 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards understanding the bias in decision trees
Jan 09, 2025



There is a widespread and longstanding belief that machine learning models are biased towards the majority (or negative) class when learning from imbalanced data, leading them to neglect or ignore the minority (or positive) class. In this study, we show that this belief is not necessarily correct for decision trees, and that their bias can actually be in the opposite direction. Motivated by a recent simulation study that suggested that decision trees can be biased towards the minority class, our paper aims to reconcile the conflict between that study and decades of other works. First, we critically evaluate past literature on this problem, finding that failing to consider the data generating process has led to incorrect conclusions about the bias in decision trees. We then prove that, under specific conditions related to the predictors, decision trees fit to purity and trained on a dataset with only one positive case are biased towards the minority class. Finally, we demonstrate that splits in a decision tree are also biased when there is more than one positive case. Our findings have implications on the use of popular tree-based models, such as random forests.
Challenges learning from imbalanced data using tree-based models: Prevalence estimates systematically depend on hyperparameters and can be upwardly biased
Dec 17, 2024



Imbalanced binary classification problems arise in many fields of study. When using machine learning models for these problems, it is common to subsample the majority class (i.e., undersampling) to create a (more) balanced dataset for model training. This biases the model's predictions because the model learns from a dataset that does not follow the same data generating process as new data. One way of accounting for this bias is to analytically map the resulting predictions to new values based on the sampling rate for the majority class, which was used to create the training dataset. While this approach may work well for some machine learning models, we have found that calibrating a random forest this way has unintended negative consequences, including prevalence estimates that can be upwardly biased. These prevalence estimates depend on both i) the number of predictors considered at each split in the random forest; and ii) the sampling rate used. We explain the former using known properties of random forests and analytical calibration. However, in investigating the latter issue, we made a surprising discovery - contrary to the widespread belief that decision trees are biased towards the majority class, they actually can be biased towards the minority class.
Using Platt's scaling for calibration after undersampling -- limitations and how to address them
Oct 22, 2024When modelling data where the response is dichotomous and highly imbalanced, response-based sampling where a subset of the majority class is retained (i.e., undersampling) is often used to create more balanced training datasets prior to modelling. However, the models fit to this undersampled data, which we refer to as base models, generate predictions that are severely biased. There are several calibration methods that can be used to combat this bias, one of which is Platt's scaling. Here, a logistic regression model is used to model the relationship between the base model's original predictions and the response. Despite its popularity for calibrating models after undersampling, Platt's scaling was not designed for this purpose. Our work presents what we believe is the first detailed study focused on the validity of using Platt's scaling to calibrate models after undersampling. We show analytically, as well as via a simulation study and a case study, that Platt's scaling should not be used for calibration after undersampling without critical thought. If Platt's scaling would have been able to successfully calibrate the base model had it been trained on the entire dataset (i.e., without undersampling), then Platt's scaling might be appropriate for calibration after undersampling. If this is not the case, we recommend a modified version of Platt's scaling that fits a logistic generalized additive model to the logit of the base model's predictions, as it is both theoretically motivated and performed well across the settings considered in our study.
Reinforcement learning in large, structured action spaces: A simulation study of decision support for spinal cord injury rehabilitation
Oct 23, 2023



Reinforcement learning (RL) has helped improve decision-making in several applications. However, applying traditional RL is challenging in some applications, such as rehabilitation of people with a spinal cord injury (SCI). Among other factors, using RL in this domain is difficult because there are many possible treatments (i.e., large action space) and few patients (i.e., limited training data). Treatments for SCIs have natural groupings, so we propose two approaches to grouping treatments so that an RL agent can learn effectively from limited data. One relies on domain knowledge of SCI rehabilitation and the other learns similarities among treatments using an embedding technique. We then use Fitted Q Iteration to train an agent that learns optimal treatments. Through a simulation study designed to reflect the properties of SCI rehabilitation, we find that both methods can help improve the treatment decisions of physiotherapists, but the approach based on domain knowledge offers better performance. Our findings provide a "proof of concept" that RL can be used to help improve the treatment of those with an SCI and indicates that continued efforts to gather data and apply RL to this domain are worthwhile.
Hybrid Feature- and Similarity-Based Models for Prediction and Interpretation using Large-Scale Observational Data
Apr 12, 2022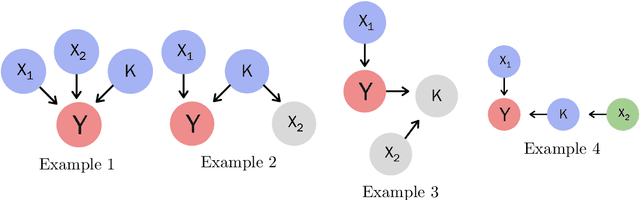
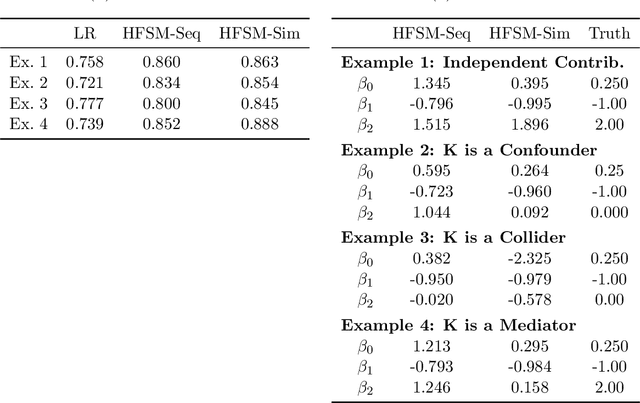
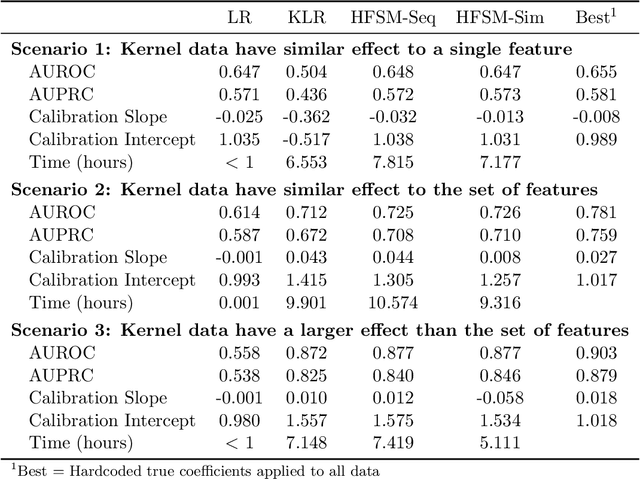
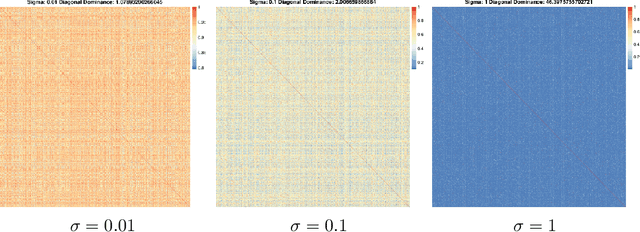
Introduction: Large-scale electronic health record(EHR) datasets often include simple informative features like patient age and complex data like care history that are not easily represented as individual features. Such complex data have the potential to both improve the quality of risk assessment and to enable a better understanding of causal factors leading to those risks. We propose a hybrid feature- and similarity-based model for supervised learning that combines feature and kernel learning approaches to take advantage of rich but heterogeneous observational data sources to create interpretable models for prediction and for investigation of causal relationships. Methods: The proposed hybrid model is fit by convex optimization with a sparsity-inducing penalty on the kernel portion. Feature and kernel coefficients can be fit sequentially or simultaneously. We compared our models to solely feature- and similarity-based approaches using synthetic data and using EHR data from a primary health care organization to predict risk of loneliness or social isolation. We also present a new strategy for kernel construction that is suited to high-dimensional indicator-coded EHR data. Results: The hybrid models had comparable or better predictive performance than the feature- and kernel-based approaches in both the synthetic and clinical case studies. The inherent interpretability of the hybrid model is used to explore client characteristics stratified by kernel coefficient direction in the clinical case study; we use simple examples to discuss opportunities and cautions of the two hybrid model forms when causal interpretations are desired. Conclusion: Hybrid feature- and similarity-based models provide an opportunity to capture complex, high-dimensional data within an additive model structure that supports improved prediction and interpretation relative to simple models and opaque complex models.
Decision-Directed Data Decomposition
Sep 18, 2019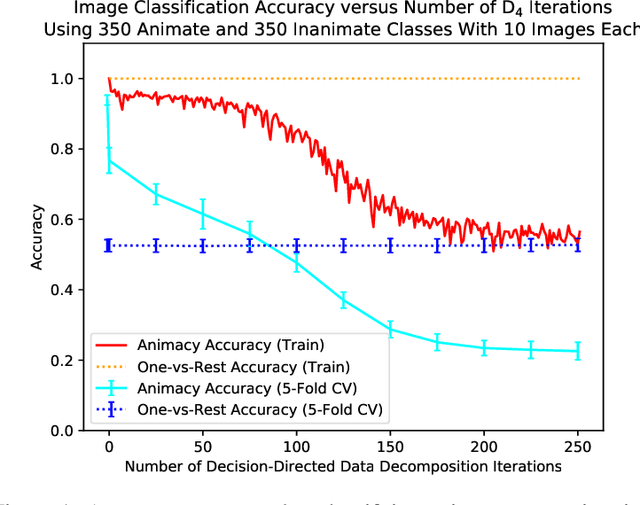

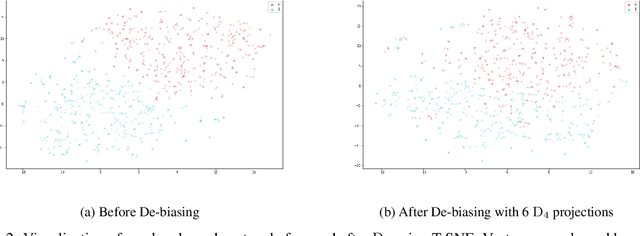
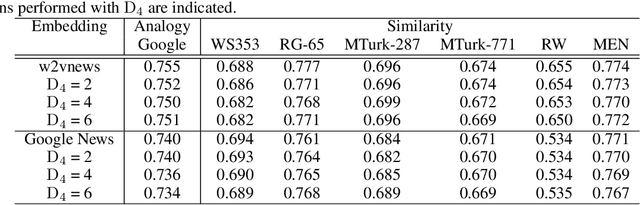
We present an algorithm, Decision-Directed Data Decomposition, which decomposes a dataset into two components. The first contains most of the useful information for a specified supervised learning task, and the second orthogonal component that contains little information about the task. The algorithm is simple and scalable. It can use kernel techniques to help preserve desirable information in the decomposition. We illustrate its application to tasks in two domains, using distributed representations of words and images, and we report state-of-the-art results showcasing $D_4$'s capability to remove information pertaining to gender from word embeddings.
On Prediction and Tolerance Intervals for Dynamic Treatment Regimes
Apr 24, 2017
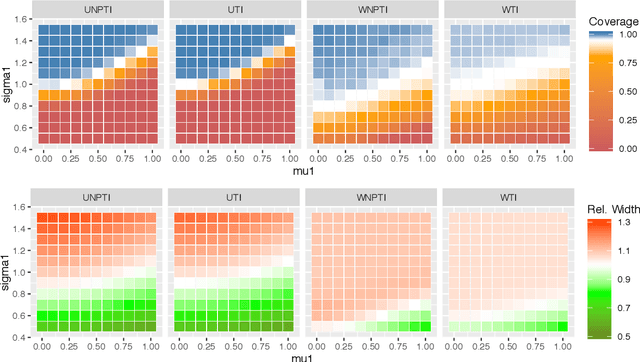
We develop and evaluate tolerance interval methods for dynamic treatment regimes (DTRs) that can provide more detailed prognostic information to patients who will follow an estimated optimal regime. Although the problem of constructing confidence intervals for DTRs has been extensively studied, prediction and tolerance intervals have received little attention. We begin by reviewing in detail different interval estimation and prediction methods and then adapting them to the DTR setting. We illustrate some of the challenges associated with tolerance interval estimation stemming from the fact that we do not typically have data that were generated from the estimated optimal regime. We give an extensive empirical evaluation of the methods and discussed several practical aspects of method choice, and we present an example application using data from a clinical trial. Finally, we discuss future directions within this important emerging area of DTR research.
gLOP: the global and Local Penalty for Capturing Predictive Heterogeneity
Jul 29, 2016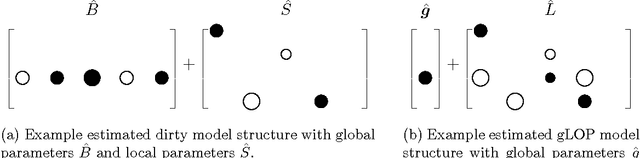
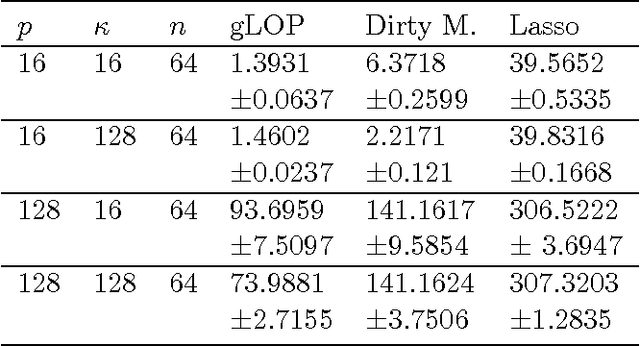
When faced with a supervised learning problem, we hope to have rich enough data to build a model that predicts future instances well. However, in practice, problems can exhibit predictive heterogeneity: most instances might be relatively easy to predict, while others might be predictive outliers for which a model trained on the entire dataset does not perform well. Identifying these can help focus future data collection. We present gLOP, the global and Local Penalty, a framework for capturing predictive heterogeneity and identifying predictive outliers. gLOP is based on penalized regression for multitask learning, which improves learning by leveraging training signal information from related tasks. We give two optimization algorithms for gLOP, one space-efficient, and another giving the full regularization path. We also characterize uniqueness in terms of the data and tuning parameters, and present empirical results on synthetic data and on two health research problems.
Generative Multiple-Instance Learning Models For Quantitative Electromyography
Sep 26, 2013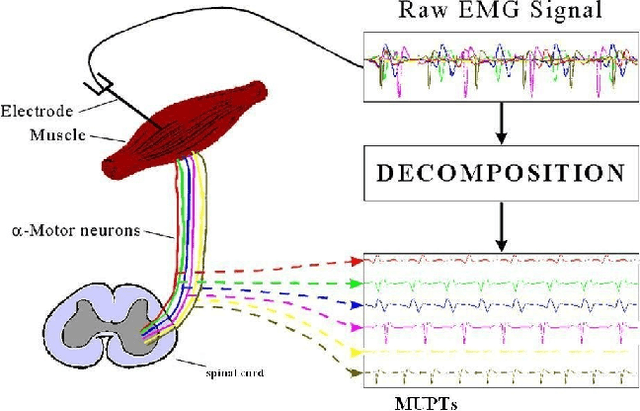
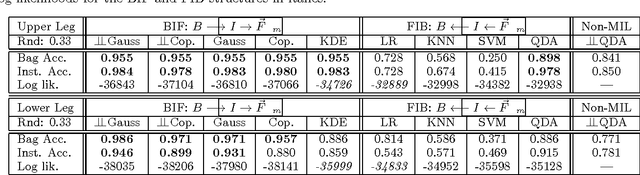
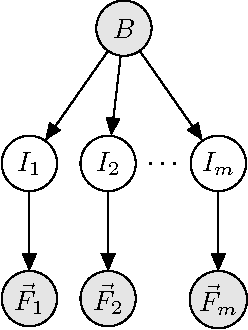
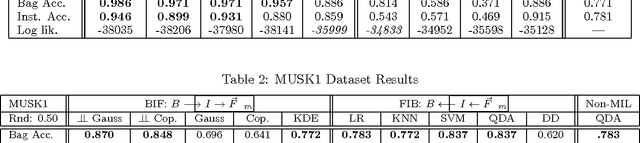
We present a comprehensive study of the use of generative modeling approaches for Multiple-Instance Learning (MIL) problems. In MIL a learner receives training instances grouped together into bags with labels for the bags only (which might not be correct for the comprised instances). Our work was motivated by the task of facilitating the diagnosis of neuromuscular disorders using sets of motor unit potential trains (MUPTs) detected within a muscle which can be cast as a MIL problem. Our approach leads to a state-of-the-art solution to the problem of muscle classification. By introducing and analyzing generative models for MIL in a general framework and examining a variety of model structures and components, our work also serves as a methodological guide to modelling MIL tasks. We evaluate our proposed methods both on MUPT datasets and on the MUSK1 dataset, one of the most widely used benchmarks for MIL.
Budgeted Learning of Naive-Bayes Classifiers
Oct 19, 2012

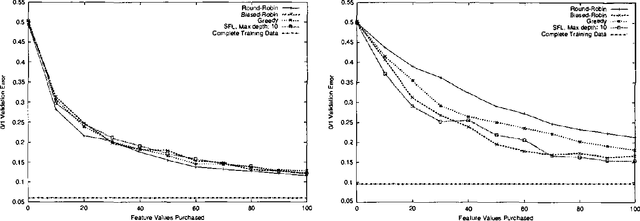
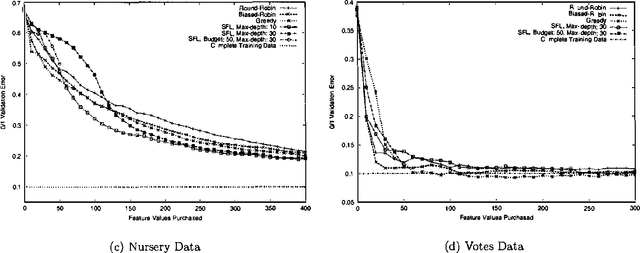
Frequently, acquiring training data has an associated cost. We consider the situation where the learner may purchase data during training, subject TO a budget. IN particular, we examine the CASE WHERE each feature label has an associated cost, AND the total cost OF ALL feature labels acquired during training must NOT exceed the budget.This paper compares methods FOR choosing which feature label TO purchase next, given the budget AND the CURRENT belief state OF naive Bayes model parameters.Whereas active learning has traditionally focused ON myopic(greedy) strategies FOR query selection, this paper presents a tractable method FOR incorporating knowledge OF the budget INTO the decision making process, which improves performance.