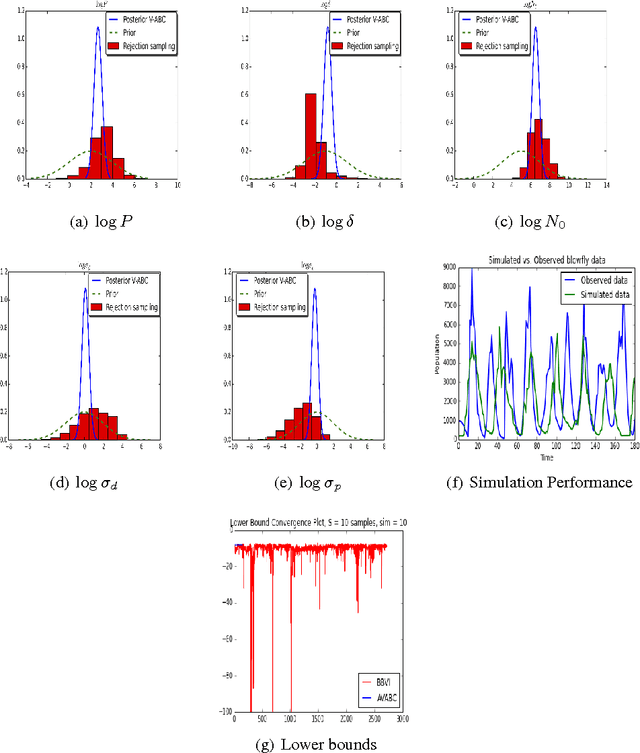
Approximate Bayesian Computation (ABC) is a framework for performing likelihood-free posterior inference for simulation models. Stochastic Variational inference (SVI) is an appealing alternative to the inefficient sampling approaches commonly used in ABC. However, SVI is highly sensitive to the variance of the gradient estimators, and this problem is exacerbated by approximating the likelihood. We draw upon recent advances in variance reduction for SV and likelihood-free inference using deterministic simulations to produce low variance gradient estimators of the variational lower-bound. By then exploiting automatic differentiation libraries we can avoid nearly all model-specific derivations. We demonstrate performance on three problems and compare to existing SVI algorithms. Our results demonstrate the correctness and efficiency of our algorithm.
A Weakly Supervised Learning Approach based on Spectral Graph-Theoretic Grouping
Aug 03, 2015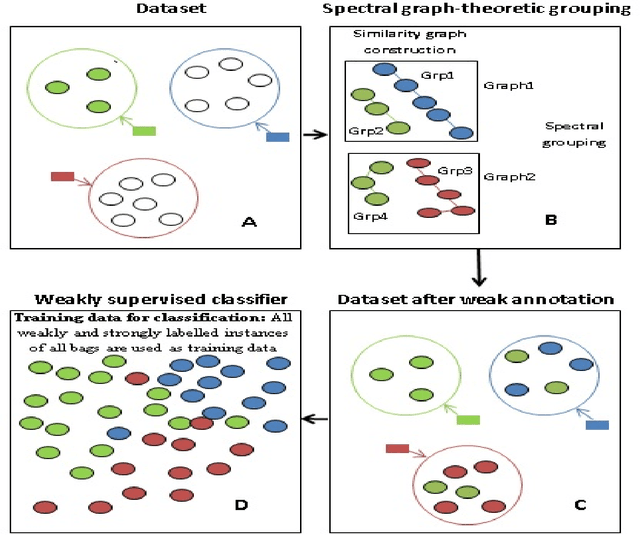
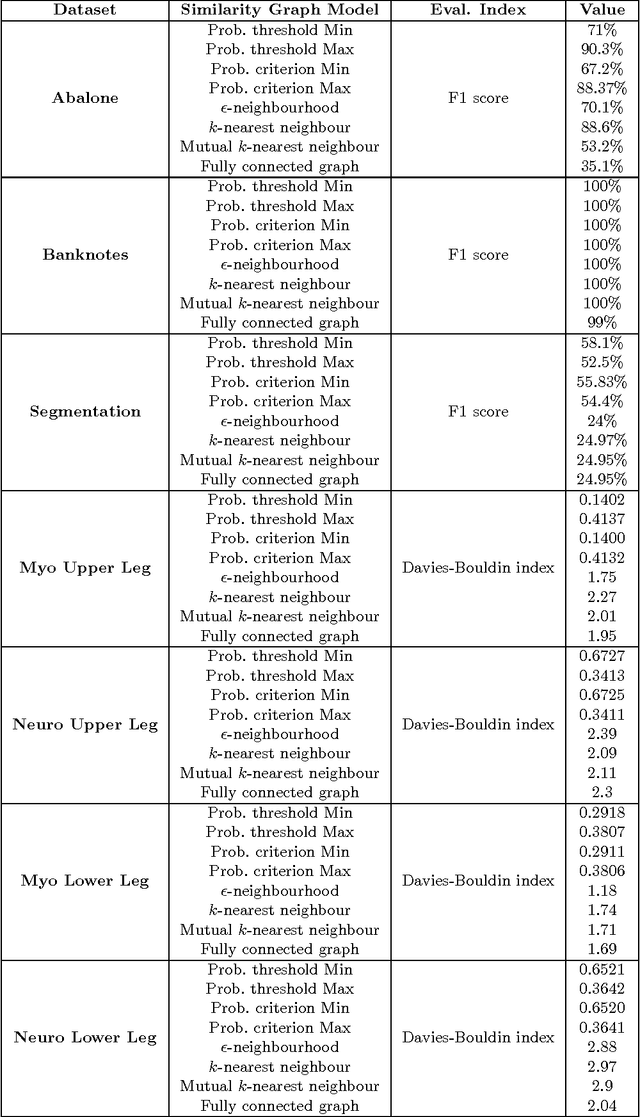
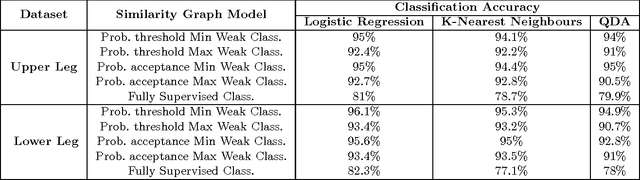
In this study, a spectral graph-theoretic grouping strategy for weakly supervised classification is introduced, where a limited number of labelled samples and a larger set of unlabelled samples are used to construct a larger annotated training set composed of strongly labelled and weakly labelled samples. The inherent relationship between the set of strongly labelled samples and the set of unlabelled samples is established via spectral grouping, with the unlabelled samples subsequently weakly annotated based on the strongly labelled samples within the associated spectral groups. A number of similarity graph models for spectral grouping, including two new similarity graph models introduced in this study, are explored to investigate their performance in the context of weakly supervised classification in handling different types of data. Experimental results using benchmark datasets as well as real EMG datasets demonstrate that the proposed approach to weakly supervised classification can provide noticeable improvements in classification performance, and that the proposed similarity graph models can lead to ultimate learning results that are either better than or on a par with existing similarity graph models in the context of spectral grouping for weakly supervised classification.
Generative Multiple-Instance Learning Models For Quantitative Electromyography
Sep 26, 2013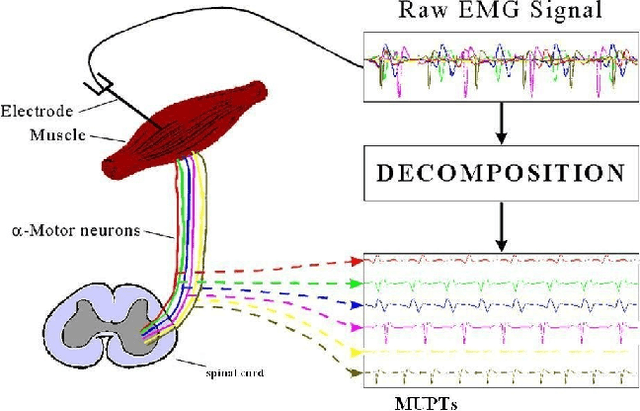
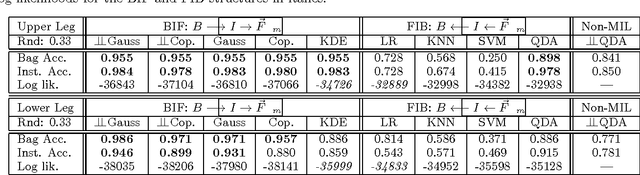
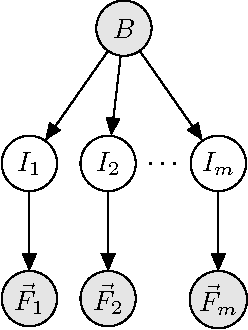
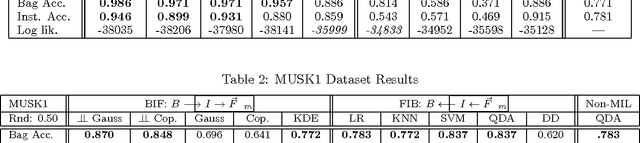
We present a comprehensive study of the use of generative modeling approaches for Multiple-Instance Learning (MIL) problems. In MIL a learner receives training instances grouped together into bags with labels for the bags only (which might not be correct for the comprised instances). Our work was motivated by the task of facilitating the diagnosis of neuromuscular disorders using sets of motor unit potential trains (MUPTs) detected within a muscle which can be cast as a MIL problem. Our approach leads to a state-of-the-art solution to the problem of muscle classification. By introducing and analyzing generative models for MIL in a general framework and examining a variety of model structures and components, our work also serves as a methodological guide to modelling MIL tasks. We evaluate our proposed methods both on MUPT datasets and on the MUSK1 dataset, one of the most widely used benchmarks for MIL.